日本時間で2024年7月10日、スタンフォード大学の博士課程の学生である「Fooocus」や「Omost」「Style2Paint」の開発者Lvmin Zhang さん(GitHubアカウント: lllyasviel)らの研究グループが、興味深い研究成果を発表しました。Google Colabで試せる実験コードも紹介します。
https://note.com/aicu/n/n8990c841e373
圧巻のデモ
ぜひこちらのデモサイトで結果を観てください
https://lllyasviel.github.io/pages/paints_undo
この Web ページのすべての入力画像は AI によって生成されたものであることに注意してください。それらの「グラウンド・トゥルース」つまり「正解の描画プロセス」は存在しません。画像生成によって生成された1枚の画像をベースに「それが描かれたであろう工程」を、まるでイラストレーターの作業配信動画(タイムラプス)のように生成しています。

美少女イラスト以外の分野での実験。


ラフスケッチの生成

異なる描画工程の再現



失敗例

以下、公式READMEの翻訳を中心に、解説を補完しながらお送りします。
https://github.com/lllyasviel/Paints-UNDO
実際に動作させた例は最後に紹介します。

Paints-Undo:デジタルペイントにおける描画動作のベースモデル
Paints-Undoは、将来のAIモデルが人間のアーティストの真のニーズに沿うことができるように、人間の描画動作のベースモデルを提供することを目的としたプロジェクトです。
「Paints-Undo」という名前は、モデルの出力がデジタルペイントソフトで「元に戻す」ボタン(通常はCtrl+Z)を何度も押したときのように見えることに由来しています。
Paints-Undoは、画像を入力として受け取り、その画像の描画シーケンスを出力するモデル群です。このモデルは、スケッチ、インク入れ、着色、シェーディング、変形、左右反転、カラーカーブ調整、レイヤーの表示・非表示の変更、さらには描画プロセス中の全体的なアイデアの変更など、人間のあらゆる行動を表現します。
利用方法
PaintsUndoは、以下の方法でローカルにデプロイできます。
condaのインストールと10GB以上のVRAMが必要です。
git clone https://github.com/lllyasviel/Paints-UNDO.git
cd Paints-UNDO
conda create -n paints_undo python=3.10
conda activate paints_undo
pip install xformers
pip install -r requirements.txt
python gradio_app.py 推論は、Nvidia 4090および3090TIの24GB VRAMでテストされています。16GB VRAMでも動作する可能性がありますが、8GBでは動作しません。私の推定では、極度の最適化(重みのオフロードやスライスアテンションを含む)を行った場合、理論上の最小VRAM要件は約10〜12.5GBです。
設定にもよりますが、1つの画像を処理するのに約5〜10分かかります。一般的な結果として、解像度320×512、512×320、384×448、または448×384で、FPS 4、25秒のビデオが得られます。
処理時間は、ほとんどの場合、HuggingFace Spaceのほとんどのタスク/クォータよりも大幅に長いため、HuggingFaceサーバーに不要な負担をかけないように、HuggingFace Spaceにデプロイすることはお勧めしません。
必要な計算デバイスがなく、それでもオンラインソリューションが必要な場合は、Colabノートブックがリリースされるのを待つという選択肢があります(ただし、Colabの無料枠で動作するかどうかはわかりません)。
モデルに関する注意事項
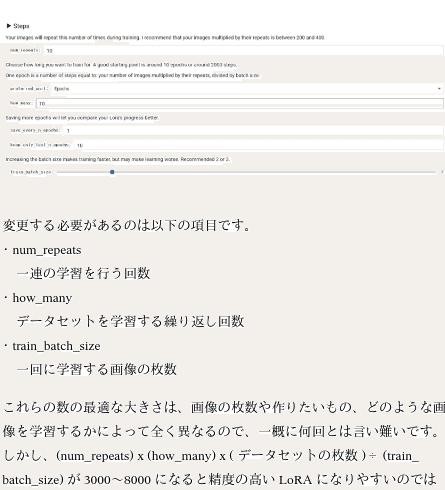
現在、 paints_undo_single_frame と paints_undo_multi_frame の2つのモデルをリリースしています。それぞれをシングルフレームモデル、マルチフレームモデルと呼ぶことにします。
シングルフレームモデルは、1つの画像と操作ステップを入力として受け取り、1つの画像を出力します。1つのアートワークは常に1000の人間の操作で作成できると仮定し(たとえば、1つのブラシストロークが1つの操作、操作ステップは0から999までの整数)。第0番は完成した最終アートワーク、第999番は真っ白なキャンバスに最初に描かれたブラシストロークとします。このモデルは、「元に戻す(Undo/Ctrl+Z)」モデルと理解することができます。最終的な画像を入力し、「Ctrl+Z」を何回押したいかを示すと、モデルはそれらの「Ctrl+Z」が押された後の「シミュレートされた」スクリーンショットを表示します。操作ステップが100の場合、この画像に対して100回「Ctrl+Z」をシミュレートして、100回目の「Ctrl+Z」後の外観を取得することを意味します。
マルチフレームモデルは、2つの画像を入力として受け取り、2つの入力画像間の16の中間フレームを出力します。結果はシングルフレームモデルよりもはるかに一貫性がありますが、はるかに遅く、「創造性」が低く、16フレームに制限されています。
このリポジトリでは、デフォルトの方法ではこれらを一緒に使用します。最初にシングルフレームモデルを5〜7回推論して5〜7つの「キーフレーム」を取得し、次にマルチフレームモデルを使用してそれらのキーフレームを「補間」して、実際に比較的長いビデオを生成します。
理論的には、このシステムはさまざまな方法で使用でき、無限に長いビデオを作成することもできますが、実際には最終フレーム数が約100〜500の場合に良好な結果が得られます。
モデルアーキテクチャ (paints_undo_single_frame)
このモデルは、異なるベータスケジューラ、クリップスキップ、および前述の操作ステップ条件でトレーニングされたSD1.5の変更されたアーキテクチャです。具体的には、このモデルは、次のベータを使用してトレーニングされています。
betas = torch.linspace(0.00085, 0.020, 1000, dtype=torch.float64)
比較のために、元のSD1.5は、次のベータを使用してトレーニングされています。
betas = torch.linspace(0.00085 ** 0.5, 0.012 ** 0.5, 1000, dtype=torch.float64) ** 2
終わりのベータと削除された正方形の違いに気付くでしょう。このスケジューラの選択は、内部ユーザー調査に基づいています。
テキストエンコーダCLIP ViT-L / 14の最後のレイヤーは完全に削除されます。 操作ステップ条件は、SDXLの追加の埋め込みと同様の方法でレイヤーの埋め込みに追加されます。
また、このモデルの唯一の目的は既存の画像を処理することであるため、このモデルは、他の拡張なしでWD14 Taggerと厳密に整合性が取れています。入力画像を処理してプロンプトを取得するには、常にWD14 Tagger(このリポジトリにあるもの)を使用する必要があります。そうしないと、結果に欠陥が生じる可能性があります。人間が書いたプロンプトはテストされていません。

