Stable Assistantを触りながらココナラで案件を探してみたら、想像以上にいろいろできた…😳✨
みなさん、毎度ありがとうございます AICUメディア営業部です!
生成AI時代に「つくる人をつくる」をビジョンに活動するAICUメディアのお手伝いしながら、AICUのナレッジを「もっと売る」をミッションとして活動しております。
前回までズボラな私が「Stable Assistant」の無料お試しを使って画像生成や画像加工や動画生成、楽曲生成や3D生成をしてココナラにアカウントをつくって実際に案件に応募するまでのお話がこちらです。
<Day1レポート>無料トライアル3日間でこんなにお得!?
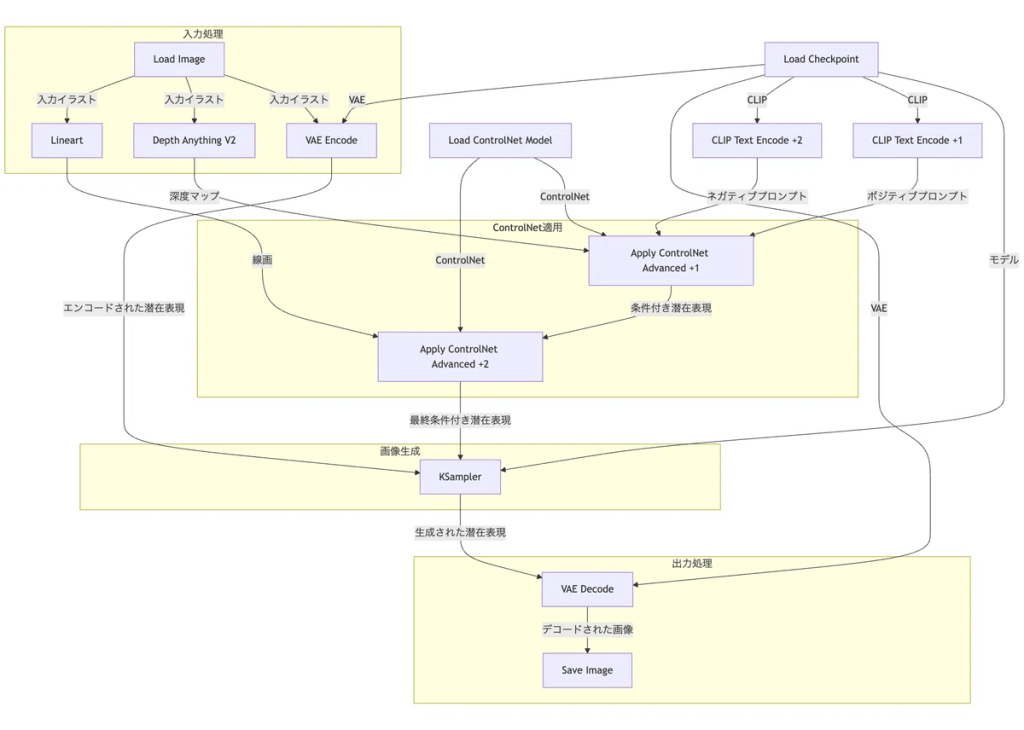
実際にStable Assistantを使った画像処理でやってみた画像処理がこちらです
<Day2レポート> 案件にAIで提案してみた
3日日は、実際にココナラでの案件を Stable Assistant の無料枠で営業していく上での注意点についてお伝えします!
用意するツールとアカウントの準備
・ココナラのアカウント
・クレジットカード
・Stable Assistantのアカウント登録
・Google Gemini (あると嬉しい)
・DeepL無料版(なくても大丈夫)
ココナラのアカウントはこちらから登録すると紹介ポイントが手に入ります。
まずココナラの検索をするうえでプロフィールを埋めます
プロフィールはGoogle Gemini「AI Studio」で埋めました。ロングコンテキストが扱えるので便利です。翻訳もこれで問題なし!
日本で最も有名な画像生成AIのプロフェッショナルの営業部です
はじめまして!AICUメディア営業部です。 2022年から活動している画像生成AIにおける元祖「Stable Diffusion」を応援し続けて2年を超える画像生成AIのラーニングメディア「AICUメディア」の営業部です。所属クリエイターと最新のクリエィティブAI技術とノウハウによりお客様の大切な案件を予想を上回る速度とクオリティ、スマートに納品させていただいております。 【弊社の特徴】 (1) ブログメディアでの紹介! 生成AI時代に「つくる人をつくる」をコンセプトにして活動させていただいております。 ブログメディアでの紹介をさせていただけることで、単なる「案件」ではなく、AI+人間のクリエイターならではの速度、品質、細やかさ、そして御社の知名度もアップ!を特徴としております。 ✨️「AICU」で検索してみていただければ幸いです。 (2) 作業速度がものすごい 米国に本社があるため日本のカレンダーに依存しない!深夜対応も歓迎です。 (3) お試しいただいてご納得いただいてからの作業着手 可能な限り仕上がりサンプルをご確認いただいてからのご発注プロセスを取っております。 残念ながら不成となった案件は依頼主様等の情報を外した状態で実績としてブログ等で紹介させていただきます。
https://coconala.com/users/4956128
Stable Assistantの新機能を紹介!
Stable Assistantもアップデートを繰り返しています。
先日、10月20日に背景置き換え機能がリリースされました!
https://x.com/AICUai/status/1846341417263943730
画像をアップロードしてツールメニューから「Replace Background」で利用できます。
この画像が…

