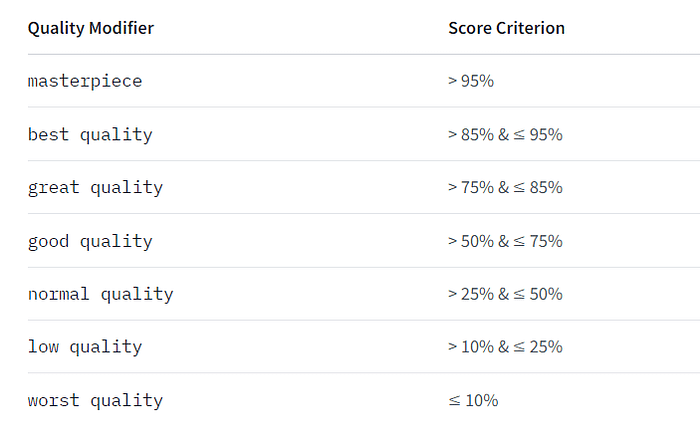
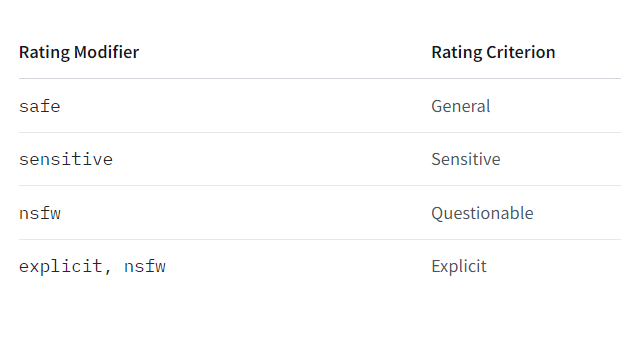
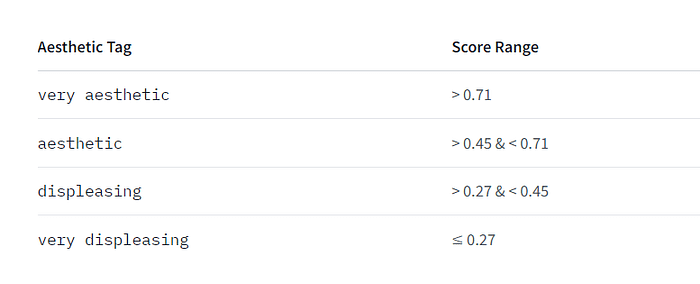
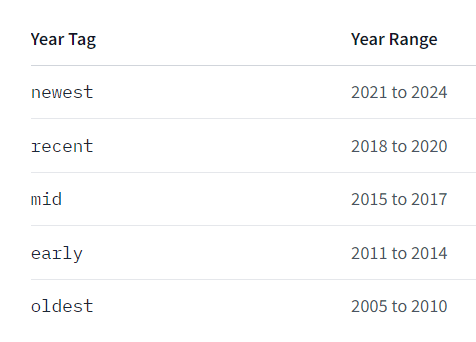2024年8月1日、「ConoHa by GMO」 が画像生成AIサービス「ConoHa AI Canvas」を開始しました。
今回は、この「ConoHa AI Canvas」を、利用者視点・画像生成AIの使い手の視点で忖度なしで2万2千字ほどのガチレビューをしていきたいと思います。
今回のレビュー担当と読み手の設定
今回のレビュー担当であるAICU AIDX Labは、すでにConoHa VPS GPUサーバー を使用したことがあるGoogle ColabもProで使っているが 、AUTOMATIC1111を業務として展開する際にはGoogle側のサービスポリシー変更や突然の停止 があるため代替案を考えねばならない…。
読み手としては以下のような方を対象にしております。
・VPSでWordpressなどをマネージドサービスで立ち上げられる
✨️AUTOMATIC1111の使い方については「SD黄色本 」をどうぞ!(宣伝)
新規アカウント作成の場合
いますぐ、速く構築したい!というひとは新規アカウントを作成しましょう
電話/SMS認証
利用にあたって複雑な審査は不要
ConoHa VPS GPUサーバーでは法人利用、個人利用、本人認証などの審査が必要でしたが、AI Canvasについてはそのような審査は不要だそうです。SMSもしくは電話認証があります。
これだけでダッシュボードにたどり着けます!
