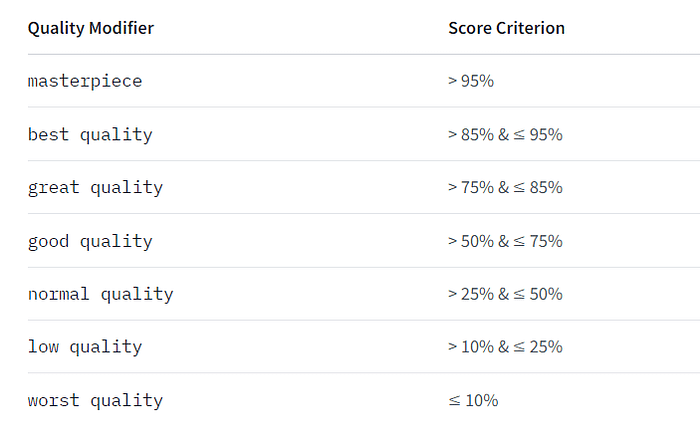
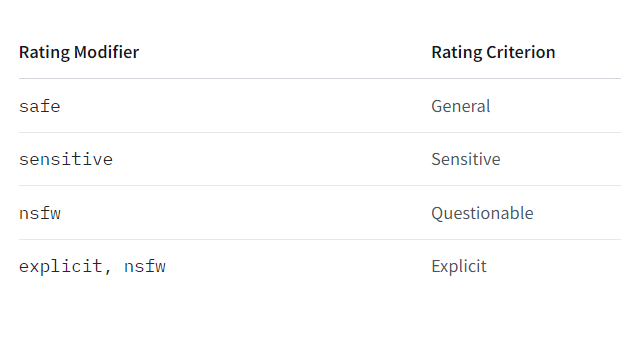
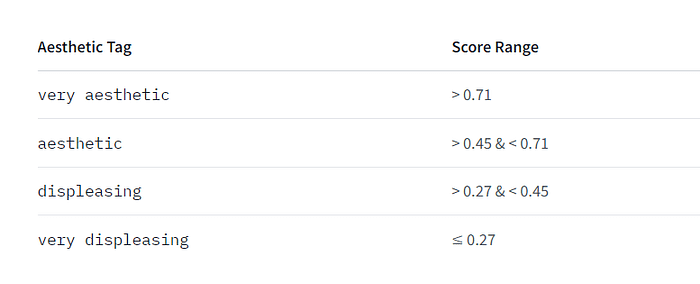
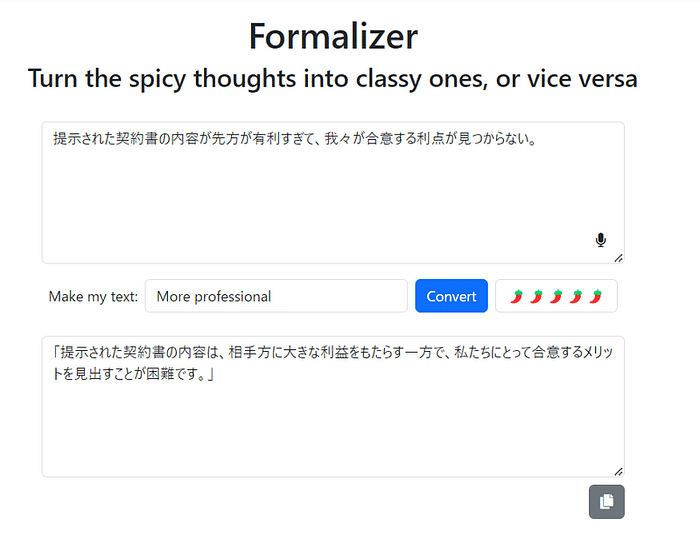
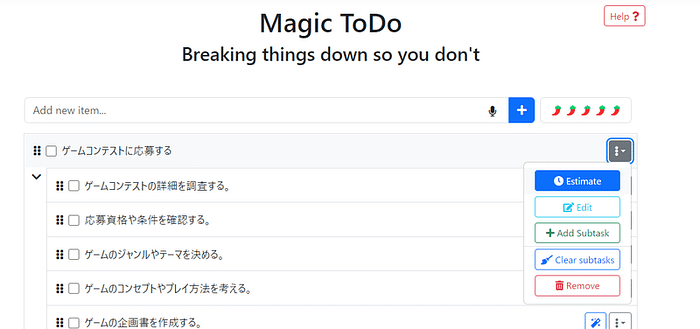
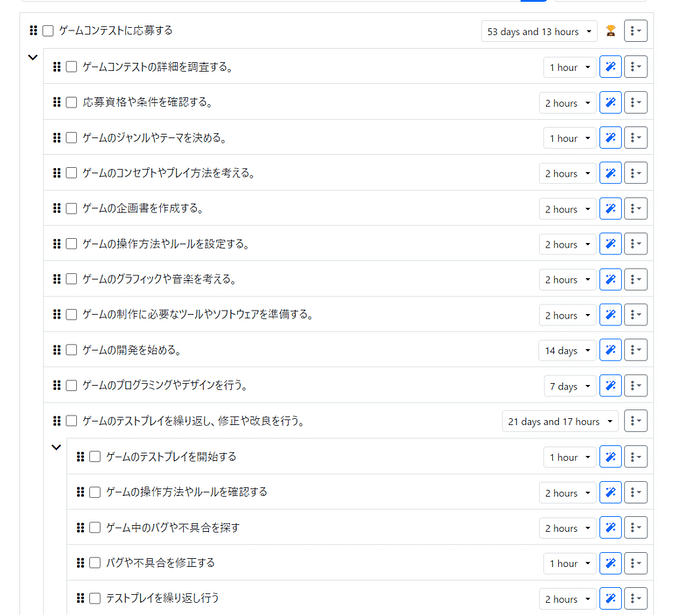
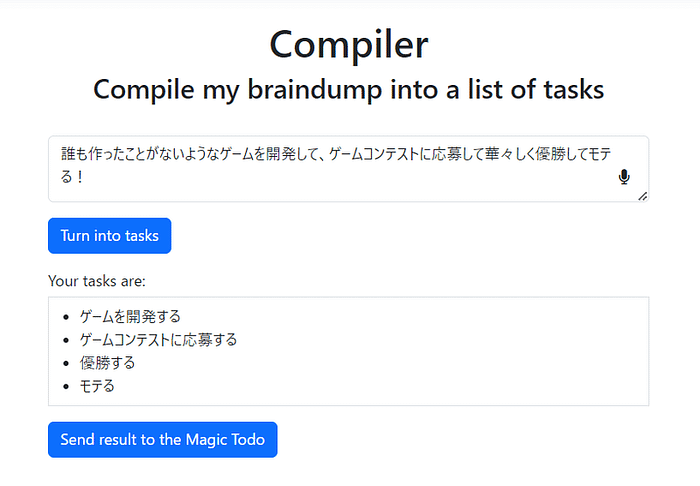
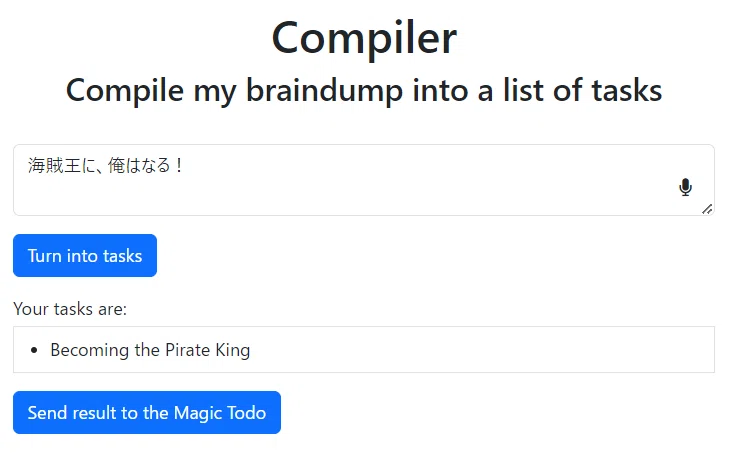
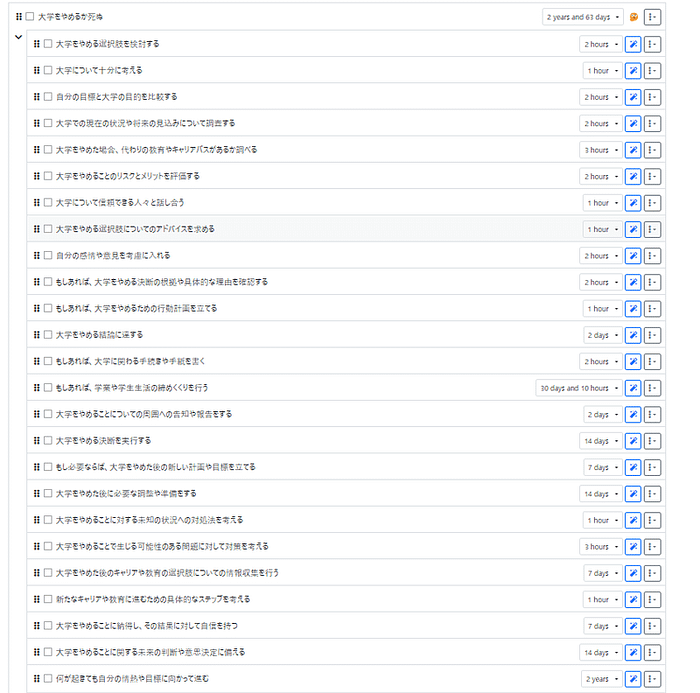
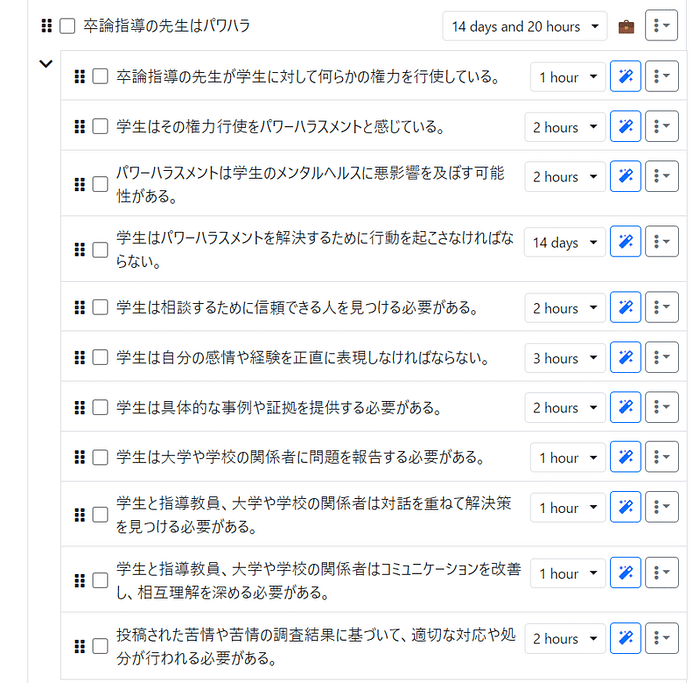
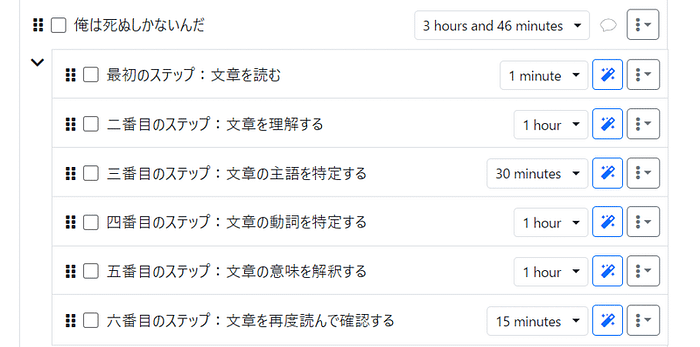
