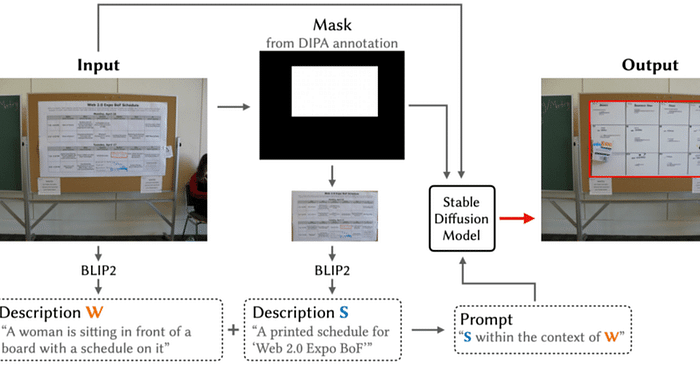
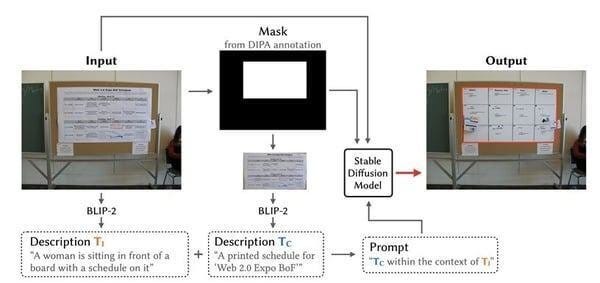
画像生成AIの世界は、日々進化し続けています。その中で、作品にどれだけ細かなディテールを与えられるかが、仕上がりのクオリティを左右する重要なポイントとなっています。美しい風景や繊細なキャラクター、壮大な建築物など、細部までこだわった表現は、見る者の心を掴み、深い感動を呼び起こします。
そんな中、注目を集めているのが「Detail Tweaker XL」というLoRAモデルです。このモデルを使うことで、精緻でシャープなディテールを持つ作品が生み出されます。作品の魅力を一段階引き上げたいと考えているすべてのクリエイターにとって、このモデルは強力な味方となるでしょう。
こんにちわ、AICU media編集部です。
「ComfyUI マスターガイド」第34回目になります。
本記事では、この「Detail Tweaker XL」がどのような特徴を持ち、どのように活用できるのかを詳しく見ていきます。
[ComfyMaster33] 便利LoRA紹介: Envy Zoom Slider XLで画角を調整しよう! #ComfyUI
1. 概要
Detail Tweaker XLは、その名が示す通り、画像の細部を強化することに特化したLoRAモデルです。このモデルを使用すると、生成される画像全体のディテールが著しく向上し、より鮮明で精緻な結果を得ることができます。
https://civitai.com/models/122359/detail-tweaker-xl
具体的には、物体の表面テクスチャがより精密に表現され、細かな凹凸や模様が際立つようになります。また、画像全体のシャープネスが増し、輪郭がくっきりと定義されるため、より「解像度が高い」印象を与える画像が生成されます。これは特に、建築物や自然風景、あるいは精密な機械部品などの複雑な構造を持つ被写体を生成する際に顕著な効果を発揮します。
さらに、Detail Tweaker XLの興味深い特徴として、その汎用性の高さが挙げられます。このLoRAは特定のスタイルや主題に限定されることなく、幅広いプロンプトや設定と組み合わせて使用できます。風景画から人物ポートレート、あるいはSF的な未来世界の描写まで、様々なジャンルの画像生成において、その効果を発揮することができるのです。
Detail Tweaker XLのページの説明では、強度を±3.0の範囲で使用することが推奨されています。また、使い方として、詳細度を上げる場合は、強度を+1.5から開始し、そこから調整していくことがおすすめされています。
2. 使用準備
今回使用するLoRA「Detail Tweaker XL」を以下よりダウンロードし、「ComfyUI/models/loras」フォルダに格納してください。
https://civitai.com/models/122359/detail-tweaker-xl
3. ワークフローの構成
ワークフローは、標準ワークフローにLoad LoRAノードを追加したものになります。モデルにはSDXLのベースモデルを使用しています。

ワークフローは以下よりダウンロードしてください。
- ワークフロー(右クリックで保存)
https://note.com/api/v2/attachments/download/9fa23fa1821fb0c06031cef55c7e30a0
プロンプトは以下の通りです。
- ポジティブプロンプト
1girl, detailed, beautiful, intricate design, delicate, flowing hair, soft lighting, pastel colors, ornate dress, lace, floral patterns, long hair, glowing, ethereal, serene expression, detailed eyes, highly detailed background, flowers, soft shading, elegant, fantasy setting, fairy tale atmosphere, sparkles, graceful, warm tones- ネガティブプロンプト
bad hands, bad anatomy, ugly, deformed, (face asymmetry, eyes asymmetry, deformed eyes, deformed mouth, open mouth)KSamplerノードの各ウィジェットの設定は以下の通りです。
- seed: 747064347533087
- control_after_generate: fixed
- steps: 20
- cfg: 8.0
- sampler_name: euler
- scheduler: normal
- denoise: 1.0
4. 生成結果の検証
まずは、LoRAなしで生成してみます。以下が生成結果です。この状態でも十分に美麗な画像となっています。