既存のConoHaアカウントがある場合
AICU AIDX Labはすでに ConoHa VPS GPUサーバーを使用したことがあるので「ConoHaアカウントをお持ちの方」を選んでみたのですが、結果的にはあまりシンプルではありませんでした。
支払い情報カードの登録
結果から言うと、クレジットカード、特に3Dセキュア2.0対応のカードが必要です。楽天カードはいけました。プリペイドカードは注意です。
https://support.conoha.jp/c/security-3ds/?_ga=2.80313239.109950757.1722495027-668426941.1722335492
「ご利用のサービスを選んでください」というダッシュボードまでたどり着きましょう。
未払がないこと!!
すでに請求中、未払の案件があると新規作成はできません。
未払案件は「決済🔃」のボタンを押すことでConoHaチャージで決済できます(未払は決済しました!すみませんでした!!)。
ConoHaチャージの利用
クレジットカード以外の決済方法は、Amazon Pay、コンビニエンスストア、銀行決済(ペイジー)、PayPalが使えます。クレジットカードでの支払いは3Dセキュア2.0対応が必要ですが、ConoHaチャージ自体は、多様な支払いをサポートしていますので未成年でも利用可能と考えます。また、余ったConoHaチャージがあるのであれば、試すにもちょうどよいのでは。
前払いも可能
自動引落やConoHaチャージによる後払いではなく、
インスタンスの作成と起動・料金計算
コントロールパネル からインスタンスの作成と起動を行います。
いちばん安いのは「エントリー」で495円です。
ここでは「おすすめ!」と書かれている「スタンダード」を選んでおきます(あとで「総評」で評価しましょう)。
今回はスタンダードで自動終了時間設定を60分に設定しておきました。
だいたい5分かからないぐらいでこの状態になりました。
WebUI利用者認証情報の設定
起動したWebUIは世界中に公開されている状態です。生成ごとにコストが掛かりますので、不特定多数に公開した状態はいろいろなリスクが生まれると考えます。
WebUIのログイン画面
あらかじめ設定したユーザー名とパスワードで利用できます。
キター!
AUTOMATIC1111バージョンは1.6.0
下部にバージョン表記があります
API: version: 1.6.0、python: 3.10.9、xformers: N/A、gradio: 3.41.2、 checkpoint: 6ce0161689、torch: 2.0.1+cu118
モデルはSD1.5です。プロンプトを「1girl」として「Generate」ボタンを右クリックしてを「Generate forever」で動作確認します。
AI Canvasのサイトにはサンプルプロンプトも紹介されています。https://www.conoha.jp/ai/canvas/example/
機能拡張のインストールが可能
(多くのWebUI提供サービスで封じられている)
処理能力: 連続生成は2.3秒/gen
SD1.5での「1girl」連続生成は2.3秒/genですね
複雑なプロンプトも実施してみます。
1boy, solo, upper body, front view, gentle smile, gentle eyes, (streaked hair), red short hair with light highlight, hoodie, jeans, newest, 1boy, solo, upper body, front view, gentle smile, gentle eyes, (streaked hair), red short hair with light highlight, hoodie, jeans, newest Negative prompt: worst quality, normal quality, ugly,, worst quality, normal quality, ugly, Steps: 20, Sampler: Euler, CFG scale: 7, Seed: 413102864, Size: 512×512, Model hash: 6ce0161689, Model: v1-5-pruned-emaonly, Version: 1.6.0
Time taken: 2.4 sec.
