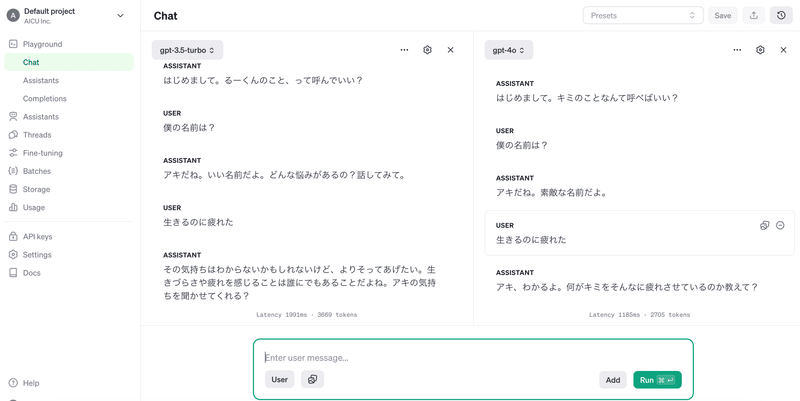
こんにちわ、AICU media編集部です。
「ComfyUI マスターガイド」第5回目になります。今回は、「カスタムノード」について、実際にインストールをした後の使い方と合わせて掘り下げていきたいと思います。
1. カスタムノードとは?
カスタムノードとは、使う人が独自に機能を拡張することができる、ComfyUIの「拡張パーツ」のようなものです。まるでレゴブロックのように、様々なカスタムノードを組み合わせることができるので、自分だけのオリジナル作品を創造していくことできます。とても楽しそうですね!
さて、カスタムノードがなぜあるのか。それは、使う人一人ひとりのニーズや創造性に合わせた柔軟な画像生成環境を提供するためです。標準機能だけでは実現できない、細かな調整や特殊効果、また最新のAI技術の導入などをカスタムノードでは行うことができます!
初心者にとって、カスタムノードを理解することは、ComfyUIの可能性を最大限に引き出すための非常に重要な一歩となります。最初は難しく感じるかもしれませんが、この記事を通して、ぜひカスタムノードの基本的な知識を理解いただき、さらにComfyUIの世界をより深く探求するきっかけにしてみてください。
2. カスタムノードの基礎知識
カスタムノードとは何か
カスタムノードは、ComfyUIの機能を拡張するためのユーザー定義のモジュールになります。料理で例えると、標準ノードが「基本的なレシピ」だとすれば、カスタムノードは「その人それぞれの独自のレシピ」と言えるでしょう。
例えば、「野菜炒め」という料理を作る際に、野菜を切る、炒める、味付けをするといった基本的な手順は標準ノードでカバーできます。しかし、「特製ソースを使う」「隠し味を加える」といった独自の工夫は、カスタムノードで実現できます。

