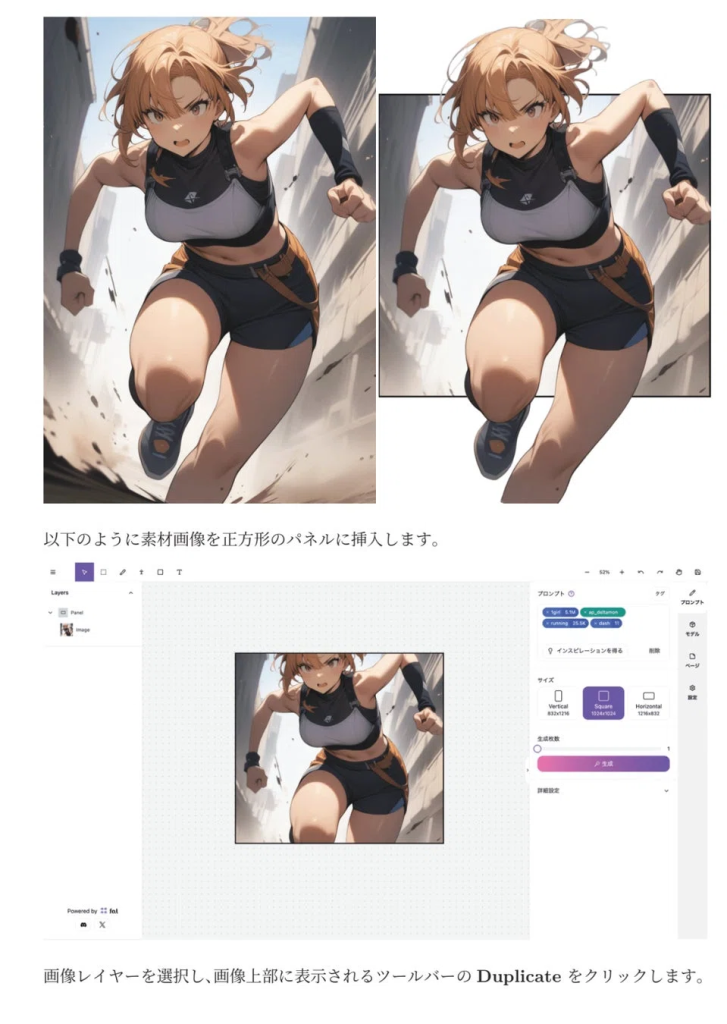
ComfyUIで「思い通りの画像を生成したい!けど思うようにいかない…」という方、TextToImage(t2i)を使いこなせていますか? Stable Diffusionの内部の仕組みを理解し、ComfyUIでのText to Imageテクニックを身につけて、思い通りの画像を生成できるようになりましょう!
face focus, dog ears, 1boy, best quality, 16K, eating hair, dog nose, looking at looking at viewer, short hair, skinny, big eyes, dark skin, tall, naked overalls, 20-year-old,
beautiful, bold black outline, pink, pastel colors, Light Pink, scowl, brown hair, golden eyes, simple line drawing, animal ears, solo, brown hair, overalls, cat ears, dark skin, short hair, dark-skinned female, simple background, choker, sweater, yellow shirt, long sleeves, pink choker, white background, closed mouth, extra ears, animal ear fluff
「face focus, dog ears, 1boy, best quality, 16K, eating hair, dog nose, looking at looking at viewer, short hair, skinny, big eyes, dark skin, tall, naked overalls, 20-year-old, beautiful, bold black outline, pink, pastel colors, Light Pink, scowl, brown hair, golden eyes, simple line drawing, animal ears, solo, brown hair, overalls, cat ears, dark skin, short hair, dark-skinned female, simple background, choker, sweater, yellow shirt, long sleeves, pink choker, white background, closed mouth, extra ears, animal ear fluff」、ネガティブプロンプトは「text, watermark」(2トークン消費)で生成してみます。
前半「face focus, dog ears, 1boy, best quality, 16K, eating hair, dog nose, looking at looking at viewer, short hair, skinny, big eyes, dark skin, tall, naked overalls, 20-year-old」 Negative 「text, watermark」, SDXL, 1344×768, seed=13
CLIP1-Conditioning_to「face focus, dog ears, 1boy, best quality, 16K, eating hair, dog nose, looking at looking at viewer, short hair, skinny, big eyes, dark skin, tall, naked overalls, 20-year-old」 CLIP2-Conditiong_from「beautiful, bold black outline, pink, pastel colors, Light Pink, scowl, brown hair, golden eyes, simple line drawing, animal ears, solo, brown hair, overalls, cat ears, dark skin, short hair, dark-skinned female, simple background, choker, sweater, yellow shirt, long sleeves, pink choker, white background, closed mouth, extra ears, animal ear fluff」 Negative 「text, watermark」, SDXL, 1344×768, seed=13
CLIP1-Conditioning_to「beautiful, bold black outline, pink, pastel colors, Light Pink, scowl, brown hair, golden eyes, simple line drawing, animal ears, solo, brown hair, overalls, cat ears, dark skin, short hair, dark-skinned female, simple background, choker, sweater, yellow shirt, long sleeves, pink choker, white background, closed mouth, extra ears, animal ear fluff」 CLIP2-Conditiong_from「face focus, dog ears, 1boy, best quality, 16K, eating hair, dog nose, looking at looking at viewer, short hair, skinny, big eyes, dark skin, tall, naked overalls, 20-year-old」 Negative 「text, watermark」, SDXL, 1344×768, seed=13
続いてキャラクター2のプロンプトを設定します。もともと頂いたプロンプトからキャラクターとして一貫性がありそうな「1boy, dog ears, dog nose, short hair, skinny, big eyes, looking at viewer, dark skin, tall, naked overalls, 20-year-old, brown hair」(1boy、犬耳、犬鼻、短髪、痩せ型、大きな目、視聴者を見ている、黒い肌、背が高い、裸のオーバーオール、20歳、茶髪)として、先程のキャラクター1の代わりに入れてみます。