A: 1.79 GB, R: 3.41 GB, Sys: 3.7/21.9648 GB (16.8%)
L4 GPU, Intel(R) Xeon(R) Gold 5318Y CPU @ 2.10GHz
AUTOMATIC1111下部の「Startup Profile」では起動時間の所要時間を確認できます。
AUTOMATIC1111下部の「Startup Profile」では起動時間の所要時間を確認できます。
Sysinfoによると、L4 GPU, Intel(R) Xeon(R) Gold 5318Y CPU @ 2.10GHz
{
"Platform": "Linux-5.15.0-113-generic-x86_64-with-glibc2.31",
"Python": "3.10.9",
"Version": "1.6.0",
"Commit": "<none>",
"Script path": "/stable-diffusion-webui",
"Data path": "/stable-diffusion-webui",
"Extensions dir": "/stable-diffusion-webui/extensions",
"Checksum": "3253fc9546a1cea4d3b9262670da9f3dd7b418b1a9f25310e13a5afe38253b5c",
"Commandline": [
"webui.py",
"--listen",
"--port",
"7860",
"--enable-insecure-extension-access",
"--disable-safe-unpickle",
"--opt-sdp-attention",
"--opt-channelslast",
"--theme",
"dark",
"--medvram",
"--gradio-auth-path=/gradio/.gradio-auth",
"--hide-ui-dir-config",
"--no-half-vae"
],
"Torch env info": {
"torch_version": "2.0.1+cu118",
"is_debug_build": "False",
"cuda_compiled_version": "11.8",
"gcc_version": "(Debian 10.2.1-6) 10.2.1 20210110",
"clang_version": null,
"cmake_version": "version 3.25.0",
"os": "Debian GNU/Linux 11 (bullseye) (x86_64)",
"libc_version": "glibc-2.31",
"python_version": "3.10.9 (main, Feb 4 2023, 11:55:23) [GCC 10.2.1 20210110] (64-bit runtime)",
"python_platform": "Linux-5.15.0-113-generic-x86_64-with-glibc2.31",
"is_cuda_available": "True",
"cuda_runtime_version": null,
"cuda_module_loading": "LAZY",
"nvidia_driver_version": "535.183.01",
"nvidia_gpu_models": "GPU 0: NVIDIA L4",
"cudnn_version": null,
"pip_version": "pip3",
"pip_packages": [
"mypy-extensions==1.0.0",
"numpy==1.23.5",
"open-clip-torch==2.20.0",
"pytorch-lightning==1.9.4",
"torch==2.0.1+cu118",
"torchdiffeq==0.2.3",
"torchmetrics==1.2.0",
"torchsde==0.2.5",
"torchvision==0.15.2+cu118"
],
"conda_packages": null,
"hip_compiled_version": "N/A",
"hip_runtime_version": "N/A",
"miopen_runtime_version": "N/A",
"caching_allocator_config": "",
"is_xnnpack_available": "True",
"cpu_info": [
"Architecture: x86_64",
"CPU op-mode(s): 32-bit, 64-bit",
"Byte Order: Little Endian",
"Address sizes: 46 bits physical, 57 bits virtual",
"CPU(s): 20",
"On-line CPU(s) list: 0-19",
"Thread(s) per core: 1",
"Core(s) per socket: 1",
"Socket(s): 20",
"NUMA node(s): 1",
"Vendor ID: GenuineIntel",
"CPU family: 6",
"Model: 106",
"Model name: Intel(R) Xeon(R) Gold 5318Y CPU @ 2.10GHz",
"Stepping: 6",
"CPU MHz: 2095.051",
"BogoMIPS: 4190.10",
"Virtualization: VT-x",
"L1d cache: 640 KiB",
"L1i cache: 640 KiB",
"L2 cache: 80 MiB",
"L3 cache: 320 MiB",
"NUMA node0 CPU(s): 0-19",
"Vulnerability Gather data sampling: Unknown: Dependent on hypervisor status",
"Vulnerability Itlb multihit: Not affected",
"Vulnerability L1tf: Not affected",
"Vulnerability Mds: Not affected",
"Vulnerability Meltdown: Not affected",
"Vulnerability Mmio stale data: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown",
"Vulnerability Retbleed: Not affected",
"Vulnerability Spec rstack overflow: Not affected",
"Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp",
"Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization",
"Vulnerability Spectre v2: Mitigation; Enhanced IBRS; IBPB conditional; RSB filling; PBRSB-eIBRS SW sequence; BHI Syscall hardening, KVM SW loop",
"Vulnerability Srbds: Not affected",
"Vulnerability Tsx async abort: Mitigation; TSX disabled",
"Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl xtopology cpuid pni pclmulqdq vmx ssse3 fma cx16 pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves wbnoinvd arat avx512vbmi umip pku ospke avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg avx512_vpopcntdq la57 rdpid fsrm md_clear arch_capabilities"
