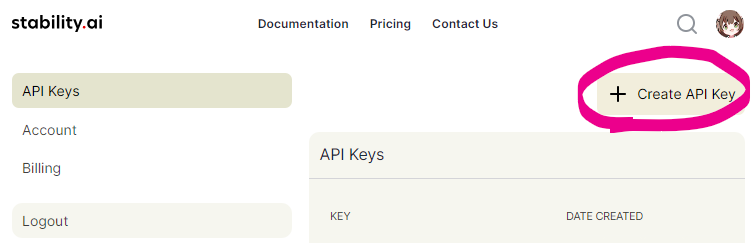
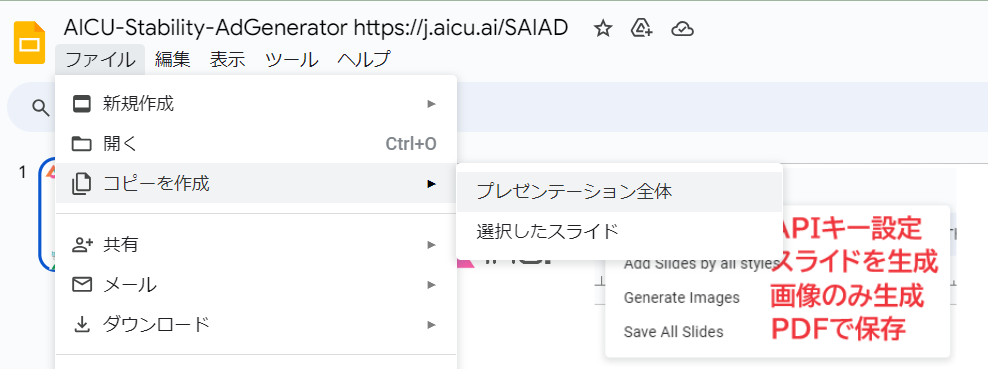
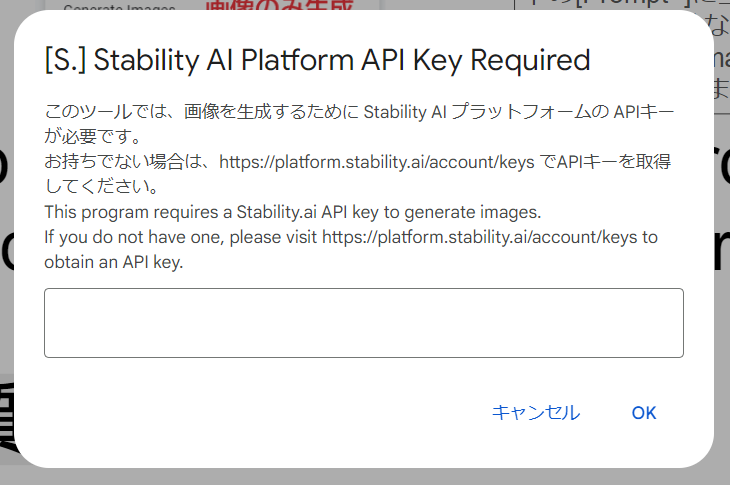
This program requires a Stability.ai API key to generate images. If you do not have one, please visit https://platform.stability.ai/account/keys to obtain an API key.
