ついにユーザー登録が再開された「Sora」のクイックスタートガイドです。
初期設定
OpenAI「Sora」は単独のサイトにて提供されています。
まず https://sora.com/ に行きましょう。
お使いのGmailアカウントでサインアップ(ユーザー登録)できます。ChatGPTで有料契約を持っているアカウントを使ってログインすることをおすすめします。新規ユーザーの場合、生年月日の入力が必要です。

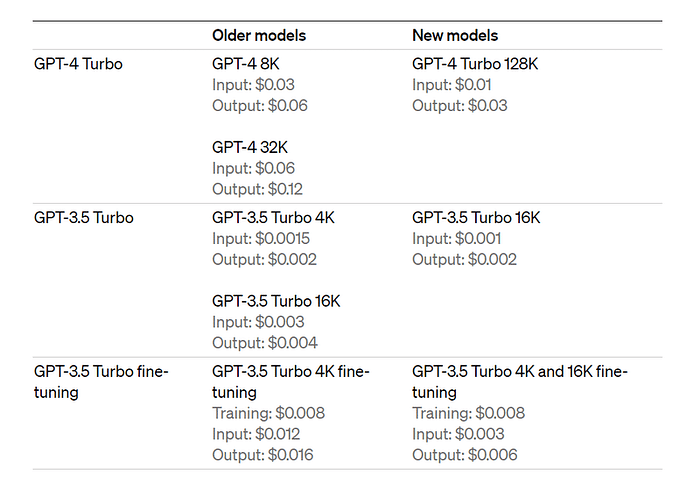
プランの選択
ChatGPT Plus ($20/月)もしくは ChatGPT Pro($200/月)が選べます。
いきなり高い方を選ぶひとはいませんね!
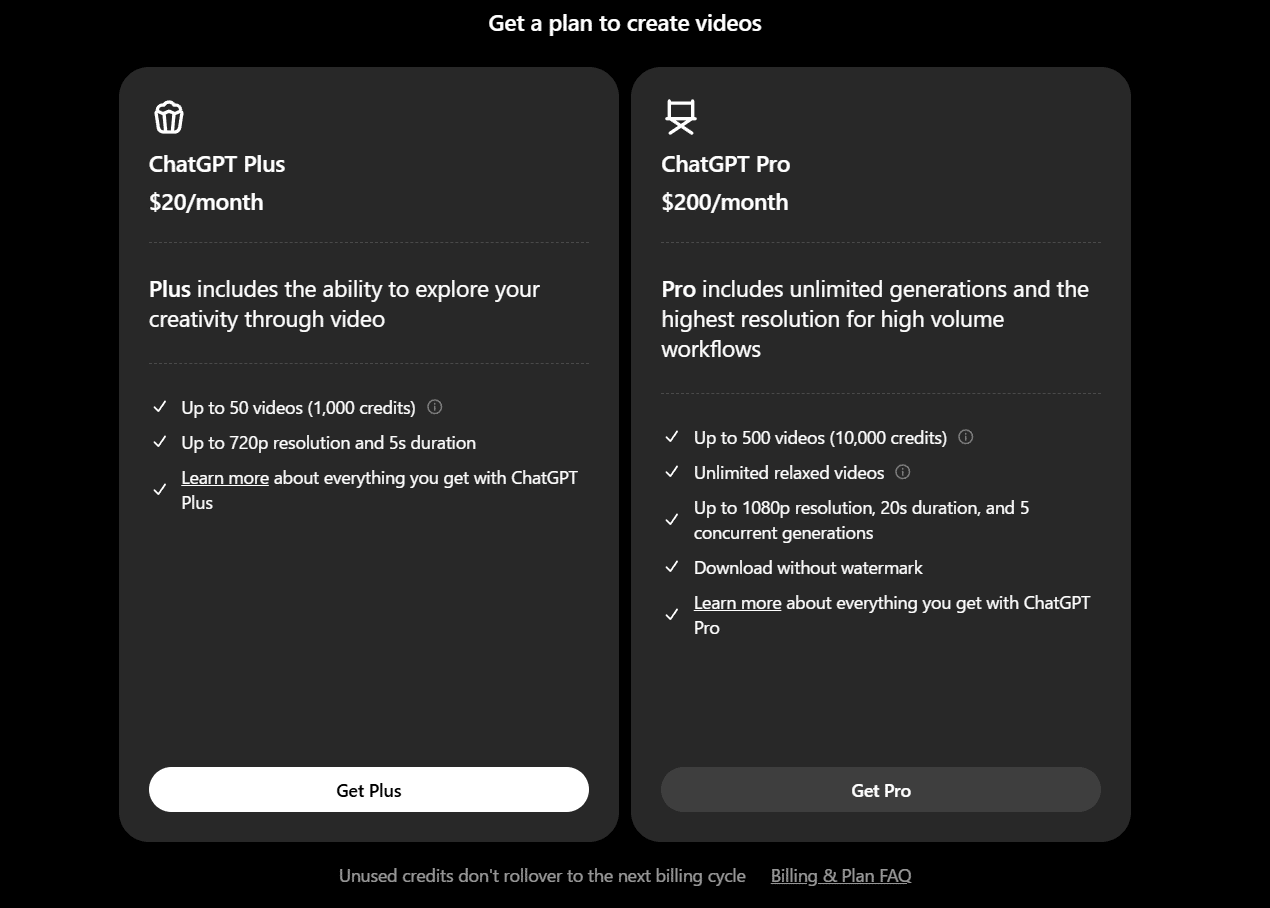
すでにChatGPT Plusに加入済みの場合はこのように「Subscribed」と表示されますので「Continue」を選びましょう。
ユーザーネームの指定
3文字以上で設定できます。