]
},
"Exceptions": [],
"CPU": {
"model": "",
"count logical": 20,
"count physical": 20
},
"RAM": {
"total": "126GB",
"used": "6GB",
"free": "78GB",
"active": "7GB",
"inactive": "39GB",
"buffers": "2GB",
"cached": "41GB",
"shared": "22MB"
},
"Extensions": [
{
"name": "stable-diffusion-webui-localization-ja_JP",
"path": "/stable-diffusion-webui/extensions/stable-diffusion-webui-localization-ja_JP",
"version": "d639f8ca",
"branch": "main",
"remote": "https://github.com/AI-Creators-Society/stable-diffusion-webui-localization-ja_JP"
}
],
"Inactive extensions": [],
"Environment": {
"GRADIO_ANALYTICS_ENABLED": "False"
},
"Config": {
"outdir_samples": "",
"outdir_txt2img_samples": "/output/txt2img",
"outdir_img2img_samples": "/output/img2img",
"outdir_extras_samples": "/output/extras",
"outdir_grids": "",
"outdir_txt2img_grids": "/output/txt2img-grids",
"outdir_img2img_grids": "/output/img2img-grids",
"outdir_save": "/output/saved",
"outdir_init_images": "/output/init-images",
"font": "DejaVuSans.ttf",
"sd_model_checkpoint": "v1-5-pruned-emaonly.safetensors [6ce0161689]",
"sd_checkpoint_hash": "6ce0161689b3853acaa03779ec93eafe75a02f4ced659bee03f50797806fa2fa"
},
"Startup": {
"total": 7.647331237792969,
"records": {
"launcher": 0.010724067687988281,
"import torch": 2.8648695945739746,
"import gradio": 0.6514277458190918,
"setup paths": 1.2402830123901367,
"import ldm": 0.014907598495483398,
"import sgm": 1.3828277587890625e-05,
"initialize shared": 0.3266317844390869,
"other imports": 0.6456654071807861,
"opts onchange": 0.0003814697265625,
"setup SD model": 0.006415843963623047,
"setup codeformer": 0.10921597480773926,
"setup gfpgan": 0.009504556655883789,
"set samplers": 5.0067901611328125e-05,
"list extensions": 0.0007519721984863281,
"restore config state file": 1.33514404296875e-05,
"list SD models": 0.03431081771850586,
"list localizations": 0.008013725280761719,
"load scripts/custom_code.py": 0.047803401947021484,
"load scripts/img2imgalt.py": 0.0017917156219482422,
"load scripts/loopback.py": 0.001001596450805664,
"load scripts/outpainting_mk_2.py": 0.0024428367614746094,
"load scripts/poor_mans_outpainting.py": 0.0012700557708740234,
"load scripts/postprocessing_codeformer.py": 0.0005180835723876953,
"load scripts/postprocessing_gfpgan.py": 0.00044536590576171875,
"load scripts/postprocessing_upscale.py": 0.0015022754669189453,
"load scripts/prompt_matrix.py": 0.0011546611785888672,
"load scripts/prompts_from_file.py": 0.0012383460998535156,
"load scripts/refiner.py": 0.0005872249603271484,
"load scripts/sd_upscale.py": 0.0009734630584716797,
"load scripts/seed.py": 0.0011196136474609375,
"load scripts/xyz_grid.py": 0.007689714431762695,
"load scripts/bilingual_localization_helper.py": 0.3125584125518799,
"load scripts/ldsr_model.py": 0.03952455520629883,
"load scripts/lora_script.py": 0.1912364959716797,
"load scripts/scunet_model.py": 0.026271343231201172,
"load scripts/swinir_model.py": 0.03376197814941406,
"load scripts/hotkey_config.py": 0.00037789344787597656,
"load scripts/extra_options_section.py": 0.0007958412170410156,
"load scripts": 0.6741135120391846,
"load upscalers": 0.108856201171875,
"refresh VAE": 0.05080389976501465,
"refresh textual inversion templates": 8.678436279296875e-05,
"scripts list_optimizers": 0.00021529197692871094,
"scripts list_unets": 1.33514404296875e-05,
"reload hypernetworks": 0.04795503616333008,
"initialize extra networks": 0.0044841766357421875,
"scripts before_ui_callback": 0.0001342296600341797,