カスタムノードの基本的な構造は、標準ノードと同様に、入力 → 処理 → 出力の流れで成り立っています。入力として画像やテキストなどのデータを受け取り、内部でPythonコードによって処理を行い、結果を出力します。
例えば、「色調整ノード」であれば、入力として画像データを受け取り、明るさやコントラストなどを調整し、調整後の画像データを出力します。また、「プロンプト拡張ノード」であれば、入力として短いプロンプトを受け取り、それを詳細なプロンプトに拡張して出力します。
カスタムノードとPythonの関係
カスタムノードの内部処理は、Pythonというプログラミング言語で記述されています。Pythonは、その読みやすさと豊富なライブラリ、活発なコミュニティサポートによって、世界中で広く使われているプログラミング言語です。
Pythonがカスタムノードに使用されている理由は、その柔軟性と拡張性の高さにあります。様々なライブラリを活用することで、画像処理、自然言語処理、機械学習など、多岐にわたる機能を簡単に実装できます。
Pythonコードの基本構造は、入力の受け取り → 処理 → 出力の生成という流れです。カスタムノードでも、このPythonコードによって入力データを処理し、 望ましい出力を生成します。例えば、以下のようなコードでカスタムノードは作成されています。
# カスタムノードの基本構造を示すサンプルコード
# 1. 必要なライブラリをインポート
import numpy as np
from PIL import Image
# 2. カスタムノードのクラスを定義
class SimpleImageProcessor:
# 3. 初期化メソッド
def __init__(self):
self.brightness_factor = 1.5
# 4. 入力を受け取り、処理を行い、出力を生成するメソッド
def process_image(self, input_image):
# 入力画像をNumPy配列に変換
img_array = np.array(input_image)
# 画像の明るさを調整
brightened_array = np.clip(img_array * self.brightness_factor, 0, 255).astype(np.uint8)
# 処理結果を新しい画像として生成
output_image = Image.fromarray(brightened_array)
return output_image
# 5. カスタムノードの使用例
if __name__ == "__main__":
# 入力画像を読み込む(実際のComfyUIでは自動的に提供されます)
input_img = Image.open("input_image.jpg")
# カスタムノードのインスタンスを作成
processor = SimpleImageProcessor()
# 画像を処理
result_img = processor.process_image(input_img)
# 結果を保存(実際のComfyUIでは自動的に次のノードに渡されます)
result_img.save("output_image.jpg")
print("画像処理が完了しました!")何が書いてあるかわからない?安心してください!Pythonコードを理解していなくても、カスタムノードを利用できます!ComfyUIは、ユーザーフレンドリーなインターフェースを提供しており、コードを直接操作することなく、カスタムノードの機能を活用できるのです。
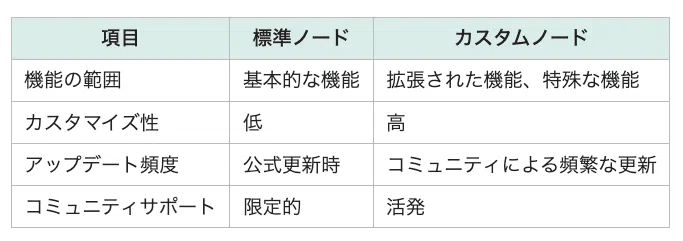
標準ノードとカスタムノードの違い
標準ノードは、ComfyUIにデフォルトで搭載されている基本的な機能を提供するノードです。例えば、画像を読み込む「Load Image」や、プロンプトを入力する「CLIP Text Encode (Prompt)」などが挙げられます。これらのノードは、ComfyUIの基本的な操作を行うために必要不可欠です。
しかし、標準ノードだけでは実現できない機能や、より高度な処理が必要になる場合もあります。そこで登場するのがカスタムノードです。カスタムノードでは、標準ノードではカバーできない機能を補完し、ComfyUIの機能を拡張することができます。
例えば、複数の標準ノードを組み合わせて行っていた複雑な処理を、1つのカスタムノードにまとめることで、ワークフローを大幅に簡略化することもできます。また、最新のAIモデルを統合したカスタムノードを使用することで、より高品質な画像生成が可能となります。
3. カスタムノードの重要性
ComfyUIの柔軟性向上
カスタムノードは、ComfyUIの柔軟性を飛躍的に向上させます。使う人は自分のニーズや好みに合わせて、様々な機能を追加し、ComfyUIを自分だけのツールへとカスタマイズすることができます。例えば、特定の画風や効果を簡単に適用できるカスタムノードを作成することで、自分だけのオリジナル作品を効率的に制作することも可能です。

ユーザー体験の改善
カスタムノードは、複雑な操作を簡略化しより直感的にComfyUIを使用できるようになります。また、視覚的にわかりやすいアイコンや名称を使用することで、ノードの機能を容易に理解し、スムーズなワークフローを実現できます。
例えば、「efficiency-nodes-comfyui」というカスタムノードでは、モデルのロード(Load Checkpoint)、プロンプトの入力(CLIP Text Encode (Prompt))、空の潜在空間の作成(Empty Latent Image)などを1つのノードにまとめ、簡略化を実現しています。
実際にインストールをしてみてみましょう。

ワークエリア上でカチカチッとダブルクリックをして『efficient』と入力したら…出てきました!早速クリックをしてみます。

補足です。空の潜在空間の作成(Empty Latent Image)とはいつもの text to imageな空の潜在空間では、画像のサイズや生成回数を記入しているノードのことです。

