こんにちわ、AICU media編集部です。
「ComfyUI マスターガイド」第8回目になります!
今回は、ComfyUIで作成したワークフローを保存し、後で呼び出すための様々な方法をご紹介します。JSONファイルとして保存する基本的な方法から、カスタムノード「ComfyUI-Custom-Scripts」を利用して画像として保存する便利な方法まで、詳しく解説します。これらのテクニックをマスターすることで、ワークフローの管理が容易になり、作業効率の向上と共同作業の促進に繋がります。
1. ワークフローの保存方法
ComfyUIで作成したワークフローを保存する方法はいくつかあります。ここでは、JSONファイルとして保存する方法と、カスタムノード「ComfyUI-Custom-Scripts」(*1)を利用して画像として保存する方法について説明します。
*1 ComfyUI-Custom-Scriptsは、様々な便利な機能を持ったカスタムノードです。ComfyUI-Custom-Scriptsの機能の詳細は、別記事で解説します。今回は、ワークフローの保存機能に焦点を当てて解説します。
1.1 JSONファイルとして保存
ワークフローをJSONファイルとして保存することで、後で簡単に呼び出すことができます。以下の手順に従ってください。
ワークフローの保存
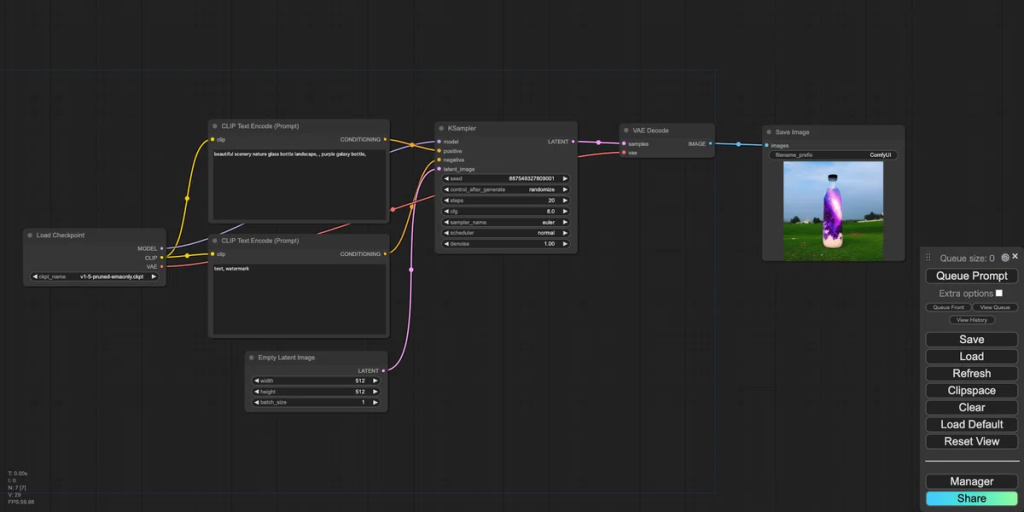
- ComfyUIのキャンバスにグラフが表示された状態を作ります。ここでは標準のグラフを表示しています。

- メニューの「Save」をクリックします。

- 保存するファイル名を入力するダイアログが表示されるので、ファイル名を入力し、「OK」をクリックします。ここでは、ファイル名を「workflow_test.json」とします。

- これで、ワークフローがJSON形式のファイルとしてダウンロードフォルダ(*2)に保存されます。
*2 保存先のフォルダは、ブラウザで設定されている保存先になります。保存先のフォルダについては、お使いになられているブラウザのヘルプページをご確認ください。
【主要なブラウザのヘルプページ】
・Google Chrome: ファイルをダウンロードする
・Microsoft Edge: ダウンロード フォルダーの場所を変更する
・Safari: MacでSafariを使用してWebから項目をダウンロードする
・Firefox: ダウンロードしたファイルを見つける方法と管理する方法
1.2 ComfyUI-Custom-Scriptsを利用して画像として保存
カスタムノード「ComfyUI-Custom-Scripts」を使用することで、ワークフローを画像として保存することができます。この方法は、視覚的にワークフローを共有したい場合に便利です。
ComfyUI-Custom-Scriptsのインストール
- まず、ComfyUI-Custom-Scriptsをインストールします。メニューから「Manager」をクリックします。

