こんにちわ、AICU media編集部です。
「ComfyUIマスターガイド」シリーズの第7回になります。
今回は、ComfyUIの基本操作と画像の生成について前後編に分けて解説していきたいと思います。
今回は、ComfyUIの基本的な操作から、ショートカット、画像の出力までの簡単な流れを解説します。AUTOMATIC1111と違い、完全にグラフィカルなユーザーインターフェースで操作するノードシステムは慣れるまで大変かと思いますが、用語や操作方法に慣れると大変見やすく効率的になります。またここでは、簡単な用語と中で起きている生成AIの処理についても解説していきます。
1. 設定画面の開き方
1.キャンバスの画面にて、メニューの上部の歯車マークをクリックします。

2.ComfyUIの設定画面が開きます。

2. 設定画面の項目の分類
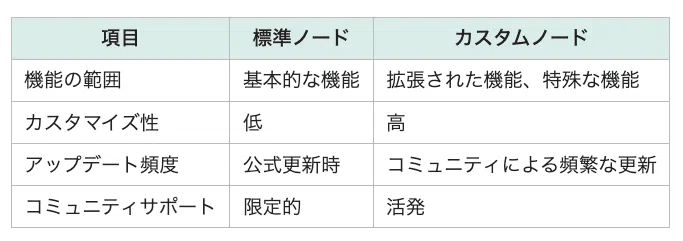
設定画面には、多くの設定項目がありますが、本記事では重要な機能と、知っておくと便利な機能を紹介します。それ以外の高度な機能については、今後機会があれば解説します。
さらに、設定画面の項目の中には、ComfyUIで標準機能として提供されている項目と、ComfyUI Managerで追加機能として提供されている項目があるため、この分類も同時に示します。
- カラーパレットの変更(ComfyUI Manager)
- ノードのウィジェットの小数点以下の桁数の変更(ComfyUI)
- グリッドサイズ(ComfyUI)
- メニューのスクロール方向の反転(ComfyUI)
- 入力とウィジェットを相互変換する項目のサブメニュー化(ComfyUI)
- ノードの提案数の変更(ComfyUI)
- ワークフローのクリア時の確認の有無(ComfyUI)
- キャンバスポジションの保存の有効化(ComfyUI)
- メニュー位置の保存(ComfyUI)
3. 知っておくと便利な機能の解説
メニューの位置の変更
[Beta] Use new menu and workflow management. Note: On small screens the menu will always be at the top.は、Beta版の機能になりますが、メニューの位置を変更する設定になります。

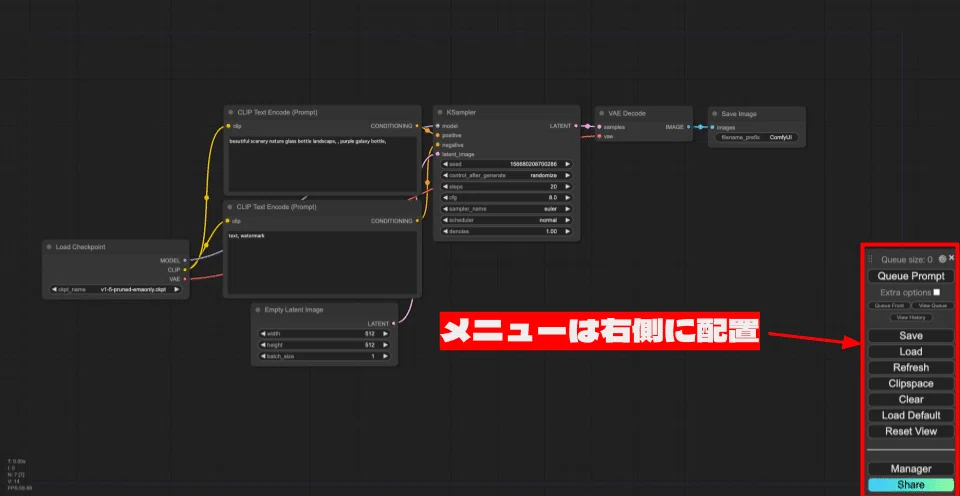
メニューの位置は、以下の3種類から選択できます。
- Disabled: 通常のポジションです。メニューは右側に配置されます。
- Top: メニューは上部に配置されます。

- Bottom: メニューは下部に配置されます。

カラーパレットの変更
Color palette(カラーパレット)は、ComfyUI全体のテーマカラーを設定します。

カラーパレットには、デフォルトの選択肢として以下の6つがあります。それぞれのカラーパレットでの表示の変化は以下の通りです。
- Dark (Default)

