POST リクエストでエンドポイント https://api.stability.ai/v2beta/3d/stable-fast-3d を呼び出してください。 Colabのサンプルコードより
#@title Stable Fast 3D#@markdown - Drag and drop image to file folder on left#@markdown - Right click it and choose Copy path#@markdown - Paste that path into image field below#@markdown <br><br>
image = "/content/cat_statue.jpg" #@param {type:"string"}
texture_resolution = "1024" #@param ['512', '1024', '2048'] {type:"string"}
foreground_ratio = 0.85 #@param {type:"number"}
host = "https://api.stability.ai/v2beta/3d/stable-fast-3d"
response = image_to_3d(
host,
image,
texture_resolution,
foreground_ratio
)
# Save the model
filename = f"model.glb"
with open(filename, "wb") as f:
f.write(response.content)
print(f"Saved 3D model {filename}")
# Display the result
output.no_vertical_scroll()
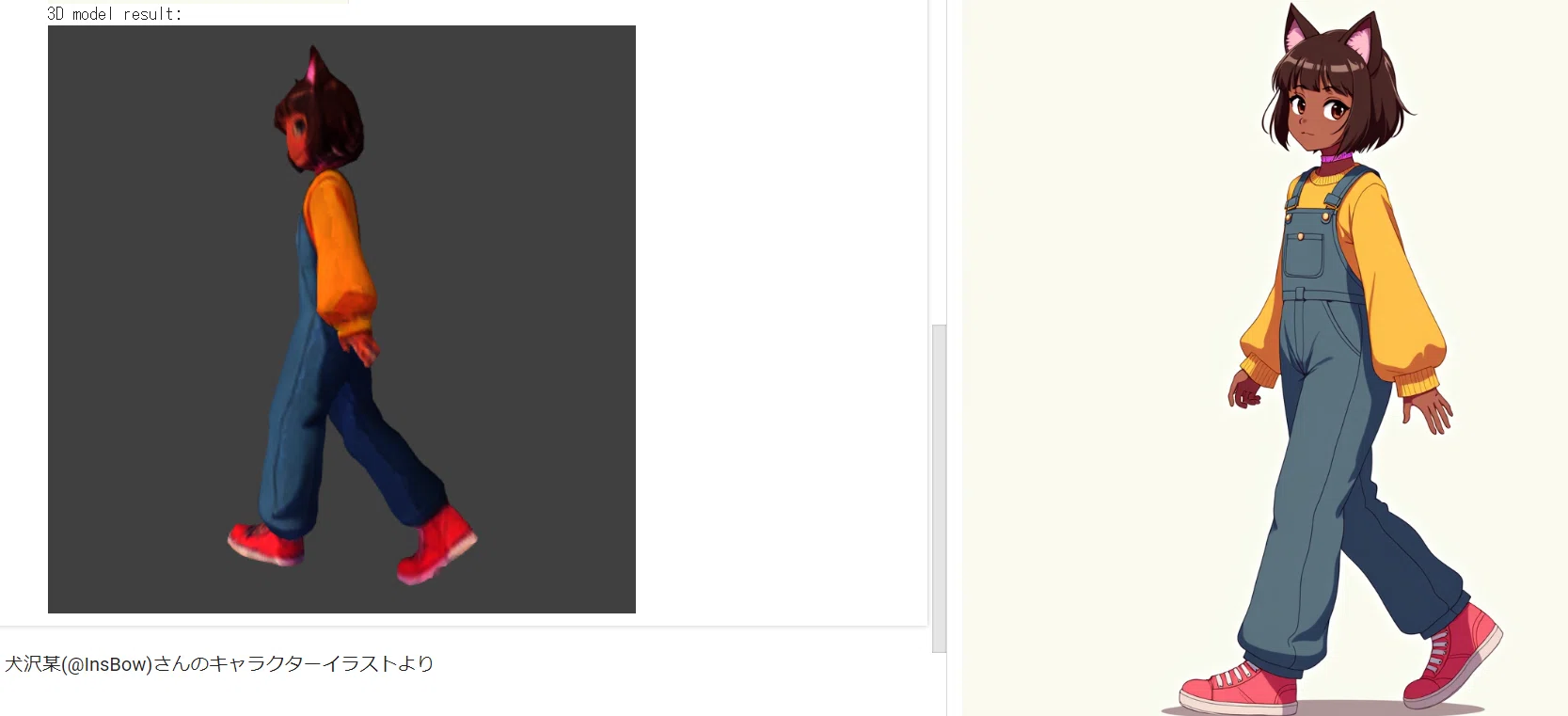
print("Original image:")
thumb = Image.open(image)
thumb.thumbnail((256, 256))
display(thumb)
print("3D model result:")
display_glb(filename)
リクエストのヘッダーには、authorization フィールドに API キーを含める必要があります。リクエストの本文は multipart/form-data でなければなりません。
Stable Fast 3Dは、TripoSRを基にした重要なアーキテクチャの改善と強化された機能により、単一の画像からわずか0.5秒で高品質な3Dアセットを生成します。これはゲームやVRの開発者、リテール、建築、デザイン、およびその他のグラフィック集約型の分野の専門家に役立ちます。
Stable Video 4D
Stable Video 4Dは、単一の動画をアップロードすることで、8つの視点からダイナミックな新視点動画を受け取ることができるモデルです。単一のオブジェクト動画を複数の新視点動画に変換し、約40秒で8つの視点から5フレームの動画を生成します。カメラアングルを指定することで、特定のクリエイティブニーズに合わせて出力を調整できます。これにより、新たなレベルの柔軟性と創造性が提供されます。
SV3Dは、Stable Video Diffusionのパワーを活用し、斬新なビュー合成において優れた品質と一貫性を保証することで、3D技術における新たなベンチマークを設定します。このモデルには2つの異なるバリエーションがあります: SV3D_uは単一画像から軌道動画を生成し、SV3D_pは単一画像と軌道画像の両方からフル3D動画を生成するための強化された機能を提供します。
また公式情報として提供されているStability AI 公式のAPIガイド、そしてサンプルに散りばめられたプロンプトテクニックを読むことも重要なヒントになります。さらにコミュニティの開発者や探求者による情報も重要なヒントがあります。大事なポイントは、噂や推測でなく、自分で手を動かして、それを検証しなが「モデルと対話」していくことです。実用的で再現可能な実験手法です。ここでは、いくつかの実践的な例や実験手法を通して、最新のStable Diffusion 3時代の文法や表現力を引き出すコツをお伝えします。