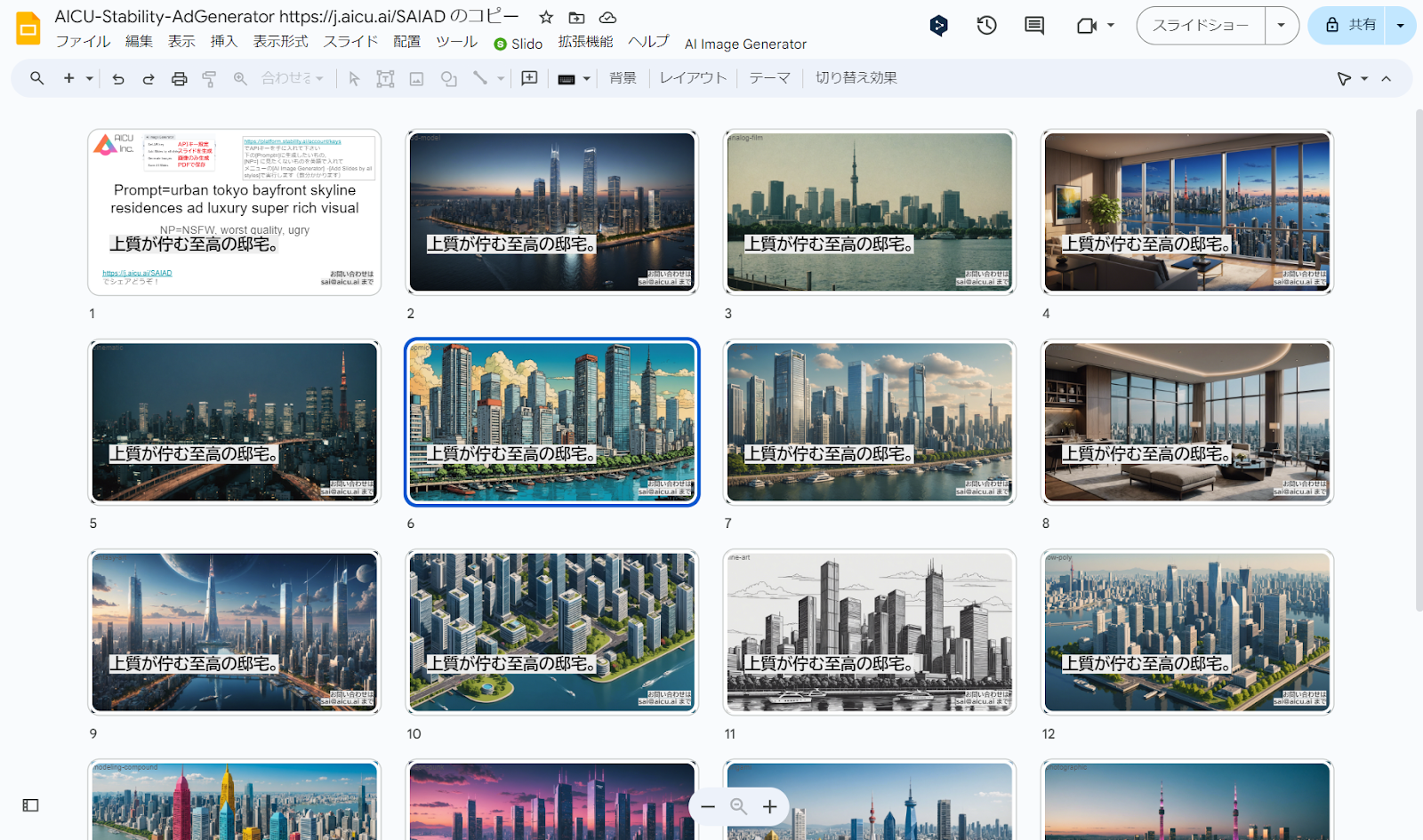
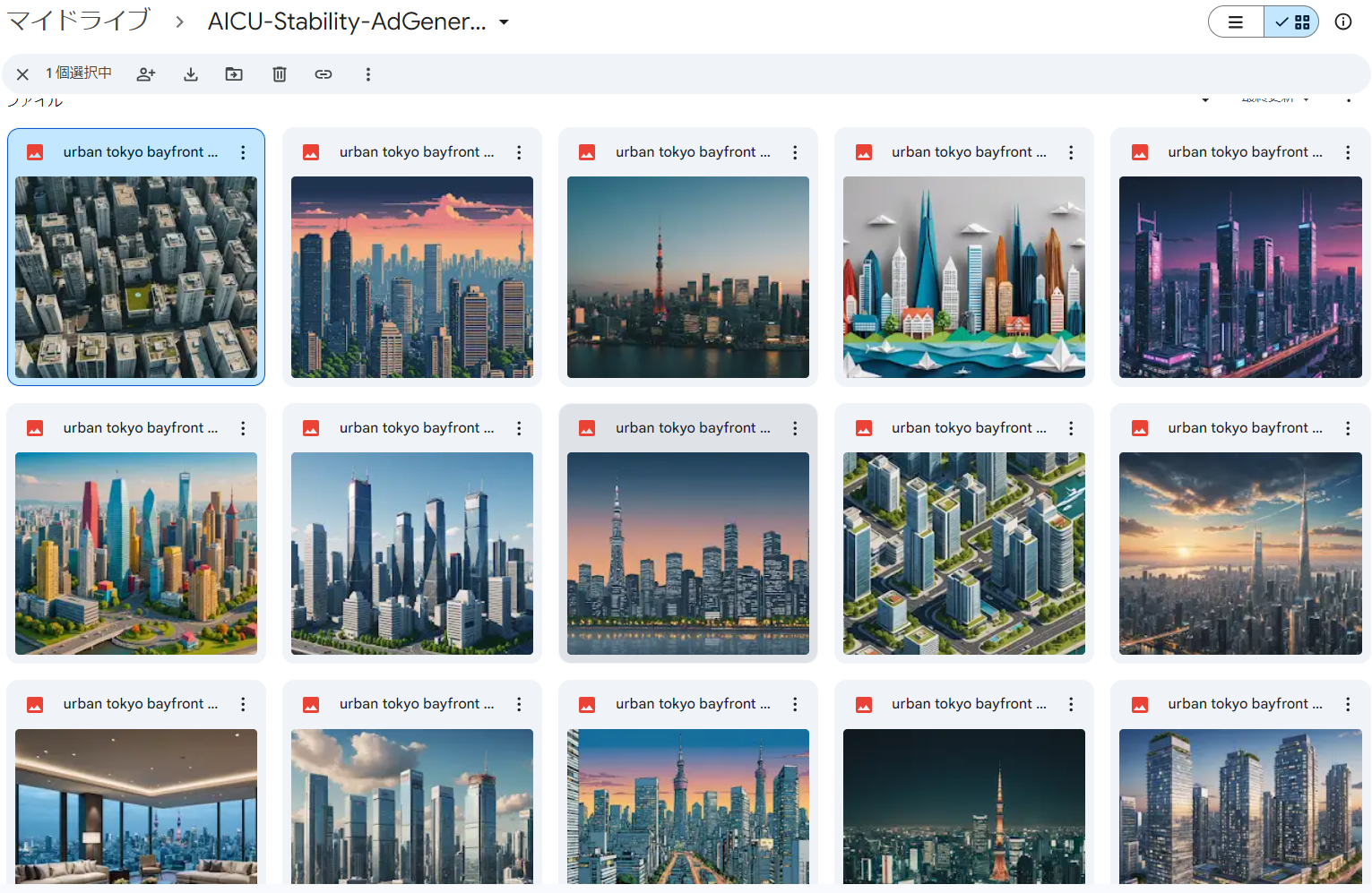
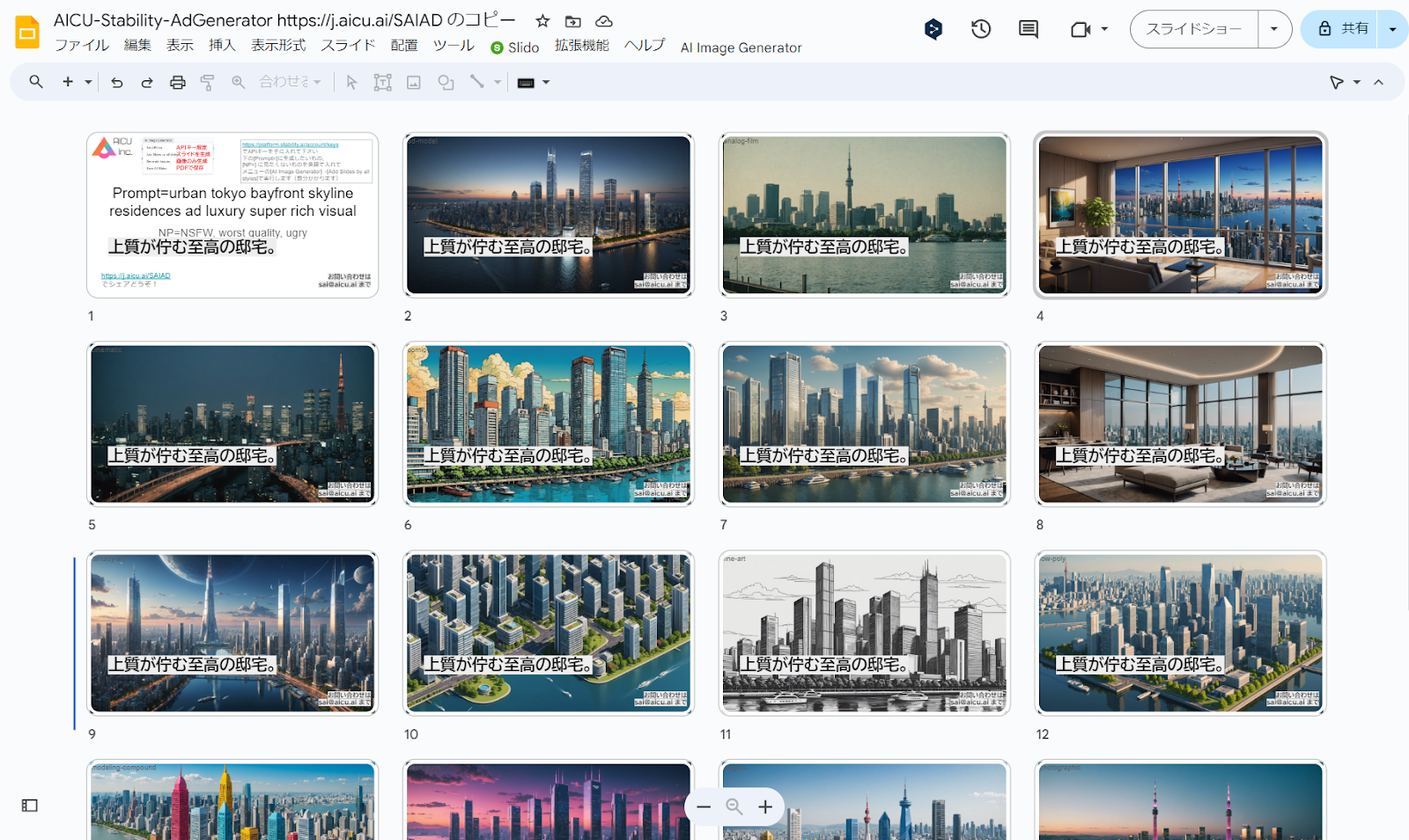
初期状態では「Prompt=urban tokyo bayfront skyline residences ad luxury super rich visual」(プロンプト=東京ベイフロントのスカイライン・レジデンス広告の豪華なスーパー・リッチ・ビジュアル)となっているので、このまま何度でも「Add Slides by all styles」を実行すれば15枚づつ、東京湾ベイエリアの高級そうな住居の画像が生成されます。第1ページにある「Prompt=」と「NP=」を変えるだけなので、例えばこんなプロンプトにしてみます
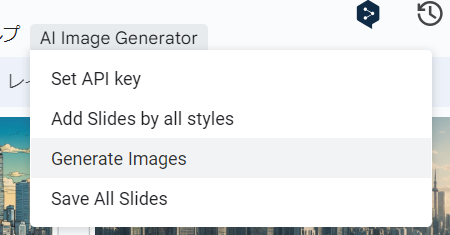
・Add Slides by all styles:タイトル(1枚目のスライド)で「Prompt=」で与えられたプロンプトと「NP=」で与えられたネガティブプロンプト(英語)から Stability AIの Stable Image Core API を使用して15種類のスタイル適用済み画像をGPU不要で画像を生成し、1枚生成されるごとに、スライドの画面全体に表示されるように背景画像として配置しています。