アップロードしてから選べるカバンメニューで「Replace Background」

サンプルどおりに「In the Jungle」に置き換えてみます。

これは便利ですね。
プロンプトの代わりに画像も与えられます。

こちらを与えてみます。

こんな感じです。

Day2で扱ったような中古車販売のような使い道によいかもしれませんね!
顔をマスクしよう
さて、前回扱った「Search and Replace」で便利な使い道を発見しました。
プライバシーを守るための「顔マスク」です。
画像をアップロードしてカバンメニューから「Search and Replace」です。
ここに「face」を対象に「mask」を入れるだけ!

じゃーん!

これでプライバシー保護もバッチリ!?
さて続いてココナラとStable Assistantを使って案件をこなしていくうえでの倫理関係の考察をしてみたいと思います。
Stable Assistantは商用利用できますか?
Stable Assistantの利用規約では、商用利用について明確な禁止事項は明記されていません。しかし、いくつかの点に注意が必要です。
- 利用規約で許諾されている範囲内での利用: 利用規約では、Stable Assistantの出力(画像、音楽、動画など)について、Stability AIに非独占的なライセンスを付与することになっています。つまり、Stability AIは、あなたの出力を使用する権利を持っています。
- 知的財産権: Stable Assistantで生成したコンテンツの知的財産権は、基本的にあなたに帰属します。しかし、Stable Assistantが学習したデータの一部が著作権で保護されている可能性があります。
- 著作権フリー: 生成したコンテンツを商用利用する場合は、著作権の侵害に注意する必要があります。Stable Assistantでは、著作権フリーの画像や音楽を生成することも可能です。
- 責任の所在: Stable Assistantの出力に基づいて、あなたが何らかの損害や責任を負った場合、Stability AIは責任を負いません。
商用利用を検討する際は、以下の点も確認しておきましょう。
- Stable Assistantの利用規約をよく読んで理解する
- 生成したコンテンツの著作権について調べる
- 商用利用に適したコンテンツかどうか判断する
- 必要な法的アドバイスを受ける
Stable Assistantは、強力なツールですが、商用利用には注意が必要です。上記を参考に、安全にそして適切な形でStable Assistantを活用してください。
Stable Assistant Terms of Service
https://stability.ai/stable-app-terms-of-service
他にも気をつけたこと
ココナラでの依頼を調べるうえで「いちおう手を動かしてみたけど、これはやめたほうが良いな…」と感じた案件をまとめてみます。
「生成AI使ってもいいよ」と書かれている案件を選ぶ
もちろんプロのアーティストさんが描いたほうがよさそう、という案件も多くありますが、その中でも探してみると「生成AI使っていいよ!」という案件はありました。
また既存の自社サイトやサンプルイメージとしてChatGPT(DALL-E3)での画像を使われていて「もうちょっとどうにかしたい」という趣向でご依頼されている方も多くいらっしゃいました。
実際のところ、上手な画像を生成するのってテクニック要りますよねぇ…(といって編集部のみなさんの頑張りを眺めています)
依頼そのものがふわっとしている案件は避ける
「依頼そのものがふわっとしている…」この辺は発注者としてついやってしまいがちなのですが、避けたいところですね…。
例えば「前に依頼したのだけど気に入らなかった」とか「見積額による」といった案件ですね。
この辺は発注者としてついやってしまいがちなのですが、避けたいところですね……。