- Light

- Solarized

- Arc

- Nord

- Github

カラーパレットは、既存のカラーパレットをカスタマイズしたり、自分で一から作成することも可能です。カラーパレットのプルダウンの下のボタン「Export」「Import」「Template」「Delete」の機能を確認してみましょう。

- Export
Exportは、プルダウンで選択中のカラーパレットの定義ファイル (JSON) を出力します。以下は、Dart (Default)をExportで出力したJSONファイルになります。
{
"id": "dark",
"name": "Dark (Default)",
"colors": {
"node_slot": {
"AUDIO": "",
"AUDIOUPLOAD": "",
"AUDIO_UI": "",
"BBOX_DETECTOR": "",
"BOOLEAN": "",
"CLIP": "#FFD500",
"CLIP_VISION": "#A8DADC",
"CLIP_VISION_OUTPUT": "#ad7452",
"CONDITIONING": "#FFA931",
"CONTROL_NET": "#6EE7B7",
"FLOAT": "",
"GLIGEN": "",
"GUIDER": "#66FFFF",
"IMAGE": "#64B5F6",
"IMAGEUPLOAD": "",
"INT": "",
"LATENT": "#FF9CF9",
"MASK": "#81C784",
"MODEL": "#B39DDB",
"NOISE": "#B0B0B0",
"OPTICAL_FLOW": "",
"PHOTOMAKER": "",
"POSE_KEYPOINT": "",
"SAMPLER": "#ECB4B4",
"SIGMAS": "#CDFFCD",
"STRING": "",
"STYLE_MODEL": "#C2FFAE",
"TAESD": "#DCC274",
"TRACKING": "",
"UPSCALE_MODEL": "",
"VAE": "#FF6E6E",
"WEBCAM": "",
"none,AnimeFace_SemSegPreprocessor,AnyLineArtPreprocessor_aux,BinaryPreprocessor,CannyEdgePreprocessor,ColorPreprocessor,DensePosePreprocessor,DepthAnythingPreprocessor,Zoe_DepthAnythingPreprocessor,DepthAnythingV2Preprocessor,DiffusionEdge_Preprocessor,DSINE-NormalMapPreprocessor,DWPreprocessor,AnimalPosePreprocessor,HEDPreprocessor,FakeScribblePreprocessor,LeReS-DepthMapPreprocessor,LineArtPreprocessor,AnimeLineArtPreprocessor,LineartStandardPreprocessor,Manga2Anime_LineArt_Preprocessor,MediaPipe-FaceMeshPreprocessor,MeshGraphormer-DepthMapPreprocessor,MeshGraphormer+ImpactDetector-DepthMapPreprocessor,Metric3D-DepthMapPreprocessor,Metric3D-NormalMapPreprocessor,MiDaS-NormalMapPreprocessor,MiDaS-DepthMapPreprocessor,M-LSDPreprocessor,BAE-NormalMapPreprocessor,OneFormer-COCO-SemSegPreprocessor,OneFormer-ADE20K-SemSegPreprocessor,OpenposePreprocessor,PiDiNetPreprocessor,SavePoseKpsAsJsonFile,FacialPartColoringFromPoseKps,UpperBodyTrackingFromPoseKps,RenderPeopleKps,RenderAnimalKps,ImageLuminanceDetector,ImageIntensityDetector,ScribblePreprocessor,Scribble_XDoG_Preprocessor,Scribble_PiDiNet_Preprocessor,SAMPreprocessor,ShufflePreprocessor,TEEDPreprocessor,TilePreprocessor,TTPlanet_TileGF_Preprocessor,TTPlanet_TileSimple_Preprocessor,UniFormer-SemSegPreprocessor,SemSegPreprocessor,Unimatch_OptFlowPreprocessor,MaskOptFlow,Zoe-DepthMapPreprocessor": ""
},
"litegraph_base": {
"BACKGROUND_IMAGE": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAGQAAABkCAIAAAD/gAIDAAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAAQBJREFUeNrs1rEKwjAUhlETUkj3vP9rdmr1Ysammk2w5wdxuLgcMHyptfawuZX4pJSWZTnfnu/lnIe/jNNxHHGNn//HNbbv+4dr6V+11uF527arU7+u63qfa/bnmh8sWLBgwYJlqRf8MEptXPBXJXa37BSl3ixYsGDBMliwFLyCV/DeLIMFCxYsWLBMwSt4Be/NggXLYMGCBUvBK3iNruC9WbBgwYJlsGApeAWv4L1ZBgsWLFiwYJmCV/AK3psFC5bBggULloJX8BpdwXuzYMGCBctgwVLwCl7Be7MMFixYsGDBsu8FH1FaSmExVfAxBa/gvVmwYMGCZbBg/W4vAQYA5tRF9QYlv/QAAAAASUVORK5CYII=",
"CLEAR_BACKGROUND_COLOR": "#222",
"NODE_TITLE_COLOR": "#999",
"NODE_SELECTED_TITLE_COLOR": "#FFF",
"NODE_TEXT_SIZE": 14,
"NODE_TEXT_COLOR": "#AAA",
"NODE_SUBTEXT_SIZE": 12,
"NODE_DEFAULT_COLOR": "#333",
"NODE_DEFAULT_BGCOLOR": "#353535",
"NODE_DEFAULT_BOXCOLOR": "#666",
"NODE_DEFAULT_SHAPE": "box",
"NODE_BOX_OUTLINE_COLOR": "#FFF",
"DEFAULT_SHADOW_COLOR": "rgba(0,0,0,0.5)",
"DEFAULT_GROUP_FONT": 24,
"WIDGET_BGCOLOR": "#222",
"WIDGET_OUTLINE_COLOR": "#666",
"WIDGET_TEXT_COLOR": "#DDD",
"WIDGET_SECONDARY_TEXT_COLOR": "#999",
"LINK_COLOR": "#9A9",
"EVENT_LINK_COLOR": "#A86",
"CONNECTING_LINK_COLOR": "#AFA"
},
"comfy_base": {
"fg-color": "#fff",
"bg-color": "#202020",
