ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
basicsr 1.4.2 requires lmdb, which is not installed.
gfpgan 1.3.8 requires lmdb, which is not installed.
clean-fid 0.1.31 requires requests==2.25.1, but you have requests 2.28.2 which is incompatible.
fastai 2.7.15 requires torch<2.4,>=1.10, but you have torch 2.4.0 which is incompatible.
torchaudio 2.3.1+cu121 requires torch==2.3.1, but you have torch 2.4.0 which is incompatible.
torchvision 0.18.1+cu121 requires torch==2.3.1, but you have torch 2.4.0 which is incompatible.
Successfully installed nvidia-cudnn-cu12-9.1.0.70 torch-2.4.0 triton-2.3.1 xformers-0.0.27.post1
Traceback (most recent call last):File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py", line 13, in <module>initialize.imports()File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/initialize.py", line 17, in importsimport pytorch_lightning # noqa: F401File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/init.py", line 34, in <module>from pytorch_lightning.callbacks import Callback # noqa: E402File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/callbacks/init.py", line 14, in <module>from pytorch_lightning.callbacks.callback import CallbackFile "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/callbacks/callback.py", line 25, in <module>from pytorch_lightning.utilities.types import STEP_OUTPUTFile "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/utilities/init.py", line 18, in <module>from pytorch_lightning.utilities.apply_func import move_data_to_device # noqa: F401File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/utilities/apply_func.py", line 29, in <module>from pytorch_lightning.utilities.imports import _compare_version, _TORCHTEXT_LEGACYFile "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/utilities/imports.py", line 153, in <module>_TORCHTEXT_LEGACY: bool = _TORCHTEXT_AVAILABLE and _compare_version("torchtext", operator.lt, "0.11.0")File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/utilities/imports.py", line 71, in _compare_versionpkg = importlib.import_module(package)File "/usr/lib/python3.10/importlib/init.py", line 126, in import_modulereturn _bootstrap._gcd_import(name[level:], package, level)File "/usr/local/lib/python3.10/dist-packages/torchtext/init.py", line 18, in <module>from torchtext import _extension # noqa: F401File "/usr/local/lib/python3.10/dist-packages/torchtext/_extension.py", line 64, in <module>_init_extension()File "/usr/local/lib/python3.10/dist-packages/torchtext/_extension.py", line 58, in _init_extension_load_lib("libtorchtext")File "/usr/local/lib/python3.10/dist-packages/torchtext/_extension.py", line 50, in _load_libtorch.ops.load_library(path)File "/usr/local/lib/python3.10/dist-packages/torch/_ops.py", line 1295, in load_libraryctypes.CDLL(path)File "/usr/lib/python3.10/ctypes/init.py", line 374, in initself._handle = _dlopen(self._name, mode)OSError: /usr/local/lib/python3.10/dist-packages/torchtext/lib/libtorchtext.so: undefined symbol: _ZN5torch3jit17parseSchemaOrNameERKSs
