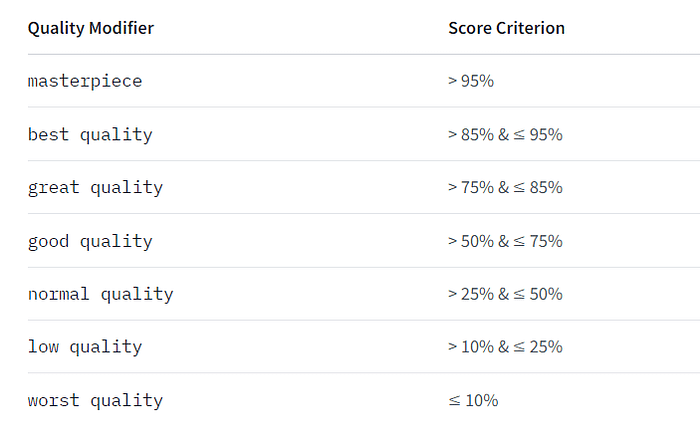
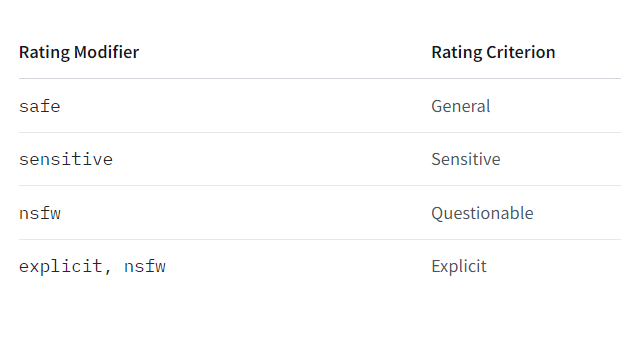
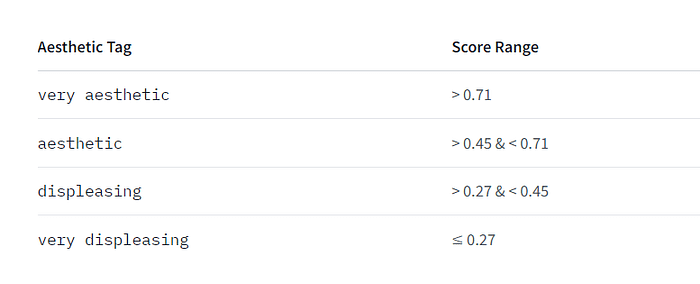
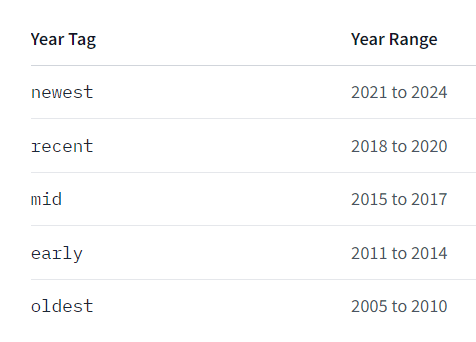つくる人をつくる!AICU mediaのしらいはかせです
先日、APIが先行して公開された Stable Diffusion 3ですが、色々試していたらわりと簡単にコマンドラインでも、Google Apps Scriptでも Stable Diffusion 3のパワフルな画像生成機能を利用できることがわかったので紹介いたします。
ちょっとした画像を生成するアプリを開発するのに便利です。
Stability AI の API キーの入手
まずは Stability AI のプラットフォームでAPIキーを入手しましょう。
https://platform.stability.ai/
右上のアカウントアイコンから「API Keys」を確認できます。
作成したらクリップボードにコピーします。
0.0065USD=約1円ぐらいです。
curlコマンドで使う Stable Diffusion 3
Windowsで標準的にインストールされているコマンドラインツール「curl」を使ってAPIを叩くことができます。まずはこれを使って試してみましょう。
curl -f -sS "https://api.stability.ai/v2beta/stable-image/generate/sd3" -H "authorization: Bearer sk-????" -H "accept: image/*" -F prompt="Lighthouse on a cliff overlooking the ocean" -F output_format="jpeg" -o "./lighthouse.jpeg"
分解して解説するとこんな感じです。
curl -f -sS “https://api.stability.ai/v2beta/stable-image/generate/sd3→SD3のAPIエンドポイントです。v2betaとあるので変更されるかも?