ユーザーネームの指定がおわれば利用できます。
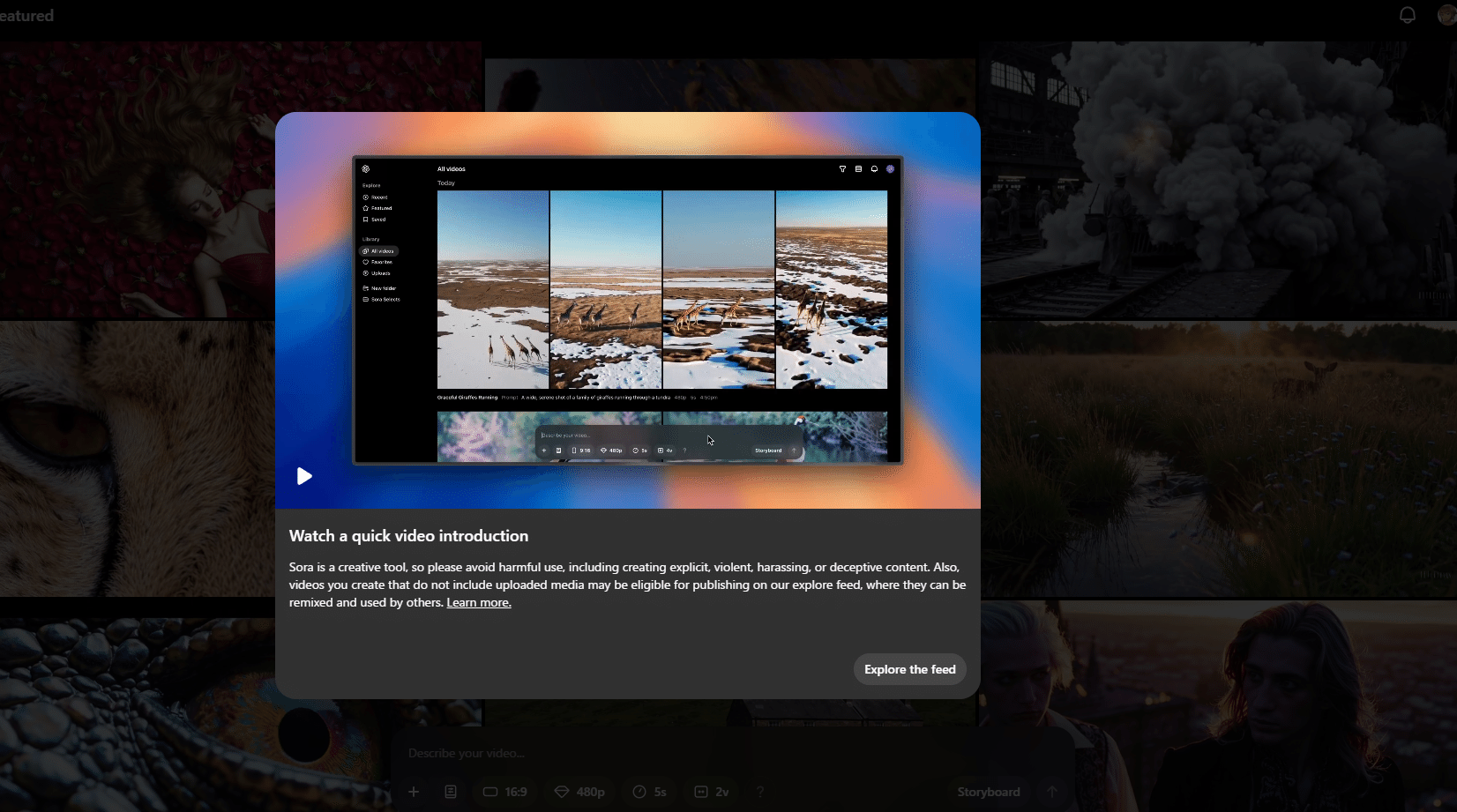
「Create Video」と「Storyboard」
下部にプロンプトを入れる場所があります。ここに文字を入れれば動画が生成されるという仕組みです。実は日本語が使えますが、細かい制御をしようと思ったら英語と日本語をうまく使ったほうが良いです。
縦横比や解像度、長さ、同時に生成する動画の本数以外に、
「Create Video」と「Storyboard」があります。