"comfy-menu-bg": "#353535",
"comfy-input-bg": "#222",
"input-text": "#ddd",
"descrip-text": "#999",
"drag-text": "#ccc",
"error-text": "#ff4444",
"border-color": "#4e4e4e",
"tr-even-bg-color": "#222",
"tr-odd-bg-color": "#353535",
"content-bg": "#4e4e4e",
"content-fg": "#fff",
"content-hover-bg": "#222",
"content-hover-fg": "#fff"
}
}
}- Import
カラーパレットの定義ファイル (JSON)を読み込み、新たなカラーパレットとして使用できるようにします。 - Template
カラーパレットを作成するためのテンプレートの定義ファイル (JSON)を出力します。以下は、テンプレートの一部になります。Exportとの違いは、全ての項目にカラーコードが設定されていないことです。
{
"id": "my_color_palette_unique_id",
"name": "My Color Palette",
"colors": {
"node_slot": {
"AUDIO": "",
"AUDIOUPLOAD": "",
"AUDIO_UI": "",
"BBOX_DETECTOR": "",
"BOOLEAN": "",
"CLIP": "",
"CLIP_VISION": "",
"CLIP_VISION_OUTPUT": "",
"CONDITIONING": "",
"CONTROL_NET": "",
"FLOAT": "",
"GLIGEN": "",
"GUIDER": "",
"IMAGE": "",
"IMAGEUPLOAD": "",
"INT": "",
"LATENT": "",
"MASK": "",
"MODEL": "",
"NOISE": "",
"OPTICAL_FLOW": "",
"PHOTOMAKER": "",
"POSE_KEYPOINT": "",
"SAMPLER": "",
"SIGMAS": "",
"STRING": "",
"STYLE_MODEL": "",
"TRACKING": "",
"UPSCALE_MODEL": "",
"VAE": "",
"WEBCAM": "",
"none,AnimeFace_SemSegPreprocessor,AnyLineArtPreprocessor_aux,BinaryPreprocessor,CannyEdgePreprocessor,ColorPreprocessor,DensePosePreprocessor,DepthAnythingPreprocessor,Zoe_DepthAnythingPreprocessor,DepthAnythingV2Preprocessor,DiffusionEdge_Preprocessor,DSINE-NormalMapPreprocessor,DWPreprocessor,AnimalPosePreprocessor,HEDPreprocessor,FakeScribblePreprocessor,LeReS-DepthMapPreprocessor,LineArtPreprocessor,AnimeLineArtPreprocessor,LineartStandardPreprocessor,Manga2Anime_LineArt_Preprocessor,MediaPipe-FaceMeshPreprocessor,MeshGraphormer-DepthMapPreprocessor,MeshGraphormer+ImpactDetector-DepthMapPreprocessor,Metric3D-DepthMapPreprocessor,Metric3D-NormalMapPreprocessor,MiDaS-NormalMapPreprocessor,MiDaS-DepthMapPreprocessor,M-LSDPreprocessor,BAE-NormalMapPreprocessor,OneFormer-COCO-SemSegPreprocessor,OneFormer-ADE20K-SemSegPreprocessor,OpenposePreprocessor,PiDiNetPreprocessor,SavePoseKpsAsJsonFile,FacialPartColoringFromPoseKps,UpperBodyTrackingFromPoseKps,RenderPeopleKps,RenderAnimalKps,ImageLuminanceDetector,ImageIntensityDetector,ScribblePreprocessor,Scribble_XDoG_Preprocessor,Scribble_PiDiNet_Preprocessor,SAMPreprocessor,ShufflePreprocessor,TEEDPreprocessor,TilePreprocessor,TTPlanet_TileGF_Preprocessor,TTPlanet_TileSimple_Preprocessor,UniFormer-SemSegPreprocessor,SemSegPreprocessor,Unimatch_OptFlowPreprocessor,MaskOptFlow,Zoe-DepthMapPreprocessor": ""
},
"litegraph_base": {
"BACKGROUND_IMAGE": "",
"CLEAR_BACKGROUND_COLOR": "",
"NODE_TITLE_COLOR": "",
"NODE_SELECTED_TITLE_COLOR": "",
"NODE_TEXT_SIZE": "",
"NODE_TEXT_COLOR": "",
"NODE_SUBTEXT_SIZE": "",
"NODE_DEFAULT_COLOR": "",
"NODE_DEFAULT_BGCOLOR": "",
"NODE_DEFAULT_BOXCOLOR": "",
"NODE_DEFAULT_SHAPE": "",
"NODE_BOX_OUTLINE_COLOR": "",
"DEFAULT_SHADOW_COLOR": "",
"DEFAULT_GROUP_FONT": "",
"WIDGET_BGCOLOR": "",
"WIDGET_OUTLINE_COLOR": "",
"WIDGET_TEXT_COLOR": "",
"WIDGET_SECONDARY_TEXT_COLOR": "",
"LINK_COLOR": "",
"EVENT_LINK_COLOR": "",
"CONNECTING_LINK_COLOR": ""
},
"comfy_base": {
"fg-color": "",
"bg-color": "",
"comfy-menu-bg": "",
"comfy-input-bg": "",
"input-text": "",
"descrip-text": "",
"drag-text": "",
"error-text": "",
"border-color": "",
"tr-even-bg-color": "",
"tr-odd-bg-color": "",
"content-bg": "",
"content-fg": "",
"content-hover-bg": "",
"content-hover-fg": ""
}
}
}- Delete
登録されているカラーパレットを削除します。削除されるカラーパレットは、現在選択しているカラーパレットになります。
ノードのウィジェットの小数点以下の桁数の変更
Decimal placesは、ノードのウィジェットの小数点以下の桁数を変更できます。初期値は0で、小数点以下の桁数はComfyUI側で自動的に決定される設定になっています。