-H “authorization: Bearer sk-????” -H “accept: image/*” -F
→ベアラーのあとの sk-???? のところにAPIキーを貼り付けてください。
prompt=”Lighthouse on a cliff overlooking the ocean” -F
→ここがプロンプトです
output_format=”jpeg” -o “./lighthouse.jpeg”
→ここが出力ファイル形式です。Webp形式なんかも使えます。
うまく行かないひとは「Windows cURLインストール」などで調べてみてください。けっこういろんな方法があるのですが、自分の環境ではこんな cURL が動いてました。
curl — version
curl 8.4.0 (Windows) libcurl/8.4.0 Schannel WinIDN
Release-Date: 2023–10–11
Protocols: dict file ftp ftps http https imap imaps pop3 pop3s smtp smtps telnet tftp
Features: AsynchDNS HSTS HTTPS-proxy IDN IPv6 Kerberos Largefile NTLM SPNEGO SSL SSPI threadsafe Unicode UnixSockets
“curl — version”とコマンドラインで打ち込むと表示されます
Google Apps Script で使う Stable Diffusion 3
これがうまく行ったら次は、Google Apps Scriptで実装します。
Google Driveを開いて、新規→その他→Google Apps Scriptで新しいスクリプトを作ります。
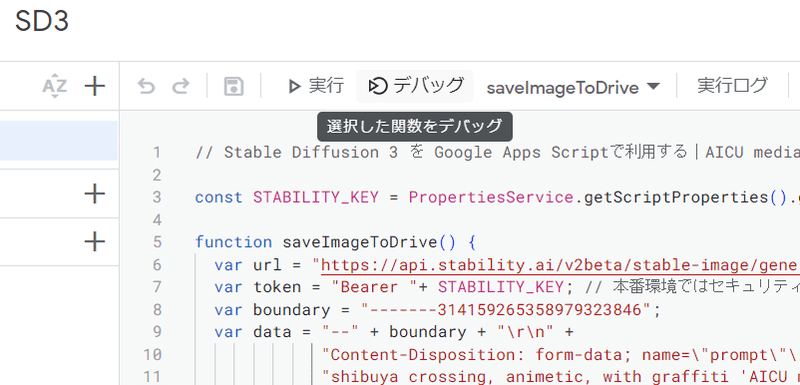
// Stable Diffusion 3 を Google Apps Scriptで利用する|AICU media @AICUai #note https://note.com/aicu/n/ne2fe8a0073b0
const STABILITY_KEY = PropertiesService.getScriptProperties().getProperty("STABILITY_KEY");
function saveImageToDrive() {
var url = "https://api.stability.ai/v2beta/stable-image/generate/sd3";
var token = "Bearer "+ STABILITY_KEY; // 本番環境ではセキュリティを考慮して保管してください
var boundary = "-------314159265358979323846";
var data = "--" + boundary + "\r\n" +
"Content-Disposition: form-data; name=\"prompt\"\r\n\r\n" +
"shibuya crossing, animetic, with graffiti 'AICU media'\r\n" +
"--" + boundary + "\r\n" +
"Content-Disposition: form-data; name=\"output_format\"\r\n\r\n" +
"png\r\n" +
"--" + boundary + "\r\n" +
"Content-Disposition: form-data; name=\"aspect_ratio\"\r\n\r\n" +
"16:9\r\n" +
"--" + boundary + "--";
var options = {
"method": "post",
"contentType": "multipart/form-data; boundary=" + boundary,
"headers": {
"Authorization": token,
"Accept": "image/*"
},
"payload": data,
"muteHttpExceptions": true
};
var response = UrlFetchApp.fetch(url, options);
if (response.getResponseCode() == 200) {
var blob = response.getBlob();
blob.setName("SD3.png");
var file = DriveApp.createFile(blob);
Logger.log('Image saved to Drive with ID: ' + file.getId());
} else {
Logger.log('Failed to fetch image: ' + response.getResponseCode());
}
}GitHubにも置いておきます。
https://github.com/aicuai/GenAI-Steam/blob/main/SD3Text2Img.gs
このコードは上記の cURL でのリクエストを単純に置き換えたものですが、APIキーをハードコードしたりGitHubに晒したくはないので、スクリプトプロパティに保存しています。
const STABILITY_KEY = PropertiesService.getScriptProperties().getProperty(“STABILITY_KEY”);
スクリプトの左側「⚙プロジェクトの設定」からスクリプトプロパティを設定することができます。
「スクリプトプロパティを追加」ボタンを押して「STABILITY_KEY」というプロパティを追加して、値として、冒頭で取得した「sk-」から始まるAPIキーを貼り付けて「スクリプトプロパティを保存」ボタンを押してコード編集に戻りましょう。
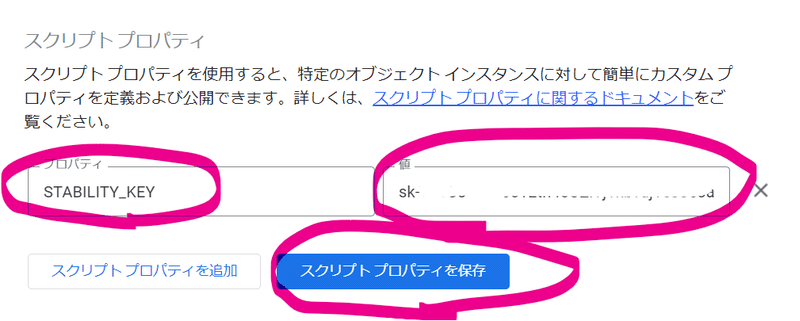
これでコードにAPIキーを保存しなくてすみますね!