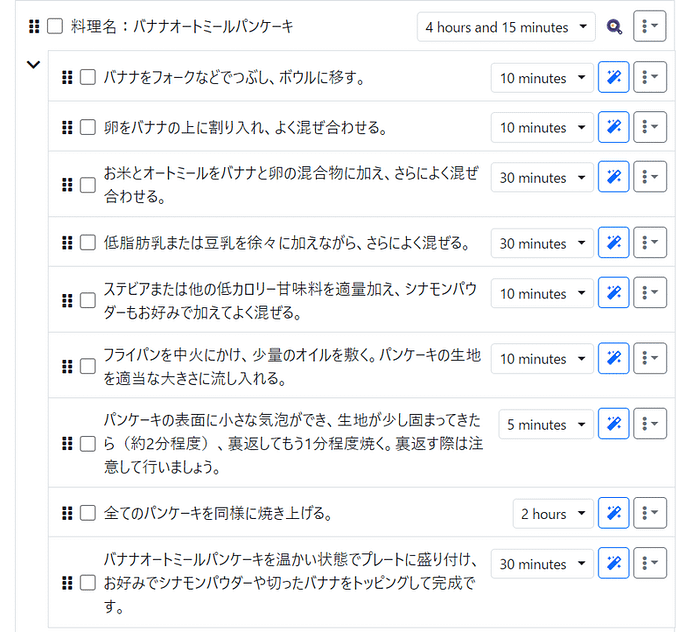
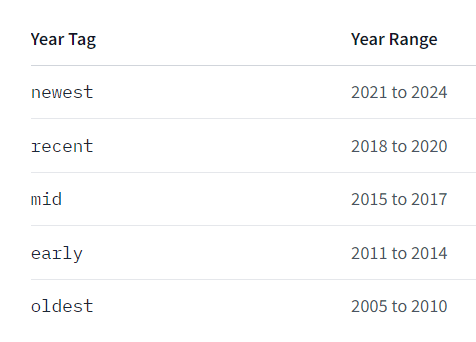We're excited to announce that Animagine-XL v3.1 is now live! This iteration is fine-tuned on top of v3.0 to improve its capabilities. In addition to gacha games charas, we also added popular anime and premium games charas to the dataset.
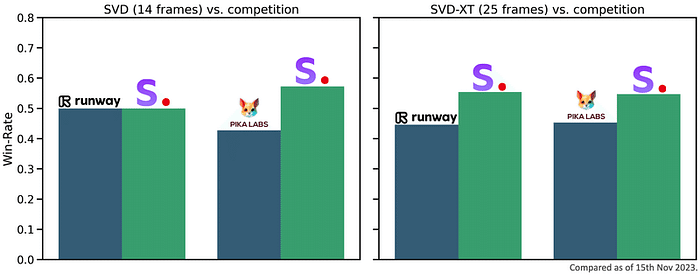
2023年11月21日、StabilityAI社は画像から動画を生成する技術「Stable Video Diffusion」(SVD)を公開しました。 