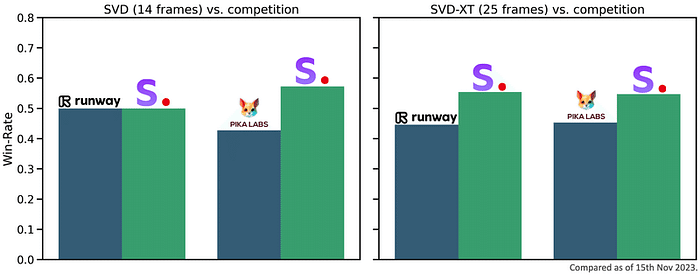
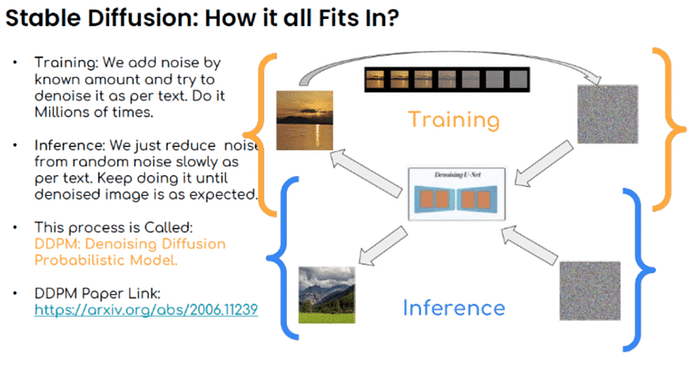
この記事では、画像とプロンプトをもとにして新たな画像を生成する『image-to-image』について解説します。
image-to-imageとは
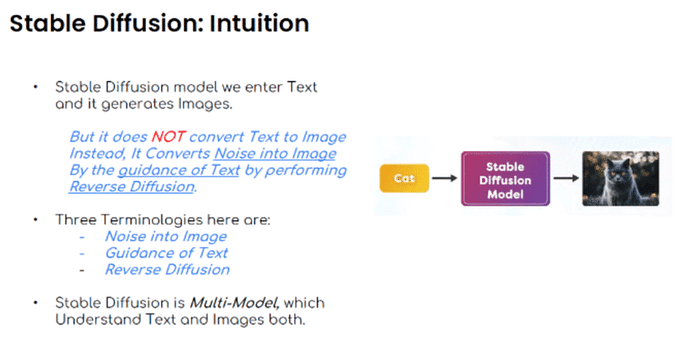
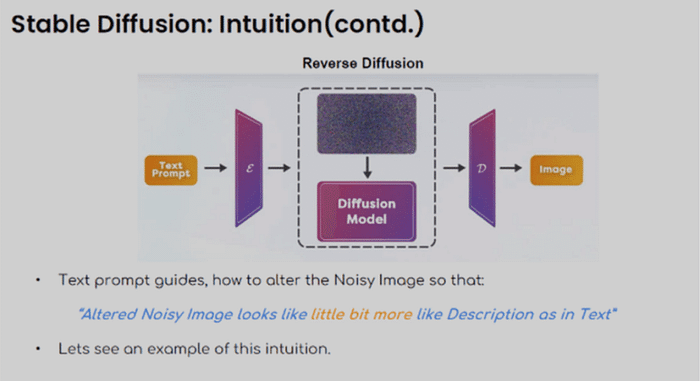
『image-to-image』(以下『i2i』)とは、画像とテキストプロンプトをもとにして、新たな画像を生成する方法のことです。これにより、テキストのみでは伝えにくかった細かい雰囲気や色味などが再現しやすくなります。また、t2tで生成した画像の一部分のみの修正も行うことができます。
画面上部のメニューの左から2番目の『img2img』を選択することで使用できます。

i2iには、『img2img』『Sketch』『Inpaint』『Inpaint scketch』『Inpaint upload』の5種類の機能があります。順番に試してみましょう。
img2imgの使い方
まず最初に、『img2img』です。これは、指定した画像とプロンプトをもとに全く別の新たな画像を生成する機能です。実際に試してみましょう。
まず、t2tで生成した画像を用意します。
モデル blue_pencil (今回はblue_pencil-XL-2.9.0を使っています)
プロンプト masterpiece, best quality, ultra detailed, 1girl
ネガティブプロンプト worst quality, low quality, normal quality, easynegative

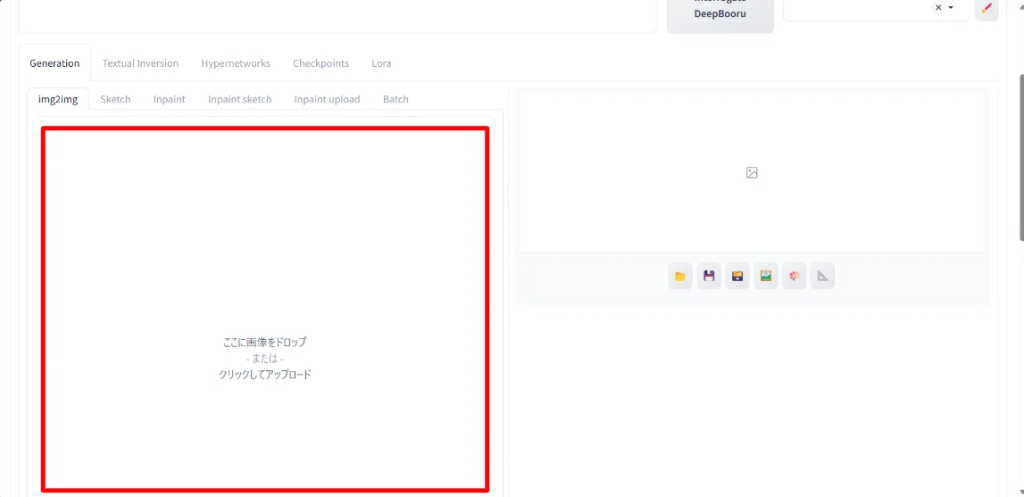
これを赤枠内にドラッグアンドドロップ、または枠内をクリックしてフォルダから選択してアップロードします。