さて、関数「saveImageToDrive」を実行していきます。
コードの上部にある「デバッグ」を押すと実行できますが、初回は権限設定と確認が必要です。
こんな感じの警告が出ますが、自分のGmailの権限でGoogle Driveに画像を生成するだけなので特に害はありません。左下の「SD3(安全ではないページ)に移動」を押して進めます。
ドライブへの権限を設定したらもう一度デバッグを押して実行します。
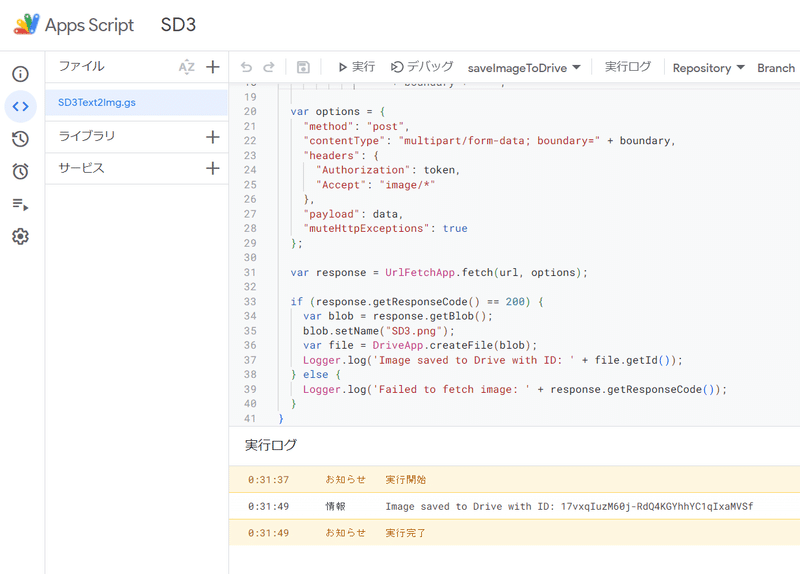
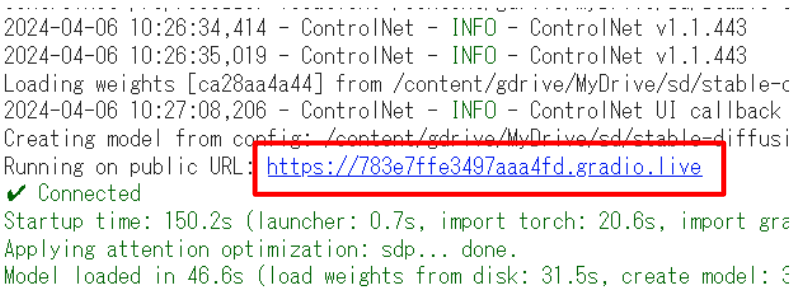
数秒で実行ログに「Image saved to Drive with ID: 1xxxxxx」と表示されたら成功です。Google Driveの「最近使用したアイテム」を見てみてください。
「SD3.png」が生成されています。
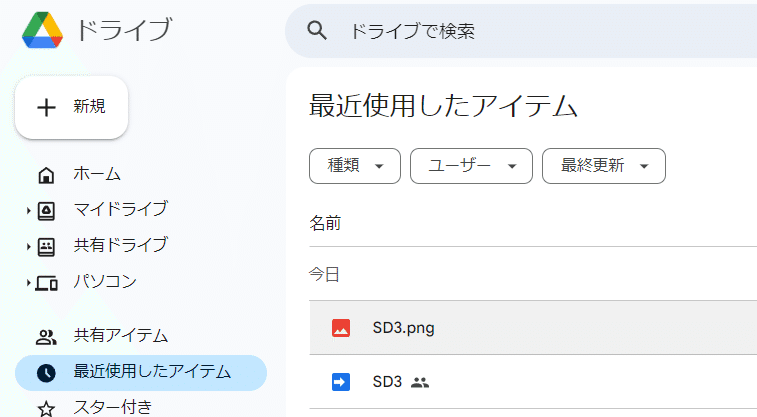



実行する度に様々な画像が生成されます。
なお、このスクリプトではプロンプトとアスペクト比を12~17行で設定しています。
“shibuya crossing, animetic, with graffiti ‘AICU media’\r\n”
→ここがプロンプトです。ちゃんと文字「AICU media」が描けています。
“Content-Disposition: form-data; name=”aspect_ratio”\r\n\r\n” + “16:9\r\n”
→縦横比「16:9」を指定しています。1:1の場合は1024×1024、16:9にした場合は 1344×768 の画像が生成されました。
APIマニュアルはこちら
https://platform.stability.ai/docs/api-reference#tag/Generate
せっかくなので翻訳していきます。
prompt プロンプト:必須
文字列 [ 1 … 10000 ] 文字
出力画像に表示したい内容。要素、色、被写体を明確に定義した、強く説明的なプロンプトがより良い結果を導きます。
aspect_ratio アスペクト比:文字列
デフ ォ ル ト : 1:1
列挙 : 16:9 1:1 21:9 2:3 3:2 4:5 5:4 9:16 9:21
生成画像のアスペクト比を制御します。
mode モード:文字列 (生成モード)
デフォル ト : text-to-image
「text-to-image」か「image-to-image」(画像パラメータ が必要かどうか)を制御します。
text-to-image
このモー ド では、 必須パラメータ は prompt だけです。このモードでは、生成される画像の縦横比を制御するために、aspect_ratioパラメータをオプションで使用することができます。
image-to-imageモードでは、さらに2つのパラメータを指定する必要があります: image — ランダムノイズの代わりに、生成の開始点として使用されます。 strength — 画像が拡散プロセスに与える影響を制御するために使用されます。また他の指定できるパラメータもかわります。
negative_prompt
文字列 <= 10000文字
出力画像で見たくないものを説明するテキスト。これは高度な機能です。