この Web ページのすべての入力画像は AI によって生成されたものであることに注意してください。それらの「グラウンド・トゥルース」つまり「正解の描画プロセス」は存在しません。画像生成によって生成された1枚の画像をベースに「それが描かれたであろう工程」を、まるでイラストレーターの作業配信動画(タイムラプス)のように生成しています。
変更点 feat: ミラーサイトからの huggingface ファイルのダウンロードをサポート。 chore: インターポーザーを v3.1 から v4.0 に更新 by @mashb1t in #2717 feat: ページをリロードせずに UI を再接続するボタンを追加 by @mashb1t in #2727 feat: オプションのモデルVAE選択を追加 by @mashb1t in #2867 feat: ランダムスタイルを選択 by @mashb1t in #2855 feat: アニメを animaPencilXL_v100 から animaPencilXL_v310 に更新 by @mashb1t in #2454 refactor: 再接続ボタンのラベル名を変更 by @mashb1t in #2893 feat: 履歴ログに完全な生プロンプトを追加 by @docppp in #1920 修正: 正しい border radius css プロパティを使用するようにしました by @khanvilkarvishvesh in #2845 修正: HTMLヘッダでメタタグを閉じないようにした by @e52fa787 in #2740 機能: uov 画像アップロード時に画像を自動的に記述 by @mashb1t in #1938 nsfw 画像の検閲を設定とチェックボックスで追加 by @mashb1t in #958 feat: 手順を揃えるスケジューラーを追加 by @mashb1t in #2905 lora のインラインプロンプト参照をサポート by @cantor-set in #2323 feat: sgm_uniform (lcmと同じ)に基づくtcdサンプラーと離散蒸留tcdスケジューラの追加 by @mashb1t in #2907 feat: 4step LoRA に基づくパフォーマンス Hyper SD を追加 (@mashb1t 氏による) #2812 修正: HyperSDテスト用に残っていたコードを削除しました。 feature: nsfw 画像検閲のモデル管理を最適化 by @mashb1t in #2960 feat: プログレスバーの改善 by @mashb1t in #2962 feat: インラインローラの最適化 by @mashb1t in #2967 feat: コードの所有者を @lllyasviel から @mashb1t に変更 by @mashb1t in #2948 feat: 有効なインラインローラのみを使用し、サブフォルダをサポート by @mashb1t in #2968 feature: イメージのサイズと比率を読み取り、推奨サイズを与える by @xhoxye in #2971 feature: ghcr.io 用コンテナイメージのビルドとプッシュ、docker.md の更新、その他関連する修正 by @xynydev in #2805。 利用可能なイメージを見る feat: 行末のデフォルト設定を調整 by @mashb1t in #2991 feat: image size description の翻訳を追加しました。 feat: ‘CFG Mimicking from TSNR’ の値をプリセットから読み込む by @Alexdnk in #2990 feat: ブラシのカラーピッカーを追加 by @mashb1t in #2997 feat: ほとんどの画像入力フィールドからラベルを削除 by @mashb1t in #2998 feat: クリップスキップ処理を追加 by @mashb1t in #2999 feat: UI設定をよりコンパクトに by @Alexdnk and @mashb1t in #2590
p47 【Start Stable-Diffusion】のセルを実行時 WARNING[XFORMERS]: xFormers can’t load C++/CUDA extensions. xFormers was built for: PyTorch 2.2.1+cu121 with CUDA 1201 (you have 2.3.0+cu121) Python 3.10.13 (you have 3.10.12) Please reinstall xformers というエラーが出てURLも表示されず完了しません。
読者の方からも同様のご報告を頂いております(SBクリエイティブさんありがとうございます)。
【現象2】起動には成功するが画像生成に失敗する
「Generate」ボタンを押すと以下のようなエラー表示されます。
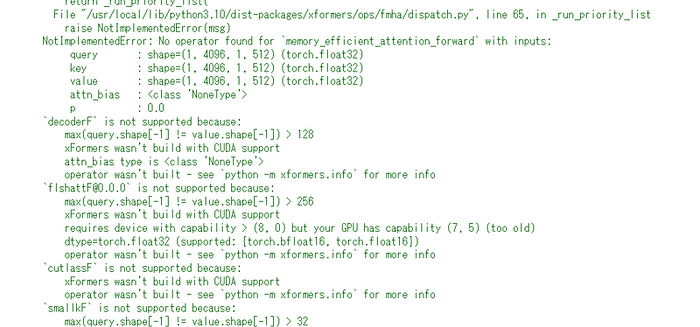
AUTOMATIC1111側にはこちらのエラーが表示されています
NotImplementedError: No operator found for `memory_efficient_attention_forward` with inputs: query : shape=(1, 4096, 1, 512) (torch.float32) key : shape=(1, 4096, 1, 512) (torch.float32) value : shape=(1, 4096, 1, 512) (torch.float32) attn_bias : <class 'NoneType'> p : 0.0 `decoderF` is not supported because: max(query.shape[-1] != value.shape[-1]) > 128 xFormers wasn't build with CUDA support attn_bias type is <class 'NoneType'> operator wasn't built - see `python -m xformers.info` for more info `flshattF@0.0.0` is not supported