"create ui": 0.7404024600982666,
"gradio launch": 0.0898442268371582,
"add APIs": 0.00691986083984375,
"app_started_callback/lora_script.py": 0.0003218650817871094,
"app_started_callback": 0.0003368854522705078
}
},
"Packages": [
"absl-py==2.0.0",
"accelerate==0.21.0",
"addict==2.4.0",
"aenum==3.1.15",
"aiofiles==23.2.1",
"aiohttp==3.8.6",
"aiosignal==1.3.1",
"altair==5.1.2",
"antlr4-python3-runtime==4.9.3",
"anyio==3.7.1",
"async-timeout==4.0.3",
"attrs==23.1.0",
"basicsr==1.4.2",
"beautifulsoup4==4.12.2",
"blendmodes==2022",
"boltons==23.0.0",
"cachetools==5.3.2",
"certifi==2022.12.7",
"charset-normalizer==2.1.1",
"clean-fid==0.1.35",
"click==8.1.7",
"clip==1.0",
"cmake==3.25.0",
"contourpy==1.1.1",
"cycler==0.12.1",
"deprecation==2.1.0",
"einops==0.4.1",
"exceptiongroup==1.1.3",
"facexlib==0.3.0",
"fastapi==0.94.0",
"ffmpy==0.3.1",
"filelock==3.9.0",
"filterpy==1.4.5",
"fonttools==4.43.1",
"frozenlist==1.4.0",
"fsspec==2023.10.0",
"ftfy==6.1.1",
"future==0.18.3",
"gdown==4.7.1",
"gfpgan==1.3.8",
"gitdb==4.0.11",
"gitpython==3.1.32",
"google-auth-oauthlib==1.1.0",
"google-auth==2.23.3",
"gradio-client==0.5.0",
"gradio==3.41.2",
"grpcio==1.59.0",
"h11==0.12.0",
"httpcore==0.15.0",
"httpx==0.24.1",
"huggingface-hub==0.18.0",
"idna==3.4",
"imageio==2.31.6",
"importlib-metadata==6.8.0",
"importlib-resources==6.1.0",
"inflection==0.5.1",
"jinja2==3.1.2",
"jsonmerge==1.8.0",
"jsonschema-specifications==2023.7.1",
"jsonschema==4.19.1",
"kiwisolver==1.4.5",
"kornia==0.6.7",
"lark==1.1.2",
"lazy-loader==0.3",
"lightning-utilities==0.9.0",
"lit==15.0.7",
"llvmlite==0.41.1",
"lmdb==1.4.1",
"lpips==0.1.4",
"markdown==3.5",
"markupsafe==2.1.2",
"matplotlib==3.8.0",
"mpmath==1.3.0",
"multidict==6.0.4",
"mypy-extensions==1.0.0",
"networkx==3.0",
"numba==0.58.1",
"numpy==1.23.5",
"oauthlib==3.2.2",
"omegaconf==2.2.3",
"open-clip-torch==2.20.0",
"opencv-python==4.8.1.78",
"orjson==3.9.9",
"packaging==23.2",
"pandas==2.1.1",
"piexif==1.1.3",
"pillow==9.5.0",
"pip==22.3.1",
"platformdirs==3.11.0",
"protobuf==3.20.0",
"psutil==5.9.5",
"pyasn1-modules==0.3.0",
"pyasn1==0.5.0",
"pydantic==1.10.13",
"pydub==0.25.1",
"pyngrok==7.0.0",
"pyparsing==3.1.1",
"pyre-extensions==0.0.29",
"pysocks==1.7.1",
"python-dateutil==2.8.2",
"python-multipart==0.0.6",
"pytorch-lightning==1.9.4",
"pytz==2023.3.post1",
"pywavelets==1.4.1",
"pyyaml==6.0.1",
"realesrgan==0.3.0",
"referencing==0.30.2",
"regex==2023.10.3",
"requests-oauthlib==1.3.1",
"requests==2.28.1",
"resize-right==0.0.2",
"rpds-py==0.10.6",
"rsa==4.9",
"safetensors==0.3.1",
"scikit-image==0.21.0",
"scipy==1.11.3",
"semantic-version==2.10.0",
"sentencepiece==0.1.99",
"setuptools==65.5.1",
"six==1.16.0",
"smmap==5.0.1",
"sniffio==1.3.0",
"soupsieve==2.5",
"starlette==0.26.1",
"sympy==1.12",
"tb-nightly==2.16.0a20231024",
"tensorboard-data-server==0.7.2",
"tifffile==2023.9.26",
"timm==0.9.2",
"tokenizers==0.13.3",
"tomesd==0.1.3",
"tomli==2.0.1",
"toolz==0.12.0",
"torch==2.0.1+cu118",
"torchdiffeq==0.2.3",
"torchmetrics==1.2.0",
"torchsde==0.2.5",
"torchvision==0.15.2+cu118",
"tqdm==4.66.1",
"trampoline==0.1.2",
"transformers==4.30.2",
"triton==2.0.0",
"typing-extensions==4.4.0",
"typing-inspect==0.9.0",
"tzdata==2023.3",
"urllib3==1.26.13",
"uvicorn==0.23.2",
"wcwidth==0.2.8",
"websockets==11.0.3",
"werkzeug==3.0.1",
"wheel==0.38.4",
"xformers==0.0.21.dev544",
"yapf==0.40.2",
"yarl==1.9.2",
"zipp==3.17.0"
]
}✨️上記の情報は、AICU AIDX Labが偶然つかんだVPSの情報かもしれません。別の環境を引き当てたひとは是非レポートお願いいたします。
生成した画像の扱い
(多くのAUTOMATIC1111提供サービスでは問題になる)生成した画像の扱いですが、ConoHaのファイルマネージャーで一括してダウンロードできます。これは便利かもしれませんね!