研究者の方はGitHubリポジトリで公開されたコードを試すことができます。ローカルでモデルを実行するために必要なウェイトは、HuggingFaceで公開されています(注意:40GBのVRAMが必要です)。 さらにStable Video Diffusion (SVD) を使って画像から動画へウェブインタフェースも近日公開予定とのこと。キャンセル待ちリストが公開されています。
「Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets」(21 Nov ,2023) 安定した映像拡散: 潜在的映像拡散モデルの大規模データセットへの拡張
高解像度で最先端のテキストから動画、画像から動画生成のための潜在動画拡散モデル、Stable Video Diffusionを紹介する。近年、2次元画像合成のために学習された潜在拡散モデルは、時間レイヤーを挿入し、小規模で高品質なビデオデータセット上で微調整することで、生成的なビデオモデルへと変化している。しかし、文献に記載されている学習方法は様々であり、ビデオデータをキュレーションするための統一的な戦略について、この分野はまだ合意されていない。本論文では、動画LDMの学習を成功させるための3つの異なる段階を特定し、テキストから画像への事前学習、動画の事前学習、高品質動画の微調整の評価を行った。
使用される AI モデルは汎用モデルであるため、出力の精度は異なる場合があります。どのツールからも返されるものは何も真実の記述として解釈されるべきではなく、推測にすぎません。得られた結果が妥当であるかどうかは、ご自身の知識と経験に基づいて判断してください。 免責事項: goblin.tools、Skyhook、および Bram De Buyser は、結果やその使用方法について責任を負いません。 goblin.tools は、このページで言及されているもの以外の Web サイトやアプリと提携したり、推奨したりするものではありません。
しらいはかせの一言解説:ニューロダイバージェントとは?