モデルアーキテクチャ (paints_undo_multi_frame)
このモデルは、VideoCrafterファミリーから再開することでトレーニングされますが、元のCrafterのlvdmは使用されず、すべてのトレーニング/推論コードは完全にゼロから実装されています。(ちなみに、コードは最新のDiffusersに基づいています。)初期の重みはVideoCrafterから再開されますが、ニューラルネットワークのトポロジーは大幅に変更されており、ネットワークの動作は広範なトレーニングの後、元のCrafterとは大きく異なります。
全体的なアーキテクチャは、3D-UNet、VAE、CLIP、CLIP-Vision、Image Projectionの5つのコンポーネントを持つCrafterのようなものです。
- VAE:VAEは、ToonCrafterから抽出されたのと同じアニメVAEです。Craftersに優れたアニメの時間的VAEを提供してくれたToonCrafterに感謝します。
- 3D-UNet:3D-UNetは、アテンションモジュールのリビジョンを含むCraftersのlvdmから変更されています。コードのいくつかのマイナーな変更以外に、主な変更点は、UNetがトレーニングされ、空間的自己注意レイヤーで時間ウィンドウをサポートするようになったことです。 diffusers_vdm.attention.CrossAttention.temporal_window_for_spatial_self_attentionおよびtemporal_window_typeのコードを変更して、3つのタイプのアテンションウィンドウをアクティブ化できます。
- “prv”モード:各フレームの空間的自己注意は、前のフレームの空間的コンテキスト全体にも注意を払います。最初のフレームは自分自身だけに注意を払います。
- “first”モード:各フレームの空間的自己注意は、シーケンス全体の最初のフレームの空間的コンテキスト全体にも注意を払います。最初のフレームは自分自身だけに注意を払います。
- “roll”モード:各フレームの空間的自己注意は、torch.rollの順序に基づいて、前後のフレームの空間的コンテキスト全体にも注意を払います。
- CLIP:SD2.1のCLIP。
- CLIP-Vision:位置埋め込みを補間することで、任意のアスペクト比をサポートするClip Vision(ViT / H)の実装。線形補間、ニアレストネイバー、および回転位置エンコーディング(RoPE)を試した後、最終的な選択はニアレストネイバーです。これは、画像を224×224にサイズ変更または中央トリミングするCrafterメソッドとは異なることに注意してください。
- Image Projection:2つのフレームを入力として受け取り、各フレームに16の画像埋め込みを出力する小さなトランスフォーマーの実装。これは、1つの画像のみを使用するCrafterメソッドとは異なることに注意してください。
免責事項
このプロジェクトは、人間の描画動作のベースモデルを開発し、将来のAIシステムが人間のアーティストの真のニーズをより適切に満たせるようにすることを目的としています。ユーザーはこのツールを使用してコンテンツを自由に作成できますが、地域の法律を遵守し、責任を持って使用する必要があります。ユーザーは、虚偽の情報を生成したり、対立を扇動したりするためにツールを使用してはなりません。開発者は、ユーザーによる misuseの可能性について、いかなる責任も負いません。
実際に動作させてみた
✨️Google Colabで動作するコードは社会的影響を鑑みて、当面は文末にてメンバーシップのみの公開とさせていただきます✨️
gradio_app.pyの最終行を以下のように変更してください
#block.queue().launch(server_name=’0.0.0.0′)
↓
block.queue().launch(server_name=’0.0.0.0′, share=True)
チュートリアル
Gradioインターフェースに入ったら:
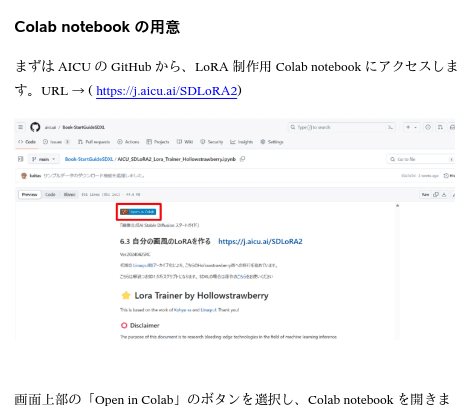
ステップ0:画像をアップロードするか、ページの下部にある[作例画像]をクリックします。