独自モデルのアップロード
今回のガチレビューで最大の注目ともいえる「独自モデルのアップロード」を試してみました。
AUTOMATIC1111/models/Stable-diffusionディレクトリへのアクセスも簡単
大きなファイルも分割してアップロードしてくれるようです。
Animagine XL 3.1をアップロードしてみます。
いったん手元のPCにダウンロードしたファイルをアップロードしてみます。
アップロード中も画像生成できるので、生成しながらアップロードしましょう(利用時間を節約するためにも…)。
だいたい25分ぐらいでアップロードできました。これは接続環境によるかもしれません。
Animagine XL 3.1でのベンチマーク
Animagine XL 3.1公式設定に従い、CFG Scale を5~7程度に下げ、サンプリング・ステップを30以下にし、サンプラーとしてオイラー・アンセストラル(Euler a)を使用することをお勧めします。
https://huggingface.co/cagliostrolab/animagine-xl-3.1
VRAMは上限は低め
GPU NVIDIA L4 は VRAMは24GB搭載されているはずです。
もっと無茶な設定もしてみましたが流石にメモリが足りなくなるようです。CUDA out of memory. Tried to allocate 16.00 GiB (GPU 0; 21.96 GiB total capacity; 11.44 GiB already allocated; 9.10 GiB free; 12.58 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
A: 12.44 GB, R: 16.74 GB, Sys: 17.0/21.9648 GB (77.5%)
この設定で予約しようとしたVRAMが16GB。総容量21.96GBですが、PyTorchに11.44GB割り当て済み、9.10GiB空き…よってアロケート(配分)が12.58GBで予約失敗という状態でした。
まずは1.5倍の1536×1536で再挑戦したところ、問題なくアロケートできました。だいたい1分/genというところです。
生成結果です。高解像度で素晴らしい…!
✨️アップスケーリングは多様な方法があるので、今回みたいな高解像度を生成しながら様子を見る、という使い方は必ずしも正しくはありません。
https://note.com/aicu/n/n6d8ddcdf2544
忘れちゃいけない終了方法
AI CanvasでのAUTOMATIC1111を利用中はダッシュボードに「WebUIを開く」というボタンが表示されています。
AUTOMATIC1111の上部にも(ふだんのAUTOMATIC1111と違い)「WebUIの終了」というボタンが表示されています。
こちらを押すことで、明示的に終了させることができます。
総評:ワークショップ用途であれば最適。
以上の通り、忖度なしのガチレビューを実施いたしました。
比較対象としては、海外の安めのGPUホスティングサービス、例えばPaperspaceというよりは、国内のGPUホスティングサービスが対象になると考えます。
あとは Google Colabでしょう。Google Colab Paid Plan の場合はGoogle 最大のメモリを搭載したマシンにアクセス可能で「1ヶ月あたり1,179円」です。
Google Colab Proは環境として自由度は高いですが、マネージドサービスの一種であり、共有。L4以外のGPUも選択できますが、GPU環境の利用は優先度設定があり、相応のコンピューティングユニットを消費する形です。
さらにAUTOMATIC1111は連続使用が禁止されています。特に連続したサービスとしての使用が禁じられているようで(明示はされていない)、無料アカウントでAUTOMATIC1111を使用していると警告とともに停止します。
https://note.com/aicu/n/n4fcc8c200569
実験・研究・教育用途なら「エントリー」
Google Colabと同じような用途、つまり「実験・研究・教育」という用途で、特にPythonノートブックについて学ぶ要素や、AUTOMATIC1111最新の1.10.xが必要ではない用途であれば「エントリー」が良いと考えます。
AICUのような企業向け・教育向けのワークショップのような用途で使うのであれば、期間限定でも1画像生成あたり2-3秒で提供できるL4環境は魅力的です。
✨️ワークショップの実施についてはこちらからお問い合わせください✨️
https://corp.aicu.ai/ja/pricing