Stability AI API で提供されている各種モデル(Ultra, Core, SD3Large等)は、上記のSD3Mと同じではなく、上位のSD3を使ってより使いやすくトレーニングされたモデルになっています。 前回のポイントを復習しながら、実際に手を動かしながら理解を深めてみたいと思います。同じプロンプト、同じシードを設定すると同様の結果画像が出力されますので、是非お手元で試してみてください。
過去、Stable Diffusion 1.x時代、Stable Diffusion XL (SDXL)時代に画像生成界隈で言及されてきたプロンプトの常識として「クオリティプロンプト」がありました。例えば、傑作(masterpiece)、高クオリティ(high quality, best quality)、非常に詳細(ultra detailed)、高解像度(8k)といった「定型句」を入れるとグッと画質が上がるというものです。これは内部で使われているCLIPやモデル全体の学習に使われた学習元による「集合知(collective knowledge/wisdom of crowds/collective knowledge)」なのですが、「それがなぜ画質を向上させるのか?」を説明することは難しい要素でもあります。 Stability AI APIでも上記のクオリティプロンプトは効果があり、意識して使ったほうが良いことは確かですが、過去と同じ使い方ではありません。 実験的に解説してみます。
ultra detailed, hires,8k, girl, witch, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, fantasy, vivid color, noon, sunny
上記のプロンプトをクオリティプロンプトとしての「ultra detailed, hires, 8k,」を変更して、同じシード(seed:39)を使って Stability AI Generate Ultraによる比較をしてみました。
▼(seed:39), Stability AI Generate Ultraによる比較
「girl, witch, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, fantasy, vivid color, noon, sunny」
▼「girl, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, vivid color, noon, sunny」(seed:39) Stability AI Generate Ultraによる生成
▼「girl, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, vivid color, noon, sunny」(seed:40) Stability AI Generate Ultraによる生成
What you wish to see in the output image. A strong, descriptive prompt that clearly defines elements, colors, and subjects will lead to better results. To control the weight of a given word use the format (word:weight), where word is the word you’d like to control the weight of and weight is a value between 0 and 1. For example: The sky was a crisp (blue:0.3) and (green:0.8) would convey a sky that was blue and green, but more green than blue.