次にLoRAの強度を+3.0にし、画像生成してみます。

以下が生成結果です。LoRAなしよりも明瞭になったのではないでしょうか。例えば、周囲の花や、頭の花飾り、ドレスの柄が細かく描写されています。

次は、LoRAの強度を-3.0にし、詳細度を落としてみました。全体的に細かさが減っているように見えます。例えば、頭の花飾りの花が大きくなっていたり、洋服の柄の細かさも少なくなっています。

微妙な違いもあるので、ChatGPTに評価してもらいました。以下がChatGPTの評価結果です。
【レビュー】
1. ディテールの精密さ
・1枚目 (LoRAなし)
ディテールは十分に美しく描かれていますが、特に髪やドレスの質感において、少し柔らかくぼやけた印象があります。特に髪の毛の一本一本や、刺繍の細かい部分はやや滑らかで、精細度が少し低いと感じます。
・2枚目 (LoRA +3.0適用)
LoRAが適用されたことで、全体的に細部がよりシャープに、そして明瞭に見えます。特に髪の毛の一本一本の描写が非常に鮮明で、光の反射や髪の質感がリアルに表現されています。また、ドレスの刺繍部分の細かい装飾がより詳細に描かれており、ドレスの素材感もはっきりと感じられるようになっています。
・3枚目 (LoRA -3.0適用)
LoRAがマイナス強度で適用されているため、ディテールはLoRAなしの状態よりも減少しています。特に、髪の毛の一本一本の描写がやや滑らかになり、ドレスの刺繍や質感も控えめになっています。光の反射や細かいテクスチャがややぼやけており、ディテールが抑えられています。
2. 色の表現
・1枚目 (LoRAなし)
カラーパレットは柔らかく、少し淡いトーンでまとめられており、全体的にやや控えめな印象を与えます。色の深みやコントラストが少し少なく、ふんわりとした雰囲気です。
・2枚目 (LoRA +3.0適用)
LoRAを適用することで、色彩がより豊かに、そして鮮明に表現されています。特にドレスの花の色や背景の光のコントラストがより強調され、色の深みが増しています。全体的に鮮やかで、色が際立って見えます。
・3枚目 (LoRA -3.0適用)
LoRAがマイナス強度で適用されているため、色の表現も抑えられており、少し淡い印象になっています。特にドレスや背景の花々の色がやや薄れており、全体的により控えめで穏やかなトーンになっています。LoRAなしと比べると、少し彩度が低下しているように見えます。
3. 質感の表現
・1枚目 (LoRAなし)
ドレスの素材や髪の質感が柔らかく描かれており、特に繊細な部分において、質感のリアルさが若干欠けている印象です。
・2枚目 (LoRA +3.0適用)
LoRAにより、ドレスの布の繊維や刺繍部分の立体感が増し、髪の質感もよりリアルに描かれています。光の反射や影のつけ方が繊細で、まるで実物に近い感覚をもたらします。
・3枚目 (LoRA -3.0適用)
LoRAがマイナス強度で適用されることで、質感の描写がLoRAなしの状態よりも抑えられています。ドレスの刺繍部分がより滑らかで、立体感が少し薄れており、布地のテクスチャも控えめです。髪の毛の質感も若干ぼやけており、LoRAなしよりも滑らかな印象です。
4. 背景の詳細
・1枚目 (LoRAなし)
背景の窓やキャンドルのデザインが少し滑らかで、細部がぼやけているように感じられます。全体的に柔らかい表現がされています。
・2枚目 (LoRA +3.0適用)
LoRAが適用されているため、背景の装飾や窓のステンドグラスの模様がより細かく描かれており、キャンドルの光の反射や炎の描写も非常に細やかになっています。
・3枚目 (LoRA -3.0適用)
LoRAがマイナス強度で適用されているため、背景の細部がよりぼやけた印象です。特に花々や窓のデザインが柔らかくなり、光の反射や細かい装飾が控えめに描写されています。全体的にソフトフォーカスのような効果があり、背景が少し曖昧になっています。
5. 全体的な印象
・1枚目 (LoRAなし)
全体的にやや柔らかく、ふんわりとした幻想的な雰囲気を持っていますが、細部の描写や質感の表現において少し控えめです。
・2枚目 (LoRA +3.0適用)
LoRAによって細部の精密さが向上し、全体的に高い解像度で描かれています。ディテールが際立ち、特に質感や色の深みが増しているため、よりリアルで華やかな印象を与えます。
・3枚目 (LoRA -3.0適用)
LoRAを-1.5の強度で適用することで、全体がより柔らかく、ぼやけた印象に変わっています。LoRAなしと比較すると、ディテールが減少し、特に質感や色の鮮やかさが控えめで、ソフトな印象が強まっています。幻想的で柔らかい雰囲気が際立つ一方、細部の描写は抑えられており、より優しく控えめな印象を与えます。
【結論】
LoRAを通常の強度で適用すると、画像のディテールが大幅に向上し、質感や色彩、細部がよりシャープでリアルに表現されます。詳細な描写を求める場合、LoRAは効果的です。一方、LoRAをマイナス強度で適用すると、逆にディテールが減少し、全体的に柔らかく、ぼんやりとした印象になります。質感や色彩も控えめになり、幻想的で穏やかな雰囲気が強まるため、LoRAなしよりもシャープさが失われる結果となります。
ChatGPT
結論、プラスの強度でDetail Tweaker XLを適用すると、全体的に詳細に描かれて明瞭な画像となり、マイナスの強度で適用すると、詳細さが失われていくことになります。
5. おまけ: XY Plotで画角の変化を一括で確認
以前の記事で「XY Plot」で生成結果を一括で確認する方法を解説しました。今回もXY Plotを使用して、画角の変化を一括で確認してみます。XY Plotの解説記事は以下になります。
ワークフローの全体像は以下になります。X軸にLoRAの強度、Y軸にSeedを設定しています。