まずはCreate Videoで「Skydiving by Miku」を生成してみます。

これはAICU編集部での新モデル調査の標準手順なのですが、ここでデジタルイラスト調の初音ミクさんがたくさん出てきたら「何を学習したんだろう…?」と色々想像しなければならなくなります…。一方でこの色は初音ミクさんミク色(ブルーグリーン)ですが、キャラクターなどの名前タグや露出など、かなり慎重にキュレーションされていることが想像できます。
同様に商品名などもある程度、回避されるようです。
「Optimus robot uses Segway in downtown」とした動画がこちら。
Urban Robot on Segway♬ original sound – AICU media –
「Urban Robot on Segway」という感じに変換されています。Segwayは商品名ですが、人物や有名人ではなく、乗り物だから大丈夫なのでしょうね。
なお日本語も使えます!
生成が終わると右上に通知されます。
右上でダウンロードができます。MP4以外にGIFも選択できるのが嬉しいですね。

「Storyboard」を選ぶと、解説が表示されます。

ストーリーボードは、ビデオ内のアクション、シーケンス、タイミングを視覚化するのに役立つツールです。最終的なビデオを生成する前に、写真、ビデオ、テキストを使用して、タイムラインに沿って各ショットを説明していくことができます。
例えば「Rocketia by Elon Musk」とプロンプトに書いて「Storyboard」を実行すると…

以下の2つのプロンプトが生成されました。
①A well-dressed business figure stands confidently on a stage, a large screen behind him displays the word ‘Rocketia’ in bold letters. He gestures passionately as he speaks about the future of technology and space exploration. The audience, visible in the shadows, seems captivated by his words. The setting is a modern conference hall, with sleek design elements and ambient lighting enhancing the atmosphere of innovation and ambition. The business figure is charismatic, exuding confidence as he shares his vision.
①身なりのよいビジネスマンがステージに自信満々に立っており、背後の大きなスクリーンには「Rocketia」という文字が太字で表示されている。彼は技術と宇宙探査の未来について熱く語り、その影に隠れた聴衆は彼の言葉に魅了されているようだ。舞台は現代的な会議室で、洗練されたデザイン要素と間接照明が革新と野心の雰囲気を高めている。ビジネスマンはカリスマ性があり、ビジョンを語る際に自信をにじませている。
②The business figure points to a projection of a futuristic rocket design on the screen.
②ビジネスマンはスクリーンに映し出された未来的なロケットのデザインを指差している。
これをそのまま生成してみます。

ちょっと普通の動画になっちゃいましたので、②を鉛筆マークを押すと、更にリライト(改善)してもらえるようです。
②Suddenly, a missile falls. The transformed Iron Masked Hero is caught in the blast and flies out.
②突然ミサイルが落ちてきます。爆風に巻き込まれる周囲の中から変身した鉄仮面のヒーローが飛んでいきます。
さらに改善してもらいます。
②the shot is abrupt and intense, with a dramatic shift from anticipation to chaos. suddenly, a missile falls, captured in a dynamic wide shot. the scene shows a transformed armored hero, barely visible amidst the explosion, caught in the blast’s powerful force. the debris and fire surround him as he is sent flying out of the frame. the atmosphere is tense and shocking, switching from visionary ambition to immediate danger, leaving the previously attentive conference audience in stunned silence and confusion.
②ショットは突然で強烈、期待から混乱へと劇的に切り替わる。突然、ミサイルが落下し、ダイナミックなワイドショットで捉えられる。シーンには、爆発の真っ只中にかろうじて見える、変身した装甲ヒーローが爆発の強力な力に巻き込まれる。破片と炎が彼を取り囲み、彼はフレームから吹き飛ばされる。雰囲気は緊張感と衝撃に満ち、先見の明のある野心から差し迫った危険へと切り替わり、それまで熱心に聞いていた会議の聴衆は唖然として沈黙し、混乱する。
爆破シーンにはなりましたが、2シーンで描くには難しいですね。詰め込みすぎないように、絵コンテや映像監督としてのシナリオ対話力が鍛えられそうです。
他のユーザーの生成は「Recent」でみれます
シェアされた作品を見ているだけでも楽しいですね。