まずは設定は何も変えずに生成してみます。

生成されました。確かに雰囲気が似ていますね。
では、プロンプトを指定してみましょう。t2tの際と同じようにプロンプトを入力します。
プロンプト masterpiece, best quality, ultra detailed
ネガティブプロンプト worst quality, low quality, normal quality, easynegative,

先ほどよりハイクオリティで、もとのイラストの雰囲気を残したイラストになりました。
では、プロンプトで少し女の子の見た目を変えてみましょう。プロンプトに『smile』を追加してみます。

色味や雰囲気はそのままに、笑顔の女の子を生成することができました。
このように、img2imgでは、画像とプロンプトをもとにして新しいものを生成することができます。
では、細かい設定を見ていきましょう。これは他のi2iの機能でも共通して使用します。

① Resize mode
生成する画像のサイズを変えた時の(④)、元の画像との差の補完方法です。生成する画像の横幅を2倍にし、それ以外の条件を揃えて比較してみましょう。
元画像

Just resize
元画像をそのまま引き伸ばします。

Crop and resize
縦横比を保ったまま、一部を切り取り拡大します。

Resize and fill
足りない部分を生成し補完します。

Just resize(latent upscaler)
『Just resize』を、異なるアップスケーラーを用いて行います。

このように、画像の補完方法が全く異なるので、目的に応じて適したものを選びましょう。
②Sampling method
t2tと共通の設定です。ノイズを除去し画像を生成する過程のアルゴリズムの種類を選択します。t2tの際と同じで、デフォルトのDPM++ 2M Karrasを使うことをおすすめします。
③Sampling steps
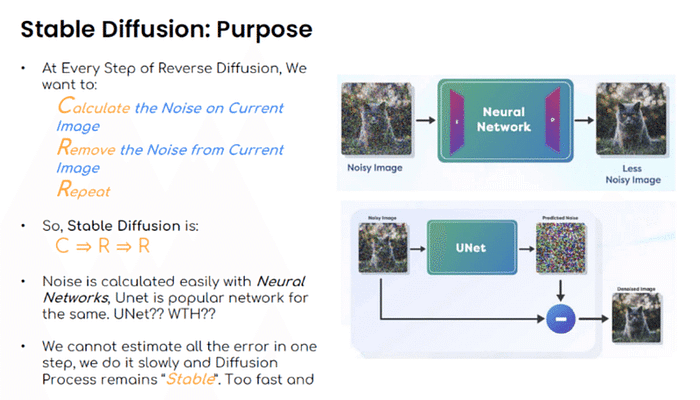
こちらもt2tでも使う設定です。ノイズを除去する回数を指定します。詳しくはC3-コラムで解説しています。
④Resize to/Resize by
生成する画像のサイズを指定します。『Resize to』を選択すると縦横のサイズを指定でき、『Resize by』を選択すると拡大縮小する倍率を指定することができます。
⑤Batch count
t2tと共通の設定。指定した枚数の画像を順番に生成します。
⑥Batch size
t2tと共通の設定。指定した枚数の画像を同時に生成します。
⑦CFG Scale
t2tと共通の設定。生成画像をどれだけプロンプトに従わせるかを調節します。
⑧Denoising strength
生成画像をどの程度元画像に近づけるかを設定します。
Denoising strengthの使い方
ここからは、先ほどの⑧『Denoising strength』というパラメーターについて実験と解説をしていきます。これは、img2imgの画像をアップロードする箇所の下部にあるメニューで設定する数値です。

『Denoising strength』は、元の画像と生成する画像にどれだけ差をつけるかを表します。デフォルトは0.75ですが、0に近づくと元画像に忠実に、1に近づくと元画像とは違う画像になります。実際にi2iで画像を生成して比べてみましょう。
まず、t2iで画像を生成します。
モデル bluepencil
プロンプト masterpiece, best quality, ultra detailed, 1girl,
ネガティブプロンプト worst quality, low quality, normal quality, easynegative,

これをi2iのX/Y/Z plotで、『Denoising』の数値を変えて生成します。

これらを比較すると、Denoising:0.3のイラストは元のイラストとほとんど同じですが、Denoising:1.0のイラストは、女の子の服装、髪色、背景がかなり変わっていることがわかります。このように、Denoisingの値は小さいほど元のイラストと似たものになり、大きいほど元のイラストとの差が大きくなります。
続きはこちら!
https://note.com/aicu/n/n853810115170
https://note.com/aicu/n/n65145ad4f762
https://note.com/aicu/n/n0ce22c439af7
※本ブログは発売予定の新刊書籍に収録される予定です。期間限定で先行公開中しています。
メンバー向けには先行してメンバーシップ版をお届けします
Stable Diffusionをお手軽に、しかもめっちゃ丁寧に学べてしまう情報をシリーズでお送りします。
メンバーは価値あるソースコードの入手や質問、依頼ができますので、お気軽にご参加いただければ幸いです!
https://note.com/aicu/membership/join
この下にGoogle Colabで動作する「AUTOMATIC1111/Stable Diffusion WebUI」へのリンクを紹介しています。
メンバーシップ向けサポート掲示板はこちら!応援よろしくお願いします!
https://note.com/aicu/membership/boards/61ab0aa9374e/posts/7cab00942b22?from=self
この記事の続きはこちらから https://note.com/aicu/n/n08ebe0637a41
Originally published at https://note.com on Jan 5, 2024.