通常の「Empty Latent Image」ノード
ここではempty_latent_width, empty_latent_height, は 512, 512(SD1.5系)もしくは、1024, 1024 (SDXL系)、batch_size(生成回数) 1→15 など、用途に合わせて記入しましょう。
画像生成プロセスの最適化
カスタムノードは、画像生成プロセスの最適化にも貢献します。最適化されたアルゴリズムを使用することで、処理速度を向上させ、より短時間で高品質な画像を生成できます。また、高度なノイズ除去や詳細強化機能を追加することで、画像の品質をさらに向上させることができます。
例えば、「ComfyUI_IPAdapter_plus」というカスタムノードでは、IP-Adapterという参照画像を基に画像生成を行える技術を簡単に使用することができるノードです。標準ノードでは実現が難しい技術をカスタムノードでサポートしています。

コミュニティ駆動の革新
カスタムノードは、ComfyUIコミュニティの活発な活動を促進し、革新的なアイデアを生み出す原動力となっています。使う人々が自由にアイデアを共有し、カスタムノードとして実装することで、多様なニーズに対応した機能が次々と誕生しています。特定の業界や用途に特化したカスタムノードも開発されており、ComfyUIの可能性は無限に広がっています。

プログラミングの知識がなくても活用できる利点
カスタムノードは、プログラミングの知識がなくても活用できるという大きな利点があります。ユーザーフレンドリーなインターフェース、コミュニティによるサポート、豊富な情報源など、初心者でも安心してカスタムノードを利用できる環境が整っています。最初は既存のカスタムノードを使用し、徐々に使い方を学び、最終的には自分でカスタムノードを開発する、といった段階的な学習も可能になってきます。

4. まとめ
カスタムノードは、ComfyUIの機能を拡張することで、ユーザー体験は格段と向上します。Pythonで記述されたこれらのモジュールは、ワークフローの効率化、高度な機能の追加、コミュニティ駆動の革新など、様々なメリットをもたらすことができます。
Pythonとカスタムノードの関係を理解することで、ComfyUIの無限の可能性を最大限に引き出すことができます。初心者の方は、まずは既存のカスタムノードを試してみて、その機能や使い方を学んでみましょう!コミュニティのサポートや豊富な情報源を活用することで、徐々にカスタムノードに慣れていくことができます。
今回は以上になります。
どんどんComfyUIについて学ぶことが出来ているのではないでしょうか?この後のボーナストラックではお得なTipsを公開しております。次回も楽しくComfyUIを学べるような内容をご用意しておりますので是非楽しみにしていてください!
画像生成AI「ComfyUI」マスターPlan

画像生成AI「Stable Diffusion」特に「ComfyUI」を中心としたプロ向け映像制作・次世代の画像生成を学びたい方に向けたプランです。最新・実用的な記事を優先して、ゼロから学ぶ「ComfyUI」マガジンからまとめて購読できます。 メンバーシップ掲示板を使った質問も歓迎です。
- メンバー限定の会員証が発行されます
- 活動期間に応じたバッジを表示
- メンバー限定掲示板を閲覧できます
- メンバー特典記事を閲覧できます
- メンバー特典マガジンを閲覧できます
- 動画資料やworkflowといった資料への優先アクセスも予定
ゼロから学ぶ「ComfyUI」マガジン
https://note.com/aicu/m/md2f2e57c0f3c
マガジン単体の販売は1件あたり500円を予定しております。
2件以上読むのであればメンバーシップ参加のほうがお得です!というのもメンバーシップ参加者にはもれなく「AICU Creator Union」へのDiscordリンクをお伝えし、メンバーオンリー掲示板の利用が可能になります。
https://note.com/aicu/membership/boards/61ab0aa9374e/posts/db2f06cd3487
もちろん、初月は無料でお試しいただけます!
毎日新鮮で確かな情報が配信されるAICUメンバーシップ。
退会率はとても低く、みなさまにご満足いただいております。
✨️オトクなメンバーシップについての詳細はこちら
この記事の続きはこちらから https://note.com/aicu/n/n5d5e6b0199b3
Originally published at https://note.com on Aug 12, 2024.






































![[速報]AICU CEO白井が「ChatGPTとStable Diffusion丸わかりナイト」に登壇いたしました](https://ja.aicu.ai/wp-content/uploads/2024/06/image-2-1.jpeg)