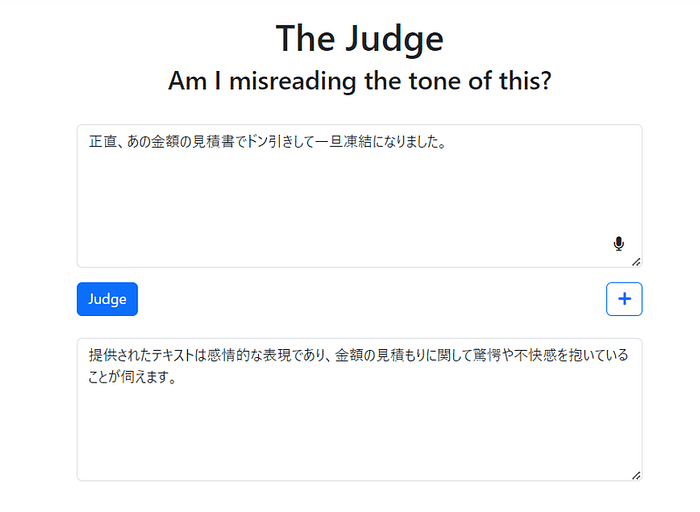
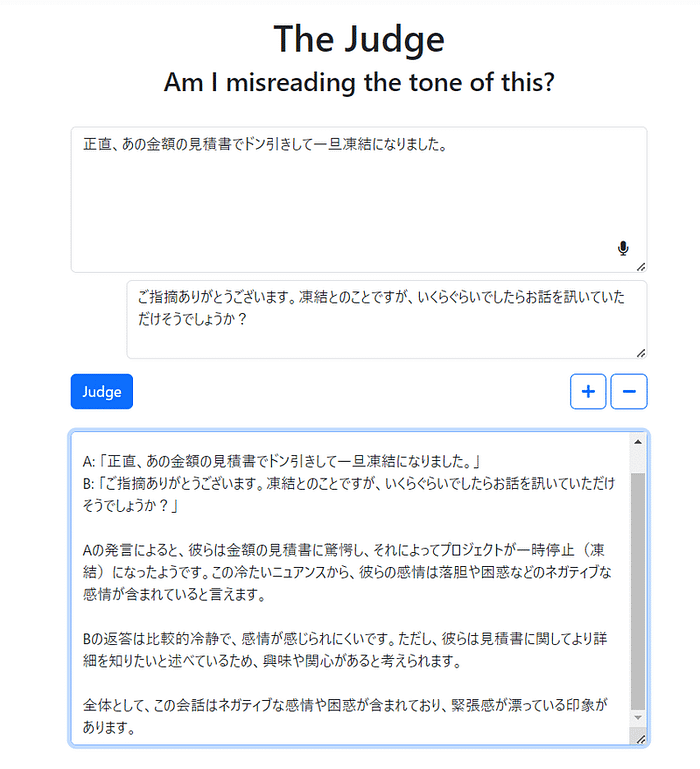
しらいはかせに紹介されたこのツールですが、大好評ですね。 でもアプリのタグライン(1行解説)には「Smart tools for the neurospicy」と書かれています。nuerospicyとはどんな意味なんでしょうか。
クリエイティブなAIDX (AI Driven user eXperience)とコミュニケーションAIによって、人間の可能性を広げる「創造する人」を生み出す活動として、放送、アニメ、メディア、Webなどのプロフェッショナルに向けてAIDXを実施し、生成AIを活用した新しいコミュニケーション技術を開発したり、AIクリエイティブワークショップを提供しています。