以下に小数点以下の桁数が0の場合と5の場合の表示の違いを示します。小数点以下の桁数が0の場合は、cfgとdenoiseは、それぞれ8.0、1.00となっていますが、小数点以下の桁数が5の場合は、8.00000、1.00000と、小数点以下の桁数が5桁になっています。

グリッドサイズ
Grid Size(グリッドサイズ)一度のフローの実行で複数枚の画像を生成すると、Save Image(画像を保存するノード)に生成した画像がプレビューされますが、そのプレビューされる画像の枚数を指定します。

例えば、グリッドサイズを10に設定し、フローで生成される画像の枚数を15枚(Empty Latent Imageノードのbatch_sizeを15に設定)した場合、Save Imageには10枚の画像がグリッドで表示されます。残りの5枚は表示されないだけで、保存はされています。

メニューのスクロール方向の反転
Invert Menu Scrollingは、キャンバスやノードを右クリックして表示されるメニューのスクロール方向を反転する項目です。この項目にチェックが入っていると、スクロール方向が反転します。

通常は、マウスホイールを上に回すと、メニューも上に移動し、下に回すと、メニューが下に移動します。これを反転すると、マウスホイールを上に回すと、メニューが下に移動し、下に回すと、メニューが上に移動します。

入力とウィジェットを相互変換する項目のサブメニュー化
Node widget/input conversion sub-menusは、ノードのコンテキストメニュー(ノード上で右クリックして表示されるメニュー)のウィジェットを入力に変換(Convert Widget to Input)、または入力をウィジェットに変換(Convert Input to Widget)する項目をサブメニュー化する項目になります。

