Today, our CEO, @premakkaraju, announced that legendary filmmaker, technology innovator, and visual effects pioneer, James Cameron, has joined the Stability AI Board of Directors.
Cameron’s addition represents a significant step forward in our mission to transform visual media.… pic.twitter.com/UCirE4WTUs
こんにちは!Stability AI の生成メディアソリューションエンジニア(およびフリーランスの 2D/3D コンセプトデザイナー)の Yeo Wang です。YouTube で私のビデオを見たことがあるかもしれませんし、コミュニティ(Github)を通じて私を知っているかもしれません。個人的には、SD3 Medium をトレーニングしたときにまともな結果が得られたので、完全なファインチューニングと LoRA トレーニングの両方について、いくつかの洞察とクイックスタート構成を共有します。
In addition, there is a repeats parameter that you may or may not be familiar with depending on whether or not you’ve used other training repositories before. repeats duplicates your images (and optionally rotates, changes the color, etc.) and captions as well to help generalize the style into the model and prevent overfitting. While SimpleTuner supports caption dropout (randomly dropping captions a specified percentage of the time),it doesn’t support shuffling tokens (tokens are kind of like words in the caption) as of this moment, but you can simulate the behavior of kohya’s sd-scripts where you can shuffle tokens while keeping an n amount of tokens. If you’d like to replicate that, I’ve provided a script here that will duplicate the images and manipulate the captions: さらに、以前に他のトレーニングリポジトリを使ったことがあるかどうかによって、馴染みがあるかどうかが分かれるかもしれないrepeatsパラメータがあります。repeatsは、モデルにスタイルを一般化し、オーバーフィッティングを防ぐために、画像(オプションで回転、色の変更など)とキャプションを複製します。SimpleTunerはキャプションのドロップアウト(指定した割合でランダムにキャプションをドロップする)をサポートしていますが、現時点ではトークン(トークンはキャプションの単語のようなもの)のシャッフルはサポートしていません:
import os
import shutil
import random
from pathlib import Path
import re
def duplicate_and_shuffle_dataset(input_folder, output_folder, dataset_repeats, n_tokens_to_keep):
# Create output folder if it doesn't exist
Path(output_folder).mkdir(parents=True, exist_ok=True)
# Get all image files
image_files = [f for f in os.listdir(input_folder) if f.lower().endswith(('.png', '.jpg', '.jpeg'))]
for i in range(dataset_repeats):
for image_file in image_files:
# Get corresponding text file
text_file = os.path.splitext(image_file)[0] + '.txt'
if not os.path.exists(os.path.join(input_folder, text_file)):
print(f"Warning: No corresponding text file found for {image_file}")
continue
# Create new file names
new_image_file = f"{os.path.splitext(image_file)[0]}_{i+1}{os.path.splitext(image_file)[1]}"
new_text_file = f"{os.path.splitext(text_file)[0]}_{i+1}.txt"
# Copy image file
shutil.copy2(os.path.join(input_folder, image_file), os.path.join(output_folder, new_image_file))
# Read, shuffle, and write text file
with open(os.path.join(input_folder, text_file), 'r') as f:
content = f.read().strip()
# Split tokens using comma or period as separator
tokens = re.split(r'[,.]', content)
tokens = [token.strip() for token in tokens if token.strip()] # Remove empty tokens and strip whitespace
tokens_to_keep = tokens[:n_tokens_to_keep]
tokens_to_shuffle = tokens[n_tokens_to_keep:]
random.shuffle(tokens_to_shuffle)
new_content = ', '.join(tokens_to_keep + tokens_to_shuffle)
with open(os.path.join(output_folder, new_text_file), 'w') as f:
f.write(new_content)
print(f"Dataset duplication and shuffling complete. Output saved to {output_folder}")
# Example usage
input_folder = "/weka2/home-yeo/datasets/SDXL/full_dataset_neo"
output_folder = "/weka2/home-yeo/datasets/SDXL/duplicate_shuffle_10_fantasy"
dataset_repeats = 10
n_tokens_to_keep = 2
duplicate_and_shuffle_dataset(input_folder, output_folder, dataset_repeats, n_tokens_to_keep)
ph070, A rainy urban nighttime street scene features two cars parked along the wet pavement. The primary subject is a sleek, modern silver car with streamlined curves and glistening wheels reflecting the rain-soaked road. The background includes another vehicle—a darker sedan—partially obscured. Illuminated signs with Asian characters suggest a city setting possibly in a bustling nightlife district. The style is distinctly cinematic with a futuristic, neo-noir aesthetic, characterized by moody blue tones and the reflective glow of wet surfaces. The streetlights and the occasional gleam of neon green and orange provide contrast, enhancing the dark ambiance of the city at night. The atmosphere evokes a sense of mystery and quiet anticipation, with the deserted street hinting at hidden stories or events about to unfold.