これらをAICUでは AIDX = AI Driven user eXperience と呼んでいます(実際には「話を聞いてみると結局は”AIによるDX案件”が多いから…」ってCEOは言ってました)。 AIDX Labは主にメタバースオフィスでインターンやオンライン上の実力あるクリエイターが集まって、わいわい開発しています。
3つ目が、 Media Communication Business Unit [ メディアコミュニケーション事業部] です。ブログメディア、書籍や映像メディア、クリエイティブワークショップやハッカソンの開発、AI関連企業のAdvocate事業、デベロッパーリレーション、テクニカルライティングやリサーチも担当しています。





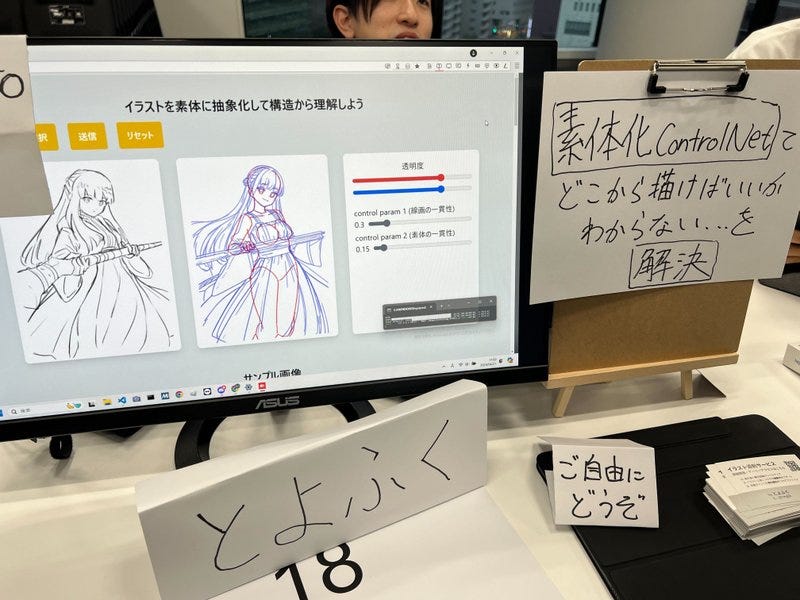


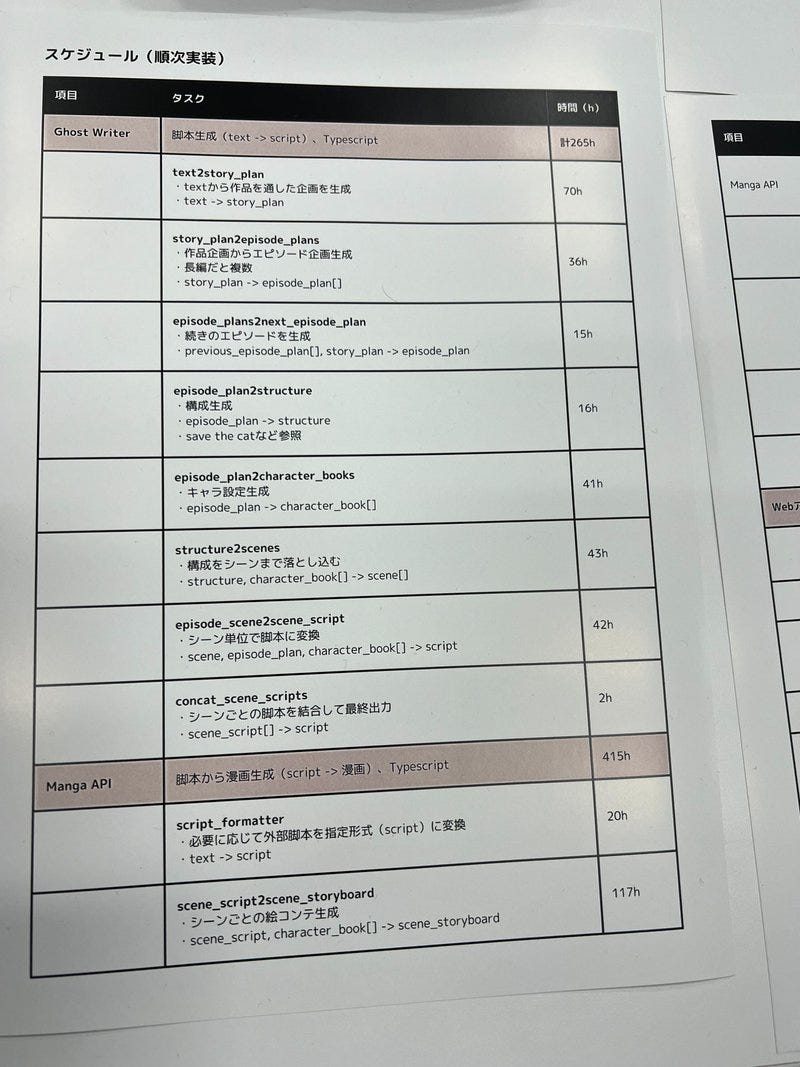
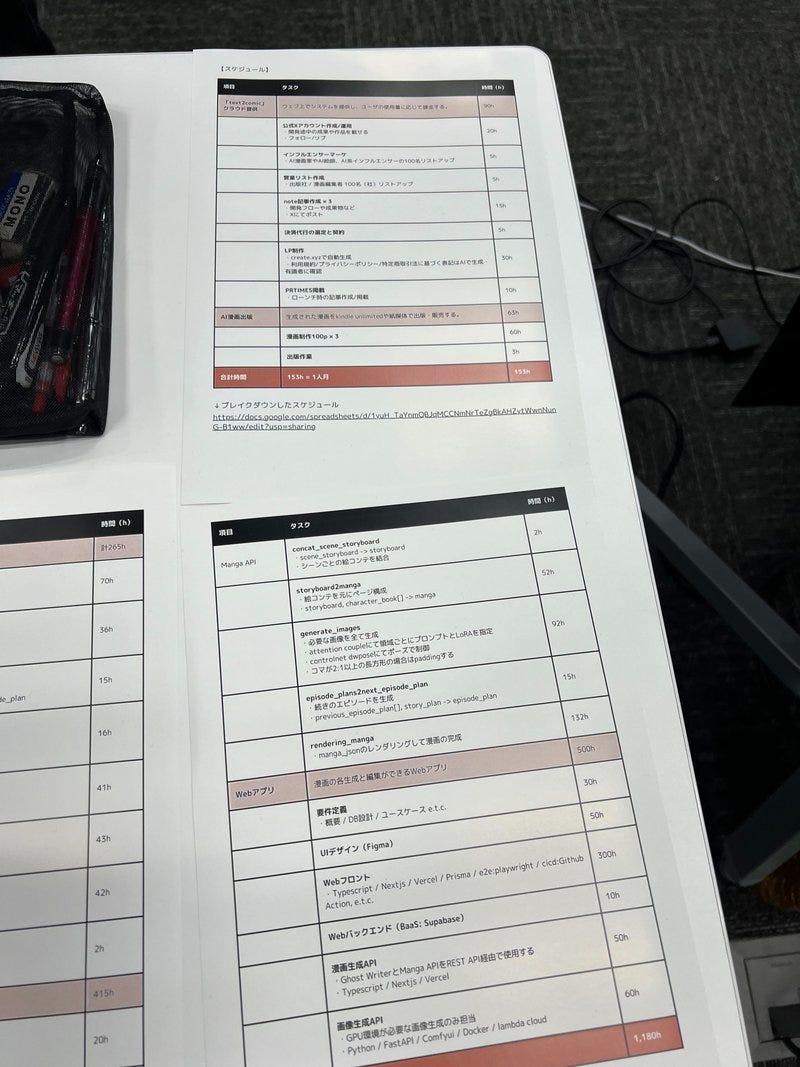




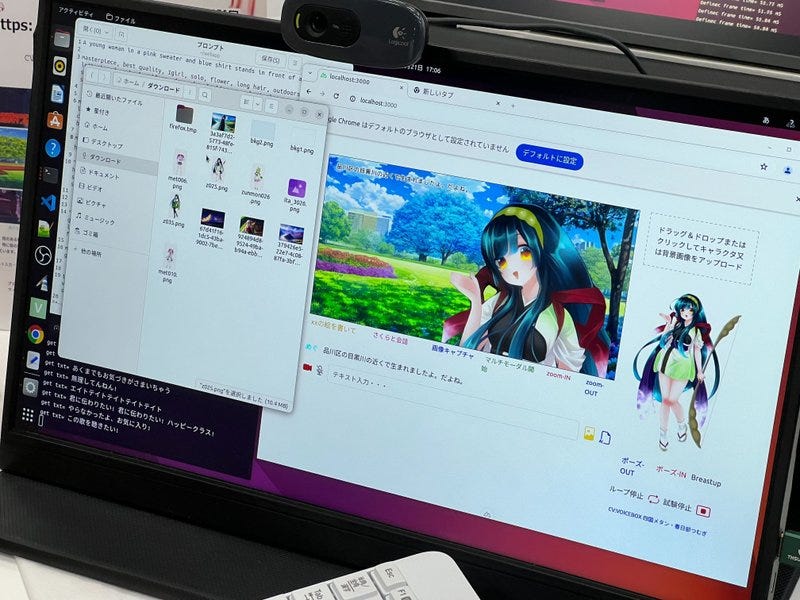


















![[保存版] Animagine XL 3.1 生成比較レポート](https://ja.aicu.ai/wp-content/uploads/2024/07/image-29.png)