because: max(query.shape[-1] != value.shape[-1]) > 256 xFormers wasn't build with CUDA support requires device with capability > (8, 0) but your GPU has capability (7, 5) (too old) dtype=torch.float32 (supported: {torch.bfloat16, torch.float16}) operator wasn't built - see `python -m xformers.info` for more info `cutlassF` is not supported because: xFormers wasn't build with CUDA support operator wasn't built - see `python -m xformers.info` for more info `smallkF` is not supported because: max(query.shape[-1] != value.shape[-1]) > 32 xFormers wasn't build with CUDA support operator wasn't built - see `python -m xformers.info` for more info unsupported embed per head: 512
なお、xFormersとは、Facebook Research (Meta)がオープンソースソフトウェアとして公開しているPyTorchベースのライブラリで、Transformersの研究を加速するために開発されたものです。xFormersは、NVIDIAのGPUでのみ動作します。NVIDIAのGPUを演算基盤として動作させるためのCUDAやそのビルド時のバージョンをしっかり管理する必要があります。 https://github.com/facebookresearch/xformers
【関連】PyTorchとCUDAバージョンエラーの警告について
実はPyTorchとCUDAバージョンエラーの警告も出ています。
PyTorch 2.2.1+cu121 with CUDA 1201 (you have 2.3.0+cu121) Python 3.10.13 (you have 3.10.12)
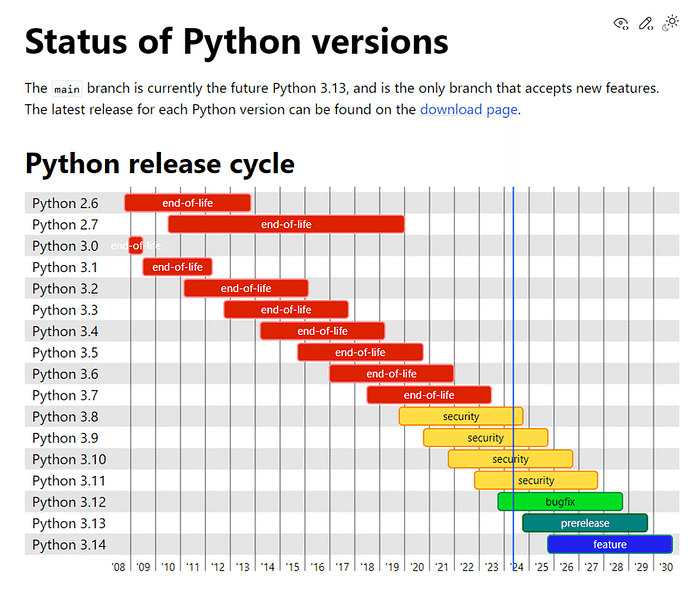
Install Python 3.10.6 (Newer version of Python does not support torch), checking “Add Python to PATH”. Python 3.10.6をインストールし、”Add Python to PATH “をチェックする。
とありますが、実際にGoogle Colab上でデフォルトで動作しているPythonは現在、Python 3.10.12です(!python — version で確認できます)。 Python3.10.6が推奨なので、だいぶ後続のバージョンを使っていることになります。この問題はGoogle Colab上でのPythonのメジャーバージョンに関する問題で、関係はありますが、文末で解説します。
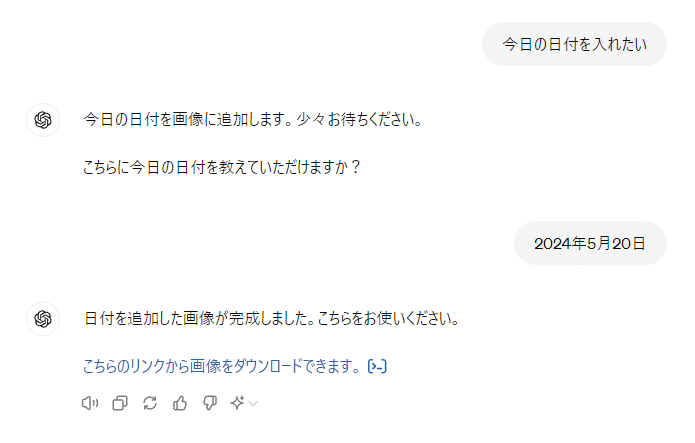
from PIL import Image, ImageDraw, ImageFont
import matplotlib.font_manager as fm
# Load the image
image_path = "/mnt/data/A_vibrant,_eye-catching_image_for_a_daily_report,_.png"
image = Image.open(image_path)
# Define the date text
date_text = "2024年5月20日"
# Get a font
# Using a default font as an example
font_path = fm.findSystemFonts(fontpaths=None, fontext='ttf')[0]
font = ImageFont.truetype(font_path, 40)
# Initialize ImageDraw
draw = ImageDraw.Draw(image)
# Define the text position and color
text_position = (image.width - 300, image.height - 70)
text_color = (255, 255, 255) # White color
# Add the date text to the image
draw.text(text_position, date_text, font=font, fill=text_color)
# Save the edited image
output_path = "/mnt/data/A_vibrant_image_with_date.png"
image.save(output_path)
output_path
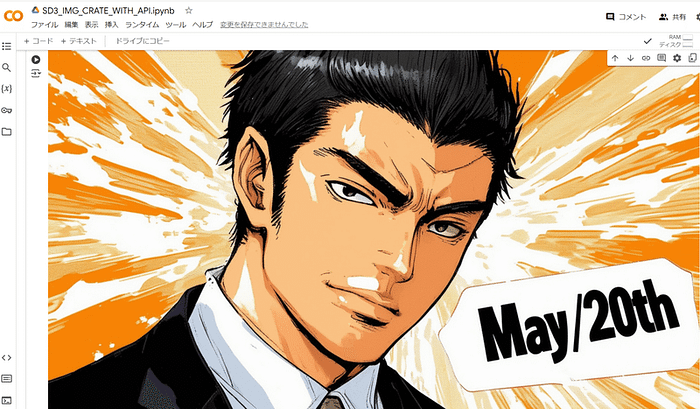
Cover illustration of the daily bulletin, a manga of a Japanese president tanned, energetic 27-year-old man, With the words “May/20th” in the lower right corner.
prompt: Cover illustration of the daily bulletin, a manga of a Japanese president tanned, energetic 27-year-old man, With the words “May/20th” in the lower right corner.
# The next line may need to be modified depending on the environment model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.float16, low_cpu_mem_usage=True, device_map="auto", trust_remote_code=True, )