- ComfyUI Manager Menuが立ち上がります。ここで、「Custom Nodes Manager」をクリックします。

- Custom Nodes Managerが開きます。

- 上部の検索部に「comfyui-custom-scripts」と入力します。そうすると、カスタムノード一覧に「ComfyUI-Custom-Scripts」が表示されるので、「ComfyUI-Custom-Scripts」の「Install」をクリックします。

- しばらく待つと、インストールが完了します。その後、ComfyUIの再起動を求められるため、下部にある「Restart」をクリックします。

- 再起動が実行されると、ComfyUI Manager Menuが閉じ、キャンバスの画面に戻ります。再起動実行中は、画面中央に「Reconnecting…」というメッセージがダイアログで表示されますが、再起動が完了すると自動でダイアログが閉じます。ダイアログが閉じたら、ブラウザを更新してください。

- 再度Custom Nodes Managerを開き、「comfyui-custom-scripts」を検索してください。ComfyUI-Custom-ScriptsのInstall列が以下の画像のように表示されていれば、インストールが完了しています。

ワークフローを画像として保存
- ComfyUIのキャンバスにグラフが表示された状態を作ります。ここでは標準のグラフを表示しています。

- キャンバスのノードがない場所を右クリックし、コンテクストメニューを表示させます。表示されたメニューの「Workflow Image -> Export -> png」または「Workflow Image -> Export -> svg」を選択します。
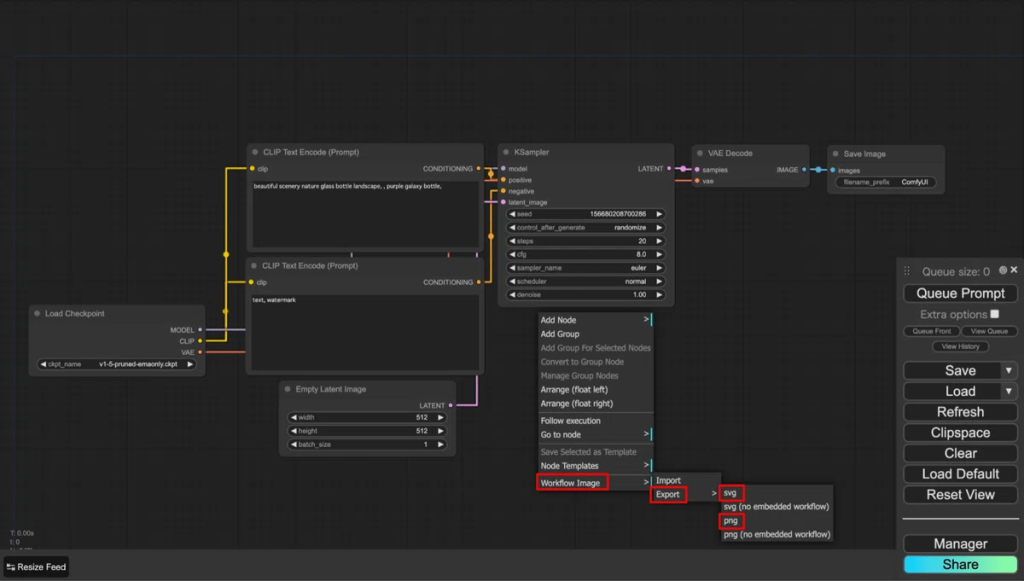
- それぞれ「workflow.png」「workflow.svg」という名前でダウンロードフォルダに保存されます。