アップロード機能
メディアライブラリがあり、そちらにファイルをアップロードする機能があります。初回実行時に同意書が現れます。よく考えられたUI/UXですね。

【メディアアップロード契約】 以下の各項目のボックスにチェックを入れて、以下の内容を読んで同意したことを確認してください。
・本人の同意を得ずに人物や 18 歳未満の人物を含むメディアをアップロードしないことに同意します。
・暴力や露骨なテーマを含むメディアをアップロードしないことに同意します。
・アップロードするメディアに必要なすべての権利を有していることに同意します。
・メディアアップロードを不正に使用した場合、返金なしでアカウントが停止または禁止される可能性があります。
これは強力なツールですので、創造的に、敬意を持って使用してください。
さらに注意書きが表示されます。

【人物を含むメディア】
現在、お使いのアカウントでは、人物を含むアップロードされたメディアを使用したビデオの作成はサポートされていません。人物を含む写真またはビデオをアップロードすると、ビデオは生成されず、クレジットは請求されません。
前述の通り、人物を含むメディアについては厳しい制限が設定されているようです。「お使いのアカウントでは」と書かれている点と「ChatGPT Pro」でも解除はされないようなので、映画産業などのプロ向け用途には異なるライセンスが存在するのかもしれませんね。
Video Remix
アップロードしたビデオをリミックスしますが、あまり長い動画をアップロードしないほうがいいようです。だいたい10秒以下のクリップが良いでしょう。