#!/bin/bash# Source directory where the models are stored
SOURCE_DIR="/admin/home-yeo/workspace/simpletuner_models/sd3_medium/full_finetune/cinema_photo/03/datasets/models"
# Target directory for symlinks
TARGET_DIR="/admin/home-yeo/workspace/ComfyUI/models/unet/simpletuner_blog_cine_photo_03"
# Iterate over each checkpoint directory
for CHECKPOINT_DIR in $(ls -d ${SOURCE_DIR}/checkpoint-*); do
# Extract the checkpoint number from the directory name
CHECKPOINT_NAME=$(basename ${CHECKPOINT_DIR})
# Define the source file path
SOURCE_FILE="${CHECKPOINT_DIR}/transformer/diffusion_pytorch_model.safetensors"
# Define the symlink name
LINK_NAME="${TARGET_DIR}/${CHECKPOINT_NAME}.safetensors"
# Check if the source file exists
if [ -f "${SOURCE_FILE}" ]; then
# Create a symlink in the target directory
ln -s "${SOURCE_FILE}" "${LINK_NAME}"
echo "Symlink created for ${CHECKPOINT_NAME}"
else
echo "File not found: ${SOURCE_FILE}"
fi
done
echo "Symlinking complete."
a close up three fourth perspective portrait view of a young woman with dark hair and dark blue eyes, looking upwards and to the left, head tilted slightly downwards and to the left, exposed forehead, wearing a nun habit with white lining, wearing a white collared shirt, barely visible ear, cropped, a dark brown background 黒髪で濃い青の瞳をした若い女性のクローズアップ三四透視図。上を見て左を向き、頭はやや下向きで左に傾いており、額は露出しています。白い裏地のついた修道服に身を包み、白い襟付きシャツを着ており、耳はかろうじて見えています。
a front wide view of a small cyberpunk city with futuristic skyscrapers with gold rooftops situated on the side of a cliff overlooking an ocean, day time view with green tones, some boats floating in the foreground on top of reflective orange water, large mechanical robot structure reaching high above the clouds in the far background, atmospheric perspective, teal sky 海を見下ろす崖の中腹に建つ、金色の屋根を持つ近未来的な高層ビルが建ち並ぶ小さなサイバーパンク都市の正面からのワイドビュー、緑を基調とした日中の眺め、反射するオレンジ色の水の上に浮かぶ手前のいくつかのボート、遠景の雲の上まで届く大きな機械仕掛けのロボット構造、大気遠近法、ティール色の空