ワークフローは、文末のリンクよりダウンロードしてください。
以下が生成結果です。一括でLoRAの強度の変化を確認できます。Detail Tweaker XLに関しては、遠目では詳細度の違いが分かりづらいので、アップにして確認が必要ですね。

6. まとめ
Detail Tweaker XLは、画像生成においてディテールを強化する優れたLoRAモデルです。特に、複雑な構造やテクスチャの描写において、その効果が顕著に表れます。建築物や自然風景、人物、さらにはSF的なシーンに至るまで、幅広いジャンルで活用でき、ユーザーの創造力を最大限に引き出すツールとなっています。
LoRAの強度をプラスに調整すると、画像は鮮明で精緻な仕上がりとなり、視覚的なインパクトが増します。一方で、強度をマイナスに調整することで、より柔らかく、幻想的な表現を得ることも可能です。これにより、シーンの雰囲気やテーマに合わせた柔軟なアプローチが可能となります。
Detail Tweaker XLは、さまざまなシーンで使用することができ、その汎用性と効果の高さから、クリエイティブな作品づくりに欠かせないツールとなるでしょう。
次回からいよいよComfyUIによる動画編が始まります。乞うご期待!
ここから始める動画編!SDXL+AnimateDiffでテキストから動画を生成しよう!
X(Twitter)@AICUai もフォローよろしくお願いいたします!
画像生成AI「ComfyUI」マスターPlan
画像生成AI「Stable Diffusion」特に「ComfyUI」を中心としたプロ向け映像制作・次世代の画像生成を学びたい方に向けたプランです。最新・実用的な記事を優先して、ゼロから学ぶ「ComfyUI」マガジンからまとめて購読できます。 メンバーシップ掲示板を使った質問も歓迎です。
- メンバー限定の会員証が発行されます
- 活動期間に応じたバッジを表示
- メンバー限定掲示板を閲覧できます
- メンバー特典記事を閲覧できます
- メンバー特典マガジンを閲覧できます
- 動画資料やworkflowといった資料への優先アクセスも予定
ゼロから学ぶ「ComfyUI」マガジン
https://note.com/aicu/m/md2f2e57c0f3c
マガジン単体の販売は1件あたり500円を予定しております。
2件以上読むのであればメンバーシップ参加のほうがお得です!というのもメンバーシップ参加者にはもれなく「AICU Creator Union」へのDiscordリンクをお伝えし、メンバーオンリー掲示板の利用が可能になります。
https://note.com/aicu/membership/boards/61ab0aa9374e/posts/db2f06cd3487?from=self
もちろん、初月は無料でお試しいただけます!
毎日新鮮で確かな情報が配信されるAICUメンバーシップ。
退会率はとても低く、みなさまにご満足いただいております。
✨️オトクなメンバーシップについての詳細はこちら
メンバーシップ加入者向けのおまけ
Detail Tweaker XL に XY-plotを追加したワークフローはこちらです



この記事の続きはこちらから https://note.com/aicu/n/na628f140e954
Originally published at https://note.com on Nov 18, 2024.























![[速報]AICU CEO白井が「ChatGPTとStable Diffusion丸わかりナイト」に登壇いたしました](https://ja.aicu.ai/wp-content/uploads/2024/06/image-2-1.jpeg)