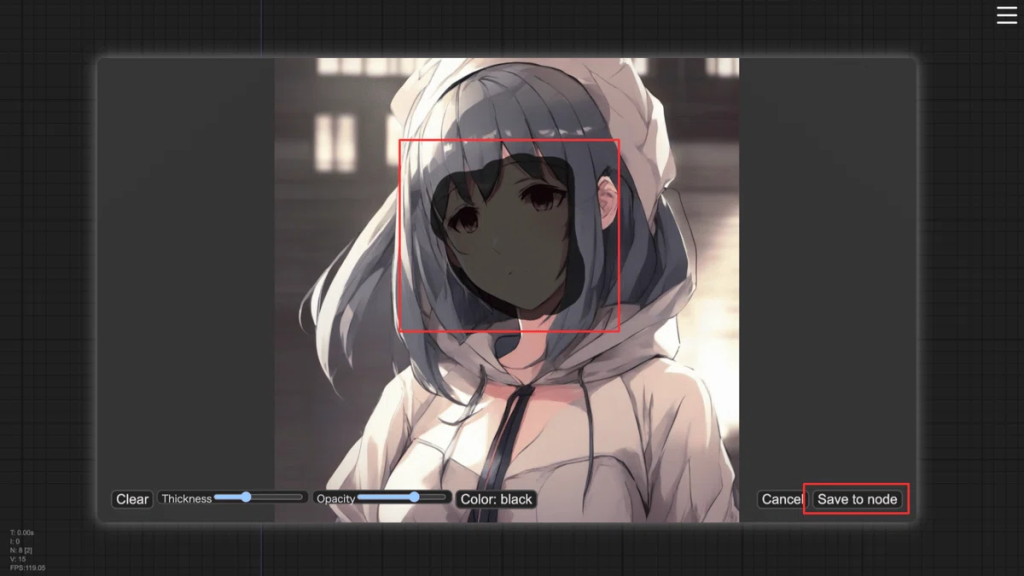
次に「Load Image」ノードを追加し、「choose file to upload」から対象の画像をアップロードします。
次に空白をダブルクリックして「Pad Image for Outpainting」を追加し、「Load Image」の出力「IMAGE」と、「Pad Image for Outpainting」の入力「image」を接続します。
「Pad Image for Outpainting」では、left、top、right、bottomにピクセル単位で拡張するサイズを指定できます。また、feathering(フェザリング)は、画像の端をぼかして滑らかに周囲と馴染ませる技術です。outpaintingでは、元の画像と新しく生成した部分の境界をなめらかにつなぐために使用されます。今回は、topに200px、featheringに100pxを指定しました。
こんにちは!Stability AI の生成メディアソリューションエンジニア(およびフリーランスの 2D/3D コンセプトデザイナー)の Yeo Wang です。YouTube で私のビデオを見たことがあるかもしれませんし、コミュニティ(Github)を通じて私を知っているかもしれません。個人的には、SD3 Medium をトレーニングしたときにまともな結果が得られたので、完全なファインチューニングと LoRA トレーニングの両方について、いくつかの洞察とクイックスタート構成を共有します。
In addition, there is a repeats parameter that you may or may not be familiar with depending on whether or not you’ve used other training repositories before. repeats duplicates your images (and optionally rotates, changes the color, etc.) and captions as well to help generalize the style into the model and prevent overfitting. While SimpleTuner supports caption dropout (randomly dropping captions a specified percentage of the time),it doesn’t support shuffling tokens (tokens are kind of like words in the caption) as of this moment, but you can simulate the behavior of kohya’s sd-scripts where you can shuffle tokens while keeping an n amount of tokens. If you’d like to replicate that, I’ve provided a script here that will duplicate the images and manipulate the captions: さらに、以前に他のトレーニングリポジトリを使ったことがあるかどうかによって、馴染みがあるかどうかが分かれるかもしれないrepeatsパラメータがあります。repeatsは、モデルにスタイルを一般化し、オーバーフィッティングを防ぐために、画像(オプションで回転、色の変更など)とキャプションを複製します。SimpleTunerはキャプションのドロップアウト(指定した割合でランダムにキャプションをドロップする)をサポートしていますが、現時点ではトークン(トークンはキャプションの単語のようなもの)のシャッフルはサポートしていません:
import os
import shutil
import random
from pathlib import Path
import re
def duplicate_and_shuffle_dataset(input_folder, output_folder, dataset_repeats, n_tokens_to_keep):
# Create output folder if it doesn't exist
Path(output_folder).mkdir(parents=True, exist_ok=True)
# Get all image files
image_files = [f for f in os.listdir(input_folder) if f.lower().endswith(('.png', '.jpg', '.jpeg'))]
for i in range(dataset_repeats):
for image_file in image_files:
# Get corresponding text file
text_file = os.path.splitext(image_file)[0] + '.txt'
if not os.path.exists(os.path.join(input_folder, text_file)):
print(f"Warning: No corresponding text file found for {image_file}")
continue
# Create new file names
new_image_file = f"{os.path.splitext(image_file)[0]}_{i+1}{os.path.splitext(image_file)[1]}"
new_text_file = f"{os.path.splitext(text_file)[0]}_{i+1}.txt"
# Copy image file
shutil.copy2(os.path.join(input_folder, image_file), os.path.join(output_folder, new_image_file))
# Read, shuffle, and write text file
with open(os.path.join(input_folder, text_file), 'r') as f:
content = f.read().strip()
# Split tokens using comma or period as separator
tokens = re.split(r'[,.]', content)
tokens = [token.strip() for token in tokens if token.strip()] # Remove empty tokens and strip whitespace
tokens_to_keep = tokens[:n_tokens_to_keep]
tokens_to_shuffle = tokens[n_tokens_to_keep:]
random.shuffle(tokens_to_shuffle)
new_content = ', '.join(tokens_to_keep + tokens_to_shuffle)
with open(os.path.join(output_folder, new_text_file), 'w') as f:
f.write(new_content)
print(f"Dataset duplication and shuffling complete. Output saved to {output_folder}")
# Example usage
input_folder = "/weka2/home-yeo/datasets/SDXL/full_dataset_neo"
output_folder = "/weka2/home-yeo/datasets/SDXL/duplicate_shuffle_10_fantasy"
dataset_repeats = 10