追加された各スライドのタイトルとメモに 使用したstyleとプロンプトを設定しています。
・Generate Images:タイトル(1枚目のスライド)で与えられたプロンプトから、スライドのファイル名と同じ名前のディレクトリにすべてのスタイルの2,040 x 1,152pixelsの画像を15スタイル生成します。
・Save All Slides:PDF がDriveに保存されます。Google Slidesの[ファイル]⇢[ダウンロード]で保存でも構いません。
・15スタイルの生成は3分程度で51credit (80円ぐらい)です。
※安全のため、他人とシェアするときは Set API Keyを使って有効ではないAPIキーを設定しておくことをおすすめします。 ※本ツールのソースコードが気になる方は Google Slides上でスクリプトエディタをご参照ください。このコードの著作権はAICU Inc. が保有しています。この記事で公開されているツールの使用における損害等についてAICU Inc.は責任を負いません。 ※実際の広告等への利用など Stable Diffusionの商用利用に関するご質問は sai@aicu.ai までお問い合わせください。
技術解説「Slidesだけでも画像生成できる」
Google SlidesをコピーしてAPIキーを貼り付けるだけで様々なスタイルの画像を生成をすることができました!
AICU media では今後も話題の Stable Diffusion 3.0 やStable Image Core を用いた記事を発信していく予定です。面白かったらぜひフォロー、いいねをお願いします!
# The next line may need to be modified depending on the environment model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.float16, low_cpu_mem_usage=True, device_map="auto", trust_remote_code=True, )
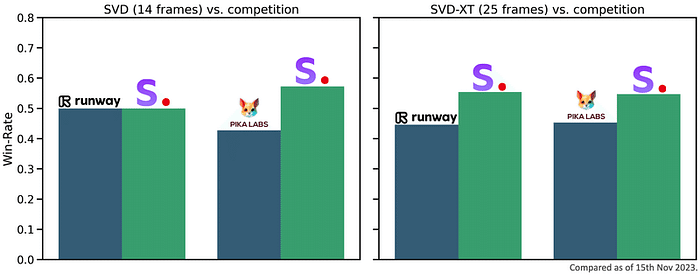
2023年11月21日、StabilityAI社は画像から動画を生成する技術「Stable Video Diffusion」(SVD)を公開しました。 研究者の方はGitHubリポジトリで公開されたコードを試すことができます。ローカルでモデルを実行するために必要なウェイトは、HuggingFaceで公開されています(注意:40GBのVRAMが必要です)。 さらにStable Video Diffusion (SVD) を使って画像から動画へウェブインタフェースも近日公開予定とのこと。キャンセル待ちリストが公開されています。
「Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets」(21 Nov ,2023) 安定した映像拡散: 潜在的映像拡散モデルの大規模データセットへの拡張
高解像度で最先端のテキストから動画、画像から動画生成のための潜在動画拡散モデル、Stable Video Diffusionを紹介する。近年、2次元画像合成のために学習された潜在拡散モデルは、時間レイヤーを挿入し、小規模で高品質なビデオデータセット上で微調整することで、生成的なビデオモデルへと変化している。しかし、文献に記載されている学習方法は様々であり、ビデオデータをキュレーションするための統一的な戦略について、この分野はまだ合意されていない。本論文では、動画LDMの学習を成功させるための3つの異なる段階を特定し、テキストから画像への事前学習、動画の事前学習、高品質動画の微調整の評価を行った。