2. ワークフローの呼び出し方法
保存したワークフローを再度呼び出す方法について説明します。ここでは、JSONファイルからの呼び出し方法と画像からの呼び出し方法について説明します。
2.1 JSONファイルからの呼び出し
保存したJSONファイルを使用してワークフローを呼び出す手順は以下の通りです。
- まずは、読み込まれたことが分かるように、グラフをクリアします。メニューの「Clear」をクリックし、表示されたダイアログで「OK」をクリックしてください。

- グラフがクリアされ、キャンバスには何も表示されていない状態になります。

- メニューの「Load」をクリックします。

- ファイル選択ダイアログが表示されるので、キャンバスに読み込むワークフローのJSONファイルを選択します。

- 選択したワークフローが読み込まれ、キャンバスにグラフが表示されます。

2.2 画像からの呼び出し
画像に埋め込まれたワークフロー情報を利用してワークフローを呼び出す手順は以下の通りです
- 先ほどと同様にグラフをクリアします。メニューの「Clear」をクリックし、表示されたダイアログで「OK」をクリックしてください。

- グラフがクリアされ、キャンバスには何も表示されていない状態になります。

- 保存した「workflow.svg」または「workflow.png」をキャンバスにドラッグ&ドロップします。

- ワークフローが読み込まれ、キャンバスにグラフが表示されます。

まとめ
ComfyUIでは、作成したワークフローを効率的に管理し再利用するために、いくつかの保存・呼び出し方法が用意されています。この記事では、主にJSONファイルによる保存と、ComfyUI-Custom-Scriptsを利用した画像による保存という2つの方法を解説しました。
JSONファイルによる保存は、ワークフロー全体をテキストデータとして保存する方法です。この方法は、ワークフローの詳細な設定を保持できるため、編集や再利用に最適です。一方、ComfyUI-Custom-Scriptsを利用した画像による保存は、ワークフローを視覚的に分かりやすい画像として保存する方法です。共有やプレゼンテーションに役立ちます。
本記事で紹介した方法を理解し、ワークフローを適切に保存・呼び出しすることで、作業効率の向上、共同作業の促進、そして創造的なワークフローの構築に繋がるでしょう。
次回はワークフローの公開・共有方法について解説します。乞うご期待!
AICU mediaのX(Twitter)@AICUai のフォローもお忘れなく!
画像生成AI「ComfyUI」マスターPlan
画像生成AI「Stable Diffusion」特に「ComfyUI」を中心としたプロ向け映像制作・次世代の画像生成を学びたい方に向けたプランです。最新・実用的な記事を優先して、ゼロから学ぶ「ComfyUI」マガジンからまとめて購読できます。 メンバーシップ掲示板を使った質問も歓迎です。
- メンバー限定の会員証が発行されます
- 活動期間に応じたバッジを表示
- メンバー限定掲示板を閲覧できます
- メンバー特典記事を閲覧できます
- メンバー特典マガジンを閲覧できます
- 動画資料やworkflowといった資料への優先アクセスも予定
ゼロから学ぶ「ComfyUI」マガジン
https://note.com/aicu/m/md2f2e57c0f3c
マガジン単体の販売は1件あたり500円を予定しております。
2件以上読むのであればメンバーシップ参加のほうがお得です!というのもメンバーシップ参加者にはもれなく「AICU Creator Union」へのDiscordリンクをお伝えし、メンバーオンリー掲示板の利用が可能になります。
https://note.com/aicu/membership/boards/61ab0aa9374e/posts/db2f06cd3487?from=self
もちろん、初月は無料でお試しいただけます!
毎日新鮮で確かな情報が配信されるAICUメンバーシップ。
退会率はとても低く、みなさまにご満足いただいております。
✨️オトクなメンバーシップについての詳細はこちら
この記事の続きはこちらから https://note.com/aicu/n/n41dcdc90dbe5
Originally published at https://note.com on Aug 25, 2024.