教育機関、未成年の部活動、公金等の研究費等で「クレジットカードが使えない」といった用途であれば、ConoHaチャージでの精算が選択肢になる可能性がありますね。ちなみにConoHaには学割があるようです。
https://www.conoha.jp/gakuwari
業務用途ならストレージで選びたい
今回は単発ワークショップのような期間限定利用ではなく、小規模チームや複数ユーザーが業務的に使う用途、もしくは「GPU搭載PCを増強するまでもないな…」というプロシューマー/ホビー用途での想定です。「おすすめ!」にしたがって「スタンダード」を選んでみましたが、この期間中、いちばん安いのはやはり「エントリー」で495円です。これまでのセットアップのステップを見てもわかりますが、無料枠の1時間ではモデルのアップロードで半分使い切ってしまいます。
上のクラスの「スタンダード」と比較計算してみたところ、仮に1時間以上~5時間以下の使用となる場合、495円+3.3円 x 60分 x 5時間で1485円です。つまり5時間ではなく、「6時間/月ぐらい」からがスタンダードに「おすすめ」の利用時間になります。
注目したいのはストレージです。Google Colabの場合は一時ストレージはColab環境ですが、多くの場合はGoogle Driveのストレージを消費することになります。無料で利用できるかに見えるGoogle Driveの容量ですが、15GBとなると、実際に画像生成AIのモデルをダウンロードしたり、静止生成他画像を保存したりという用途には難しいサイズになります(これは多様な環境でGoogle Colabを使ってきたAICUならではの知見です)。
またGoogle Oneの場合はGeminiがついてきますので、判断が難しいところです。
https://note.com/aicu/n/n73e4937bf165
今回の実験ではスタンダードとエントリーの両方で実験を行いましたが、今回のようなAnimagine XL 3.1を利用した画像生成の例でも13GB程度でした。
上手にストレージを節約して使うのであれば、30GB程度で十分なのかもしれませんね。
API用途では使えないが、GCP/AWSには対抗できる可能性。
VPSとはいえマネージドサービスなので、セキュリティ対策に心配がないのはありがたいですね。GCPやAWSでの同等のAUTOMATIC1111サーバーをL4で運用する場合、数千円で収まる話ではありませんので、まずはそことは価格競争力があります。
「Google Colabを許可されない企業におつとめで、審査等が必要ないがクレジットカードで利用できる国内企業」というマーケットはたしかにありそうです。
次にセキュリティ面です。昔話でありますがshare設定で放置してあるAUTOMATIC1111は危ない ですし、Google Colabでのサービス開放が禁じられているのも、このようなトンネルでの放置サーバー利用が危ないという視点もあります。だからこそ、企業内GPU(オンプレミス)での利用はGradioのVPNトンネルを掘る形になりがちで、それによって社内のセキュリティやファイルアクセスを社外に晒す可能性があり、非常に危険なセキュリティホールになります。
例えばDifyでのStable Diffusionの独自サーバーの利用 や、WordPress向けのプラグインでのAPI利用 といったサービスがありますので、Stability AIの商用ライセンスとともに検討できるといいかもしれませんね!
こういった Stability AI関連のシステム構築の話題は SAI@aicu.ai にお問い合わせいただければ幸いです。クラウドも、VPSも、オンプレミスも、APIサービス化もそれぞれ良いところがあります。
https://j.aicu.ai/ConohaAICanvas
以上です!なにか間違いがあったらすみません!
この記事が面白かった、しかもまだConoHaを試していないアナタ!こちらのリンク からご契約いただけると、AICUのConoHa利用料の足しになるかもしれません…。無理にとはいいませんが、ね!
https://www.conoha.jp
ガチレビュー案件の依頼もお待ちしております!
Originally published at https://note.com on Aug 4, 2024.





































































































![[保存版] Animagine XL 3.1 生成比較レポート](https://ja.aicu.ai/wp-content/uploads/2024/07/image-29.png)