今回は実験としてこちらの動画を使ってみます。
ビデオのブレンド
2つのビデオを選んでブレンドできます

トランジション、ミックス、サンプル、カスタムの4種類があり、寄与率の適用モデルを変えられるようです。
例えばカスタムにするとこんな感じ。



右側にあったビデオの要素が切り出されました。窓の外にもひとが居ます。
よく見ると巨人化している感じです。
何も考えずに融合させるのは良い結果を生みませんね…!
さて、ここからのクリエイションはアナタの版です!
AICUでは Sora オンライン動画コンテストを予定しております。
テーマはクリスマス!
気になる料金体系
https://help.openai.com/en/articles/10245774-sora-billing-credits-faq
Sora公式 – 料金とクレジットに関するFAQから Soraの利用料金とクレジットに関するよくある質問とその回答をまとめました。
クレジットとは?
- クレジットは、Soraで動画を生成するために使用されます。
- 動画生成にかかるクレジット数は、動画の品質と長さによって異なります。
動画生成に必要なクレジット数
- 解像度と長さごとの必要クレジット数
- 480p (正方形): 5秒あたり20クレジット、10秒あたり40クレジット、15秒あたり60クレジット、20秒あたり80クレジット
- 480p: 5秒あたり25クレジット、10秒あたり50クレジット、15秒あたり100クレジット、20秒あたり150クレジット
- 720p (正方形): 5秒あたり30クレジット、10秒あたり75クレジット、15秒あたり150クレジット、20秒あたり225クレジット
- 720p: 5秒あたり60クレジット、10秒あたり180クレジット、15秒あたり360クレジット、20秒あたり540クレジット
- 1080p (正方形): 5秒あたり100クレジット、10秒あたり300クレジット、15秒あたり650クレジット、20秒あたり1000クレジット
- 1080p: 5秒あたり200クレジット、10秒あたり600クレジット、15秒あたり1300クレジット、20秒あたり2000クレジット
- 複数のバリエーションを同時にリクエストした場合、2つの別々の生成リクエストを実行した場合と同じ料金が発生します。
- リカット、リミックス、ブレンド、ループ使用時の必要クレジット数
- リカット、リミックス、ブレンド、ループを使って5秒刻み以外の長さの動画を作る場合、以下のクレジットが消費されます。
- 0-5秒: 480p (正方形) は4クレジット、480pは5クレジット、720p (正方形) は6クレジット、720pは12クレジット、1080p (正方形) は20クレジット、1080pは40クレジット
- 5-10秒: 480p (正方形) は4クレジット、480pは5クレジット、720p (正方形) は9クレジット、720pは24クレジット、1080p (正方形) は40クレジット、1080pは80クレジット
- 10-15秒: 480p (正方形) は4クレジット、480pは10クレジット、720p (正方形) は15クレジット、720pは36クレジット、1080p (正方形) は70クレジット、1080pは140クレジット
- 15-20秒: 480p (正方形) は4クレジット、480pは10クレジット、720p (正方形) は15クレジット、720pは36クレジット、1080p (正方形) は70クレジット、1080pは140クレジット
- ChatGPT Proユーザーは、クレジットを消費しないリラックス動画を生成できます。リラックス動画の生成は、ChatGPT Proアカウントのクレジットが不足した際に有効になります。
各プランで付与されるクレジット数
- ChatGPT Plus:
- 最大50本の優先動画(1,000クレジット)
- 最大720pの解像度と5秒の長さ
- ChatGPT Pro:
- 最大500本の優先動画(10,000クレジット)
- 無制限のリラックス動画
- 最大1080pの解像度、20秒の長さ、5つの同時生成
- 透かしなしでダウンロード可能
- クレジットは、サブスクリプション更新の支払いが完了した時点のUTC午前0時に適用されます。支払いがUTC午前0時以降に処理された場合、クレジットは翌日のUTC午前0時に追加されます。
プランのアップグレードまたはキャンセル方法
- Soraページの右上隅にあるプロフィールアイコンをクリックし、ドロップダウンメニューから「My plan」を選択します。
- 設定メニューで「My plan」に移動し、「Manage plan」ボタンをクリックします。
- アップグレードを完了するには、「Plan type」の下の「Upgrade」ボタンをクリックします。
- 現在のプランの下にある「Cancel plan」ボタンから、プランをキャンセルすることもできます。プランをキャンセルすると、アカウント内の既存のクレジットは直ちに無効になります。
リラックス動画とは?
- ChatGPT Proでは、リラックスモードで動画を生成できます。
- リラックスモードでは、サイトのトラフィックが少ないときに完了するように動画をキューに入れることができます。
- リラックスモードは、ChatGPT Proアカウントのクレジットが不足したときに有効になります。
- リラックス動画にはクレジットは必要ありません。
- 一般的に、リラックス動画は優先動画よりも作成に時間がかかります。
追加クレジットの購入について
- 現時点では、追加クレジットをその都度購入することはできません。
- ChatGPT Plusを利用していて、Soraで使用するクレジットを増やしたい場合は、Proプランにアップグレードできます。
クレジットの繰り越しについて
- Soraのクレジットは累積されず、翌月に繰り越されません。
- クレジットは、各請求サイクルの終了時に失効します。
- 月額プランのクレジットは、請求サイクルの開始時のUTC午前0時にリセットされます。
請求日について
- 請求日は、最初にプランを開始した日であり、月額サブスクリプション料金が発生する日でもあります。
- ChatGPTプランのサブスクリプションは、サブスクリプション開始日から暦月単位で請求されます。
アカウントの削除方法
- 削除されたアカウントは復元できません。
- ChatGPTまたはOpenAIのプライバシーセンターでアカウントを自分で削除すると、アクティブな有料サブスクリプションがすべてキャンセルされます。
- 以前にOpenAIアカウントを削除した場合、同じメールアドレスで新しいアカウントを作成したり、古いアカウントを再アクティブ化したりすることはできません。
- ChatGPTでアカウントを削除するには、次の手順に従います。
- ChatGPTにサインインします。
- 右上のプロフィールアイコンをクリックします。
- 「Settings」をクリックします。
- 「Settings」で「Data Controls」をクリックします。
- 「Delete account」の下の「Delete」をクリックします。
- 過去10分以内にログインしている場合にのみ、アカウントを削除できます。過去10分以内にログインしていない場合は、再度サインインする必要があります。
- 確認画面が表示され、アカウントのメールアドレスと「DELETE」を入力フィールドに入力して、「Permanently delete my account」ボタンのロックを解除する必要があります。
- 入力が完了すると、「Permanently delete my account」ボタンのロックが解除されます。
- 「Permanently delete my account」をクリックして、アカウントを削除します。
「You do not have an account because it has been deleted or deactivated」というエラーが表示される理由
- ログインまたはアカウントを作成しようとしたときにこのエラーが表示される場合は、サインアップ/ログインに使用しようとしているメールアドレスに関連付けられたアカウントがアカウント削除されたことを意味します。
- これは、ChatGPTでアカウントを削除したか、プライバシーセンターにメールを送信して削除を依頼したために発生します。
以上、スタートガイドでした!
コンテストの募集はこちらの X@AICUai で開始予定です。
応募を楽しみにしております
Originally published at https://note.com on Dec 13, 2024.