▼(photoreal:0.5), girl, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, noon, sunny (seed:40)
▼(photoreal:0.5), girl, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, noon, sunny (seed:40)
▼(photoreal:0.1), girl, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, noon, sunny (seed:40)
上手くフォトリアル-アニメ度を制御できました。
逆に、1を超えて大きな値をいれるとどうなるでしょうか。
▼(photoreal:2), girl, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, noon, sunny (seed:40)
▼(photoreal:1) a 10 years old child looks (girl:0.5) (boy:0.5), black robe, hat, long silver hair, sitting, smile, looking at viewer, flower garden, blue sky, castle, noon, sunny (seed:40)
(photoreal:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands-on-own-cheeks:1), black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, noon, sunny (seed:39)
(photoreal:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands on own cheeks:1), black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, noon, sunny (seed:39)
さきほどのプロンプトから「looking at viewer, full body」を外して「(from side:1)」を入れてみます。
▼(photoreal:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands on own cheeks:1), black robe, hat, long silver hair, sitting, smile, (from side:1) ,flower garden, blue sky, castle, noon, sunny (seed:39)
▼(photoreal:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands on own cheeks:1), black robe, hat, long silver hair, sitting, smile, (from side:1), (face focus:1) ,flower garden, blue sky, castle, noon, sunny (seed:39)
いい感じに顔に注目が当たりました。さらに目線をがんばってみたい。
▼(photoreal:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands on own cheeks:1), black robe, hat, long silver hair, sitting, smile, (from side:1), (eyes focus:1) ,flower garden, blue sky, castle, noon, sunny (seed:39)
顔や目だけでなく、指にも気遣いたいのでバランスを取っていきます。
▼(photoreal:1) (from side:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands on own cheeks:1), black robe, hat, long silver hair, sitting, smile, (finger focus:0.5), (eyes focus:0.5) ,flower garden, blue sky, castle, noon, sunny (seed:39)
良いプロンプトができました。 念のため、シードも複数で試しておきますね。
▼(photoreal:1) (from side:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands on own cheeks:1), black robe, hat, long silver hair, sitting, smile, (finger focus:0.5), (eyes focus:0.5) ,flower garden, blue sky, castle, noon, sunny Seed:40
指もいいかんじですね
▼(photoreal:1) (from side:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands on own cheeks:1), black robe, hat, long silver hair, sitting, smile, (finger focus:0.5), (eyes focus:0.5) ,flower garden, blue sky, castle, noon, sunny Seed:41
講座内容はAICU mediaで人気の日々お送りしている生成AIクリエイティブの情報、画像生成AIの歴史や文化、GPU不要・Macでも安心な環境構築、Google Slidesを使ったオリジナルツール、そして「超入門 Stability AI API」でもお送りしている「Stability AI API」を使って基礎の基礎から丁寧に学ぶ「基礎編」、さらに美麗なファッションデザインを自分で制作する「応用編」、広告業界やクリエイティブ業界にとって気になる「広告バリエーション」を生成AIだけで制作する「活用編」、そして画像生成AIにおける倫理など広範になる予定です。