a medium view of a city square alongside a river, two large red boats in the foreground with cargo on them, two people in a smaller boat in the bottom right cruising along, reflective dark yellow water in the river, a congregation of people walking along the street parallel to the river in the midground, a dark white palazzo building with dark white tower on the right with red tones, golden hour, red and yellow flag in the top left foreground, light blue flag with yellow accents in the right midground, aerial perspective 川沿いの広場の中景、前景に荷を載せた2隻の赤い大型ボート、右下の小さなボートに乗った2人のクルージング、反射する濃い黄色の川の水、中景に川と平行する通りを歩く人々、右手に赤を基調とした濃い白の塔を持つ濃い白のパラッツォの建物、ゴールデンタイム、左上の前景に赤と黄色の旗、右の中景に黄色のアクセントのある水色の旗、空からの視点。
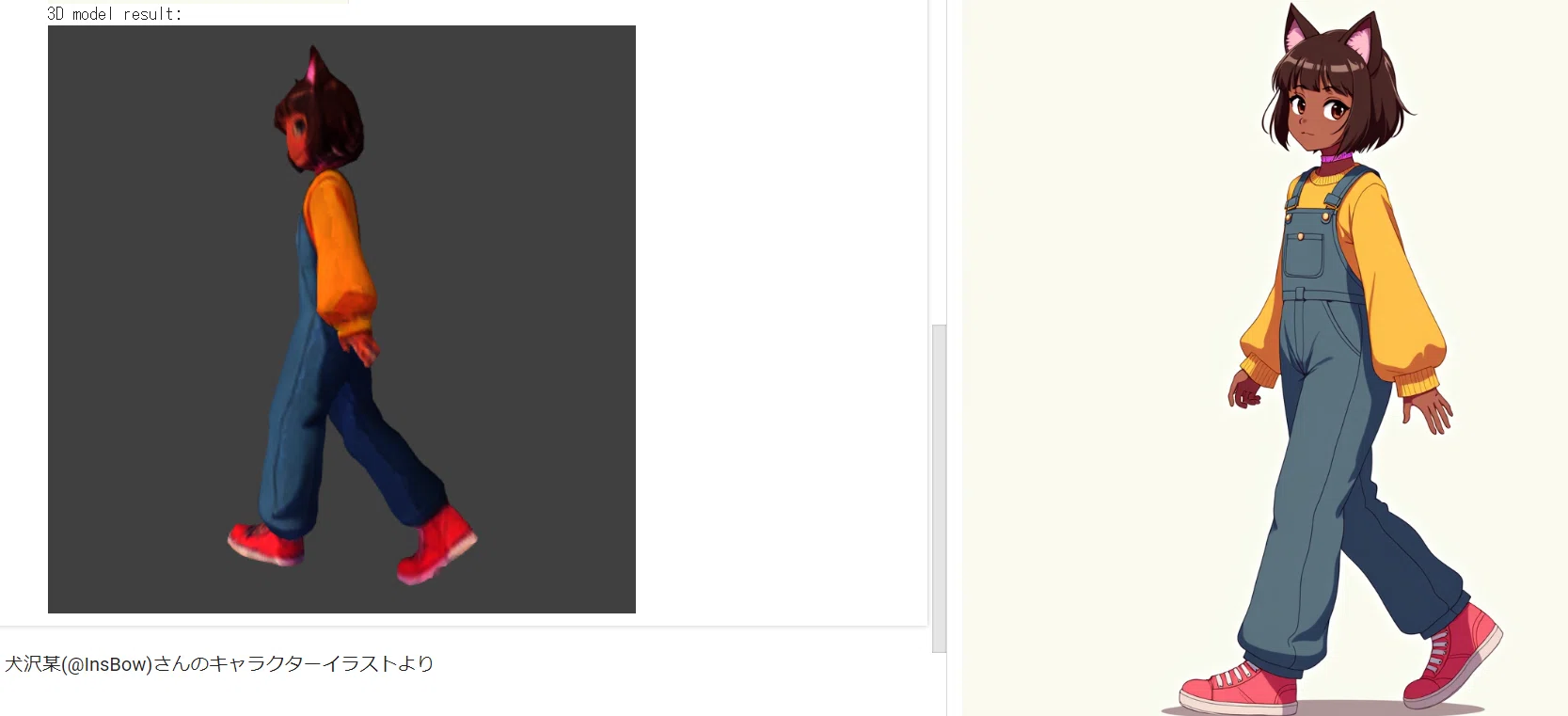
POST リクエストでエンドポイント https://api.stability.ai/v2beta/3d/stable-fast-3d を呼び出してください。 Colabのサンプルコードより
#@title Stable Fast 3D#@markdown - Drag and drop image to file folder on left#@markdown - Right click it and choose Copy path#@markdown - Paste that path into image field below#@markdown <br><br>
image = "/content/cat_statue.jpg" #@param {type:"string"}
texture_resolution = "1024" #@param ['512', '1024', '2048'] {type:"string"}
foreground_ratio = 0.85 #@param {type:"number"}
host = "https://api.stability.ai/v2beta/3d/stable-fast-3d"
response = image_to_3d(
host,
image,
texture_resolution,
foreground_ratio
)
# Save the model
filename = f"model.glb"
with open(filename, "wb") as f:
f.write(response.content)
print(f"Saved 3D model {filename}")
# Display the result
output.no_vertical_scroll()
print("Original image:")
thumb = Image.open(image)
thumb.thumbnail((256, 256))
display(thumb)
print("3D model result:")
display_glb(filename)
リクエストのヘッダーには、authorization フィールドに API キーを含める必要があります。リクエストの本文は multipart/form-data でなければなりません。
Stable Fast 3Dは、TripoSRを基にした重要なアーキテクチャの改善と強化された機能により、単一の画像からわずか0.5秒で高品質な3Dアセットを生成します。これはゲームやVRの開発者、リテール、建築、デザイン、およびその他のグラフィック集約型の分野の専門家に役立ちます。
Stable Video 4D
Stable Video 4Dは、単一の動画をアップロードすることで、8つの視点からダイナミックな新視点動画を受け取ることができるモデルです。単一のオブジェクト動画を複数の新視点動画に変換し、約40秒で8つの視点から5フレームの動画を生成します。カメラアングルを指定することで、特定のクリエイティブニーズに合わせて出力を調整できます。これにより、新たなレベルの柔軟性と創造性が提供されます。
SV3Dは、Stable Video Diffusionのパワーを活用し、斬新なビュー合成において優れた品質と一貫性を保証することで、3D技術における新たなベンチマークを設定します。このモデルには2つの異なるバリエーションがあります: SV3D_uは単一画像から軌道動画を生成し、SV3D_pは単一画像と軌道画像の両方からフル3D動画を生成するための強化された機能を提供します。