この機能を有効化(チェックボックスにチェックをいれる)すると、入力とウィジェットの変換する項目がサブメニューとしてまとめられます。この機能を無効化(チェックボックスのチェックを外す)と、項目はコンテキストメニューのトップに配置されます。

ノードの提案数の変更
Number of nodes suggestions(ノード提案数)は、ノードの入力または出力から線を伸ばした際に表示されるノードの数を決定する項目です。初期値は5で、最大で100まで設定できます。

ノードの提案とは、入力または出力をドラッグで接続線を伸ばし、キャンバスの適当なところでドロップすると、入力または出力元のノードに合うノードを提案してくれる機能のことです。

ノードの提案数が5の場合は、ここに表示されるノードの数が5個になり、ノードの提案数が10の場合は、表示されるノードの数が10個になります。

ワークフローのクリア時の確認の有無
Require confirmation when clearing workflowは、ワークフローのクリア時に、即時クリアするのではなく、確認ダイアログを表示し、ユーザーの確認が取れてからクリアを実行する機能を有効化する項目になります。

ワークフローのクリアは、メニューの「Clear」で実行可能です。クリアは、キャンバス上のノードを全て削除し、真っ新な状態にする機能です。

この機能が無効化されている(チェックボックスのチェックが外れている)場合は、ユーザーへの確認なしで即座にワークフローがクリアされます。この機能が有効化されている(チェックボックスにチェックが入っている)と、下図のようにユーザーへの確認ダイアログが表示され、「OK」を選択することでクリアが実行されるようになります。

キャンバスポジションの保存の有効化
Save and restore canvas position and zoom level in workflowsは、ワークフローの保存時に、キャンバスの表示状態(ズームアップ/ダウン、表示位置)も合わせて保存する機能を有効化する項目です。

例えば、KSamplerノードにズームアップした状態でワークフローを保存したとします。次に、保存時とキャンバスの状態が変わっている状態で保存したワークフローを読み込みます。そうすると、保存時と同様にKSamplerノードにズームアップした状態でキャンバスが表示されます。

メニュー位置の保存
Save menu positionは、メニュー位置の保存を有効化する項目です。通常は、ComfyUIをリロードや再起動すると、メニューの位置がデフォルトの位置に戻ってしまいますが、この機能を有効化していると、メニューの配置を記憶し、ComfyUIをリロードや再起動しても、最後に配置した場所でメニューが表示されます。

この機能が無効化されている(チェックボックスのチェックが外れている)場合は、リロードするとデフォルトの位置にメニューが戻ります。この機能が有効化されている(チェックボックスにチェックが入っている)と、リロードしても以前の位置を保持するようになります。

以上で、ComfyUI設定完全ガイドを終わります!
ものすごいボリュームで前後編でお送りする形になりましたが、マスターできましたでしょうか!?
画像生成AI「ComfyUI」マスターPlan
画像生成AI「Stable Diffusion」特に「ComfyUI」を中心としたプロ向け映像制作・次世代の画像生成を学びたい方に向けたプランです。最新・実用的な記事を優先して、ゼロから学ぶ「ComfyUI」マガジンからまとめて購読できます。 メンバーシップ掲示板を使った質問も歓迎です。
- メンバー限定の会員証が発行されます
- 活動期間に応じたバッジを表示
- メンバー限定掲示板を閲覧できます
- メンバー特典記事を閲覧できます
- メンバー特典マガジンを閲覧できます
- 動画資料やworkflowといった資料への優先アクセスも予定
ゼロから学ぶ「ComfyUI」マガジン
https://note.com/aicu/m/md2f2e57c0f3c
マガジン単体の販売は1件あたり500円を予定しております。
2件以上読むのであればメンバーシップ参加のほうがお得です!というのもメンバーシップ参加者にはもれなく「AICU Creator Union」へのDiscordリンクをお伝えし、メンバーオンリー掲示板の利用が可能になります。
https://note.com/aicu/membership/boards/61ab0aa9374e/posts/db2f06cd3487?from=self
もちろん、初月は無料でお試しいただけます!
毎日新鮮で確かな情報が配信されるAICUメンバーシップ。
退会率はとても低く、みなさまにご満足いただいております。
✨️オトクなメンバーシップについての詳細はこちら
この記事の続きはこちらからhttps://note.com/aicu/n/n20d7f1c7c6aa
Originally published at https://note.com on Aug 21, 2024.