Conditioning_to「1boy, dog ears, dog nose, short hair, skinny, big eyes, looking at viewer, dark skin, tall, naked overalls, 20-year-old, brown hair」 Conditioning_from「beautiful, bold black outline, simple line drawing, simple background, white background, best quality, 16K」
入れ替えてみます。
Conditioning_to「beautiful, bold black outline, simple line drawing, simple background, white background, best quality, 16K」 Conditioning_from「1boy, dog ears, dog nose, short hair, skinny, big eyes, looking at viewer, dark skin, tall, naked overalls, 20-year-old, brown hair」
CLIPを2つでConcatだけで構成する場合にはこんな感じです。 [CLIP1] best quality, beautiful, 1girl and 1boy, [CLIP2] best quality, beautiful, 1girl and 1boy, ここまでいれる、というテクニックが非常に重要です。 こんな絵も作れるようになります。
[CLIP1] best quality, beautiful, 1girl and 1boy, 1girl, female, 20-year-old, cat ears, pink choker, sweater, yellow shirt, long sleeves, white background, closed mouth, extra ears, animal ear fluff, solo, brown hair, overalls, pink, pastel colors, Light Pink, face focus,
[CLIP2] best quality, beautiful, 1girl and 1boy, blue choker, eating hair, dog ears,16K, dog nose, looking at looking at viewer, short hair, skinny, big eyes, dark skin, tall, naked overalls, bold black outline, scowl, brown hair, golden eyes, simple line drawing, animal ears, simple background, dark skin, short hair, dark-skinned
CLIP0(conditioning_to) : 1boy and 1girl looking each other, beautiful, bold black outline, simple line drawing, simple background, white background, best quality, 16K
CLIP1(Conditiong_from) : 1boy and 1girl looking each other,1boy face focus, dog ears, 1boy, best quality, 16K,, dog nose, looking at looking at viewer, short hair, skinny, big eyes, dark skin, tall, naked overalls, 20-year-old
CLIP2(Conditioning_from) : 1boy and 1girl looking each other, 1girl , pink, pastel colors, Light Pink, scowl, golden eyes, animal ears, solo, overalls, cat ears, dark skin, short hair, dark-skinned female, choker, sweater, yellow shirt, long sleeves, pink choker, closed mouth, extra ears, animal ear fluff
これまで4回にわたってComfyUIでSD1.5およびSDXLを使ってプロンプトの基本的な方法から、応用的なテクニックまでを紹介してきました。今回はイラストレーションで「複数のキャラクターを同時制御する」という実験を行いましたが、プロンプトだけでなく、CLIPの内部やConditioningを使ってComfyUIならではの絵作りを探求していくベースになったようであれば幸いです。実はconditioningにはたくさんあり、今回紹介したCombine、Concatの他にはAverage、 Set Areaなど複数存在します。例えばAverageは結合ではなく線形補間します。
使用プログラム [メインツール] – Stability AI API – Google Colab – Google Workspace
【こんな方におすすめ】
画像生成AIに興味があるけど、何から始めればいいか分からない方
Stable Diffusionをもっと使いこなしたい方
これからの時代を見据え、AIスキルを身につけておきたい方
デザイン、アート、広告など、クリエイティブな仕事に携わっている方
業務的な画像生成AIを体系的に学ぶ必要が出てきた企業クリエイター
新しい技術を学び、自分の可能性を広げたい方
【AICU開発! 本講座だけの特典】
AICUによる画像生成AIに必要な知識が詰まった講座動画25講を期間制限なしで受講可能
講座を通してセミリアルや実写など12点の例題を完成
講座内容に関するPDFデータや資料、Google Slidesで使えるツールを提供
画像生成プロンプト集を提供
AICUのノウハウが詰まった講座PDF使用を提供
AICU Inc. は Stability AIと戦略提携を
AICU Inc.(本社Delaware州Dover City, カリフォルニア州サニーベール)は、Stability AI Ltd.(本社London、United Kingdom)とのパートナーシップを発表しました。このパートナーシップは、エンゲージメント・レターを通じて正式に締結されており、持続革新的でオープンなAIDX(AI Driven user eXperience)開発、技術広報を提供するもので、生成AI技術の社会的認知と価値向上と市場開拓を推進するコミュニケーションに重点を置いています。 AICU Inc.は、この提携により、Stability AI Ltd. の生成AI技術の社会的認知と円滑なコミュニケーションのために、advocacy communication service としてコンサルティングサービスと開発者・クリエイター支援・技術広報・PoC開発・クリエイターユニオン構築に協力します。