ステップ1:「ステップ1」というタイトルのUIで、[プロンプトの生成]をクリックして、グローバルプロンプトを取得します。

ステップ2:「ステップ2」というタイトルのUIで、[キーフレームの生成]をクリックします。左側でシードやその他のパラメータを変更できます。

ステップ3:「ステップ3」というタイトルのUIで、[ビデオの生成]をクリックします。左側でシードやその他のパラメータを変更できます。
オリジナル画像でやってみた
AICU所属のイラストレーター・犬沢某さんに素材をご提供いただきました。






動画はこちらです
犬沢某さん「なんだか最初のほう、悩みながら描いてるのがそれらしくていいですね・・・」
描画工程を推論する技術は、様々なクリエイティブ工程に役立つツールが生み出せる可能性があります。
オープンな技術として公開していただいた lllyasvielさん、Paints-Undo Teamに感謝です。
https://github.com/lllyasviel/Paints-UNDO
Google Colabで condaをインストールし、Paints-UNDOを利用するnotebook
社会的影響を鑑み、当面はメンバーシップのみの提供とさせていただきます
くれぐれも悪用禁止でお願いいたします。
フェイク動画や、素手で描かれるイラストレーターさんのお気持ちを害するような使い方は誰にとっても利がありません。
原作の免責事項(disclaimer)を再掲しておきます
このプロジェクトは、人間の描画動作のベースモデルを開発し、将来のAIシステムが人間のアーティストの真のニーズをより適切に満たせるようにすることを目的としています。ユーザーはこのツールを使用してコンテンツを自由に作成できますが、地域の法律を遵守し、責任を持って使用する必要があります。ユーザーは、虚偽の情報を生成したり、対立を扇動したりするためにツールを使用してはなりません。開発者は、ユーザーによる misuseの可能性について、いかなる責任も負いません。
この記事の続きはこちらから https://note.com/aicu/n/n7e654dcf405c
Originally published at https://note.com on July 9, 2024.















![[保存版] Animagine XL 3.1 生成比較レポート](https://ja.aicu.ai/wp-content/uploads/2024/07/image-29.png)