1つの案件で複数の依頼をしている案件は避ける
イラストや似顔絵に時々あるのですが、「1点でXXXX円、2点でXXXX円、5点全部揃ったらXXXXX円」といった依頼です。
実際、手を動かしてみたのですが、点数が多くなれば多くなるほど難度は上がると思います。
もちろん、アウトペイント(ズーム機能)で外側を描いたりしてレイアウトを変えるだけだったり、背景削除で置き換えるだけの仕様ならそんなに難しくはないのですが、描く要素が多くなったり、キャラクターデザインの一貫性を維持したうえで複数の画像を用意するのは難しいと思いました。
ただこれは、考え方とかやり方次第かもしれません。
たとえば3D化を使って、多視点にしてみたら……あ、できるかも??
「生成AI+人間の作業です」を伝える
ココナラは募集している案件に「提案」として作文を書くのですが、そこに「生成AI+人間の作業です」と伝えたほうが良いと思いました。
今回の調査では「ココナラ」以外の別のクラウドソーシングサイトも調査してみたのですが「生成AIだけ」で「作業単価が10円ぐらい」といった市場もあったりもします。
こういう依頼を見ていると「生成AI使ったって人間の作業時間があるんだよ!!」という気持ちでいっぱいになります。
イラストレーターさんがたくさん応募している案件は避ける
締め切りまでの日数や案件にもよるのですが、すでにたくさんのイラストレーターさんが応募している案件に「生成AIでやります!」といって乗り込んでいくのは勇気がいります。「生成AIが人の仕事を奪う」みたいな言われ方をするのが心外なので…(小心者)。
それに、イラストレーターさんの手仕事は尊いですよ。
AICUも「画像生成AIクリエイター仕草(v.1.0)」で言ってます。
「手仕事とAI」を「市場として混ぜるのは禁止」という感想です。
納期が不明瞭で直しが無限になりそうな案件は避ける
この辺は発注者としても避けたいところですね~!
現行の下請法にも違反ですし、令和6年11月1日から「特定受託事業者に係る取引の適正化等に関する法律(フリーランス・事業者間取引適正化等法)」が施行されています。
https://www.mhlw.go.jp/content/001278830.pdf
発注者がココナラ規約違反になる流れもけっこある
発注者さんが必ずしも悪気があってやっているのではない場合もあります。実はココナラには「外部でやり取りしてはならない」という厳格なルールがあるらしく、Google DriveやGoogle Formを使ったコミュニケーションが入っていると事務局判断で案件が停止されることもあります。
結構な頻度で起きているので、あまり腹を立てずに付き合いたいところです。
「スピード重視」「品質重視」「継続依頼あり」「初心者OK」を探す

まずは5,000円以下ぐらいの案件からやってみる
ココナラには出品者ランクがあり、ランクアップすることで信頼度がアップします。レベルを上げるためには小さくても案件をこなしていったほうがいいかもしれません。逆に「5千円…安すぎ!」と思ううちはやめておいたほうがいいいかもしれません。

以上、いろいろ述べてしまいましたが、AICU営業部はココナラの活用をこれからも研究していきます。

なお、発注者としてクリエイターさんやライターさんへのお仕事募集もしておりますので、フォローよろしくお願いいたします!
https://coconala.com/requests/3717909
生成AI時代のクラウドワーカーさんとの出会いが楽しみです!
初心者も歓迎です。誰もが最初は初心者ですよね。
以上、AICUメディア営業部がお送りしました

https://coconala.com/users/4956128
#StableAI #StableAssistant #画像生成AI #AI音楽生成 #副業 #ココナラ #AICU営業部
Originally published at https://note.com on Oct 21, 2024.