このパラメータは sd3-turbo では動作しません。
model モデル:文字列
デフォルト: sd3
列挙型: sd3 sd3-turbo
生成に使用するモデル。
sd3 は生成あたり 6.5 クレジットを必要とします。
sd3-turbo は1生成あたり4クレジット必要です。
★100クレジット=1USDです。だいたい10円ぐらいです。安っ!
seed シード: 数値
[ 0 .. 4294967294 ]。
デフォルト: 0
生成の’ランダム性’を導くために使用される特定の値。(このパラメータを省略するか、0を渡すとランダムなシードを使用します)。
output_format 出力形式
文字列
デ フ ォル ト : png
列挙型: jpeg png
生成画像のコンテントタイプを指定します。WebPも使えるようです。
Image to Image、アップスケール、そしてエディット機能、さらに「Control」と書かれた機能がドキュメントに存在します。
Stability AI の 画像サービスには、4つのカテゴリがあります。
生成
最高のテキスト画像生成サービスです。これらのサービスは、Stability AIが提供する最新のStable Diffusionモデルを活用し、専門家による微調整とマイクロサービスをワークフローに組み込んでいます。その中でも、Stable Image Coreは、迅速なエンジニアリングを必要とせず、多様なスタイルで高品質の画像を得ることができるフラッグシップサービスです。
アップスケール
標準的で昔からあるアップスケールから、画像を4Kの傑作に変えるクリエイティブモードまで、クラス最高の画像アップスケールです。中でもCreative Upscaleは、低画質入力からフォトリアリスティックな画像を作成するためのフラッグシップの手法です。
エディット
マスク(生成的塗りつぶし)や文字によるインペイントを含む、最も効果的なAIベースの画像編集サービス。背景除去などの基本的なツールだけでなく、商品配置や広告用のニッチなツールも含まれています。
コントロール(まだ未公開)
最高の画像から画像へのサービス。プロンプト、マップ、その他のガイドが必要な場合があります。これらのサービスは、ControlNetsやStable Diffusionモデルに基づいて構築された同様の技術を活用しています。
色んな機能が出てきて楽しみです。
しかも1生成あたり6~10円となると気軽に使えますね。
本記事のGoogle Apps Scriptでの活用について、 X(Twitter)@AICUai でご感想いただければ幸いです。色々開発してみたいと思います。
AICU Inc.は Stability AI 公式パートナーです。
様々なアプリ開発のご相談も承っております!
https://corp.aicu.ai/ja/stability-ai
https://corp.aicu.ai/ja/stability-ai-membership
Originally published at https://note.com on April 23, 2024.




























![[保存版] Animagine XL 3.1 生成比較レポート](https://ja.aicu.ai/wp-content/uploads/2024/07/image-29.png)