Stable Video 4D は、1つの目的の動画から、8 つの異なる角度/視点からの斬新な複数視点動画に変換します。
Stable Video 4D は、1回の推論で、8視点にわたる 5フレームを約40秒で生成します。
ユーザーはカメラアングルを指定して、特定のクリエイティブニーズに合わせて出力を調整できます。
現在研究段階にあるこのモデルは、ゲーム開発、動画編集、バーチャルリアリティにおける将来的な応用が期待されており、継続的な改善が進められています。Hugging Face で現在公開中です。
仕組み
ユーザーはまず、単一の動画をアップロードし、目的の3D カメラの姿勢を指定します。次に、Stable Video 4D は、指定されたカメラの視点に従って 8 つの斬新な視点動画を生成し、被写体の包括的で多角的な視点を提供します。生成された動画は、動画内の被写体の動的な 3D 表現を効率的に最適化するために使用できます。
Stable Video 4D は、既存の事例と比較して、より詳細で、入力動画に忠実で、フレームと視点間で一貫性のある斬新な視点動画を生成できます。
研究開発
Stable Video 4D は Hugging Face で公開されており、Stability AI 初の動画から動画への生成モデルであり、エキサイティングなマイルストーンとなっています。現在トレーニングに使用されている合成データセットを超えて、より幅広い実際の動画を処理できるように、モデルの改良と最適化に積極的に取り組んでいます。
ニュースです。2024年7月5日、Stability AIが「Stability AI Community License」を発表しました。当初 SD3 に関連付けられていた商用ライセンスがコミュニティ内で混乱と懸念を引き起こしていたことを受け止め、個人クリエイターと中小企業向けのライセンスが改訂されました。 公式リリースよりお送りします。
Stability AIは、新しく「Stability AI Community License」を発表しました。このライセンスでは、研究、非商用、商用利用を無償で許可されます。年間収益が100万米ドル(現在のレートで約1億6千万円)を超え、Stability AIのモデルを商用製品やサービスに使用する場合のみ、有料のエンタープライズライセンスが必要となります。
a man and woman are standing together against a backdrop, the backdrop is divided equally in half down the middle, left side is red, right side is gold, the woman is wearing a t-shirt with a yoda motif, she has a long skirt with birds on it, the man is wearing a three piece purple suit, he has spiky blue hair(例を見る)
a man wearing 1980s red and blue paper 3D glasses is sitting on a motorcycle, it is parked in a supermarket parking lot, midday sun, he is wearing a Slipknot t-shirt and has black pants and cowboy boots (例を見る)
a close-up half-portrait photo of a woman wearing a sleek blue and white summer dress with a monstera plant motif, has square white glasses, green braided hair, she is on a pebble beach in Brighton UK, very early in the morning, twilight sunrise(例を見る)
a man and woman are standing together against a backdrop, the backdrop is divided equally in half down the middle, left side is red, right side is gold, the woman is wearing a t-shirt with a yoda motif, she has a long skirt with birds on it, the man is wearing a three piece purple suit, he has spiky blue hair