n_tokens_to_keep = 2
duplicate_and_shuffle_dataset(input_folder, output_folder, dataset_repeats, n_tokens_to_keep)
ph070, A rainy urban nighttime street scene features two cars parked along the wet pavement. The primary subject is a sleek, modern silver car with streamlined curves and glistening wheels reflecting the rain-soaked road. The background includes another vehicle—a darker sedan—partially obscured. Illuminated signs with Asian characters suggest a city setting possibly in a bustling nightlife district. The style is distinctly cinematic with a futuristic, neo-noir aesthetic, characterized by moody blue tones and the reflective glow of wet surfaces. The streetlights and the occasional gleam of neon green and orange provide contrast, enhancing the dark ambiance of the city at night. The atmosphere evokes a sense of mystery and quiet anticipation, with the deserted street hinting at hidden stories or events about to unfold.
#!/bin/bash# Source directory where the models are stored
SOURCE_DIR="/admin/home-yeo/workspace/simpletuner_models/sd3_medium/full_finetune/cinema_photo/03/datasets/models"
# Target directory for symlinks
TARGET_DIR="/admin/home-yeo/workspace/ComfyUI/models/unet/simpletuner_blog_cine_photo_03"
# Iterate over each checkpoint directory
for CHECKPOINT_DIR in $(ls -d ${SOURCE_DIR}/checkpoint-*); do
# Extract the checkpoint number from the directory name
CHECKPOINT_NAME=$(basename ${CHECKPOINT_DIR})
# Define the source file path
SOURCE_FILE="${CHECKPOINT_DIR}/transformer/diffusion_pytorch_model.safetensors"
# Define the symlink name
LINK_NAME="${TARGET_DIR}/${CHECKPOINT_NAME}.safetensors"
# Check if the source file exists
if [ -f "${SOURCE_FILE}" ]; then
# Create a symlink in the target directory
ln -s "${SOURCE_FILE}" "${LINK_NAME}"
echo "Symlink created for ${CHECKPOINT_NAME}"
else
echo "File not found: ${SOURCE_FILE}"
fi
done
echo "Symlinking complete."
a close up three fourth perspective portrait view of a young woman with dark hair and dark blue eyes, looking upwards and to the left, head tilted slightly downwards and to the left, exposed forehead, wearing a nun habit with white lining, wearing a white collared shirt, barely visible ear, cropped, a dark brown background 黒髪で濃い青の瞳をした若い女性のクローズアップ三四透視図。上を見て左を向き、頭はやや下向きで左に傾いており、額は露出しています。白い裏地のついた修道服に身を包み、白い襟付きシャツを着ており、耳はかろうじて見えています。
a front wide view of a small cyberpunk city with futuristic skyscrapers with gold rooftops situated on the side of a cliff overlooking an ocean, day time view with green tones, some boats floating in the foreground on top of reflective orange water, large mechanical robot structure reaching high above the clouds in the far background, atmospheric perspective, teal sky 海を見下ろす崖の中腹に建つ、金色の屋根を持つ近未来的な高層ビルが建ち並ぶ小さなサイバーパンク都市の正面からのワイドビュー、緑を基調とした日中の眺め、反射するオレンジ色の水の上に浮かぶ手前のいくつかのボート、遠景の雲の上まで届く大きな機械仕掛けのロボット構造、大気遠近法、ティール色の空
a medium view of a city square alongside a river, two large red boats in the foreground with cargo on them, two people in a smaller boat in the bottom right cruising along, reflective dark yellow water in the river, a congregation of people walking along the street parallel to the river in the midground, a dark white palazzo building with dark white tower on the right with red tones, golden hour, red and yellow flag in the top left foreground, light blue flag with yellow accents in the right midground, aerial perspective 川沿いの広場の中景、前景に荷を載せた2隻の赤い大型ボート、右下の小さなボートに乗った2人のクルージング、反射する濃い黄色の川の水、中景に川と平行する通りを歩く人々、右手に赤を基調とした濃い白の塔を持つ濃い白のパラッツォの建物、ゴールデンタイム、左上の前景に赤と黄色の旗、右の中景に黄色のアクセントのある水色の旗、空からの視点。