
AICUメディア事業部のKotoneです!
最近LLMについての勉強を始めました。私が今力を入れている画像生成の根元にある技術なので、そもそもの基本的な考え方を知ることができ、とても興味深いです。
さて、今回は当社CFOのKojiから、10月30日(月)から11月2日(木)にシリコンバレーで行われた「ODSC West(Open Data Science Conference)」というデータサイエンスのカンファレンスのレポートが届きました。
Stable Diffusionに関するまとまった講演もあったとのことで、皆さんにご紹介したいと思います!
10月30日(月)から11月2日(木)までODSC West(Open Data Science Conference)がシリコンバレーで実施されました。
シリコンバレーでは生成AIがビジネスの中心と言ってよいほど、データサイエンスやAIに関するカンファレンスやミートアップはさまざまなものが開催されます。本カンファレンスは主に現場のエンジニア向けにフォーカスされており、ワークショップやチュートリアルが中心で、現場で開発に従事していると思われる若手エンジニアが多数参加していました。毎年この時期に開催されていますが、今回の特徴は、昨年夏から急激に盛り上がってきた生成AIについてのプレゼンやワークショップが多数行われたことでした。
私自身これまでオンライン大学などでさまざまなAIやデータサイエンスの講義を受講してきましたが、生成AIに関してはこの1年の進歩が非常に早く,
大学でのカリキュラムの整備がほとんど追いついてない状況です。一方、ODSCは、現場のシニアエンジニアがワークショップ形式で教えるスタイルが主体のため、最新の技術や手法を学ぶのに最も優れているカンファレンスの一つで、今年は特にとても楽しみにしていました。

今回のカンファレンスではStable Diffusionについてのプレゼンがありましたので、ご紹介したいと思います(但し、本件は初心者にも理解できるようにSandeep Singh氏による解説であり、Stability AI社の公式な見解に基づく講演内容ではないことをお含みおきください)。
本件は、「Mastering Stable Diffusion」というテーマで、3つの講演内容で構成されていました。本レポートでは、1番目の「Embark on an Exciting Journey with Generative AI」についてご紹介したいと思います。
プレゼンターは、Beans AI社におけるコンピュータビジョン部門の開発ヘッドであるSandeep Singh氏でした。なお、プレゼン資料の原稿はSandeepさんから直接いただいており、 ブログ記事で日本の読者向けにご紹介することも快諾を得ております。Sandeepさんありがとうございます!
Stable Diffusion: A New Frontier for Text-to-Image Paradigm

単にStable Diffusionの解説のみならず、生成AIの歴史から紐解いた内容で、とてもわかりやすく、興味深い内容でした。

Stable Diffusionは、深層学習のテクニックを使って自動で画像を生成するものですが、単なる技術にとどまらず、知識、人間の興味、理解の探索などのシンフォニーである、というふうにSandeepさんは位置づけています。

Stable Diffusionの技術の基盤となるDeep Learningですが、様々なコンセプトと技術があります。

従来のAIは、データの分析から予測や意志決定を行うものですが、一方、生成AIは学習したパターンから何か新しいものを生み出すもので、従来型のAIを超えたものである、と位置づけています。そのためパラダイムシフトが生まれ、創造性を生む力を持つようになったということです。

生成AIですが、テキスト(LLM、ChatGPT、GoogleBARD、Cohereなど)、画像・映像(Stable Diffusion、Dell-e2、Midjourneyなど)、音声(MusicLMなど)等があります。
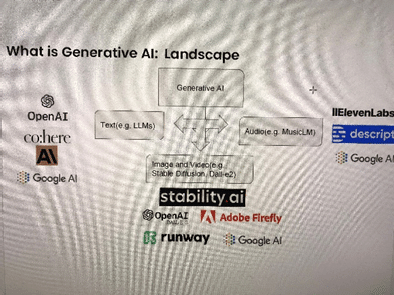
2014年あたりから生成AIのモデルが登場しはじめ、次第に複雑で高度なものに進化していきました。2020年以降、生成能力が人間を超えるものが登場し、専門家の間では話題となっておりました。さらには2022年には一般ユーザが簡単に利用できるレベルのものが登場し、世界中の注目を集めることになりました。
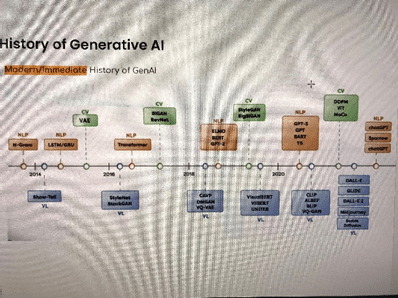
画像生成の世界では、VAE、GAN、CLIP、GLIDEなどが次々と登場し、2022年夏頃にStableDiffusion、Dall-e2、Midjourney、Imagenなどが発表され、世間の認知度が一気に高まることになりました。
Stable Diffusionの登場
それでは、なぜStable Diffusionは注目すべきものなのでしょうか?それは、テキストからイメージを作ることができる驚異的な技術であることは言うまでもないことですが、Diffusion Model(拡散モデル)を使った世界初のオープンソースの技術であることです。元はと言えば、流体やガスの物理現象を応用したものです。同時期に登場したDalle2(OpenAI社)、Imagen(Google)なども類似の技術を使っているものと思われますが、残念ながら未公開です。

Stable Diffusion: Why care?
*Almost all Text-to-Image techniques are Inspired by This!
*Poster Child of Text-to-Image Model.
*First Open Source State of Art Diffusion Model.
*Inspired by Physics of Fluids/Gases
*Improved Image Reconstruction
*Robustness to Variability, more resilient to changes in illumination, contrast
*Enhanced Edge Preservation as in Image above.
Stable Diffusionは何がすごいのか?
- ほとんどのText-to-Imageテクニックはこれにインスパイアされている!
- Text-to-Imageモデルの「わかりやすい姿」(Poster Child)
- 初のオープンソースによる最先端の拡散モデル
- 流体/気体の物理学にインスパイアされている
- 画像再構成の改善
- 変化に強く、照明やコントラストの変化に強い
- エッジ保存を強化している
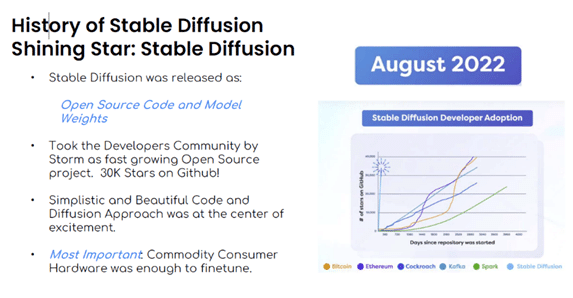
2022年は、画像生成AIにとって驚異的な年となりました。OpenAIは4月にDalle2を発表し、5月にはGoogleがAmagenを、Midjorneyが7月に発表と、次々と高度なツールが発表されたのです。しかし、いずれも素晴らしいものではありましたが技術内容は未公開であったため、研究者やコミュニティによって評価を行うこと自体が困難でした。

そして、2022年8月Stable Diffusionが登場しました。Stable Diffusionは世界初のオープンソースモデルであることから、多くの研究者や技術者から注目されました。単純で美しいコードによるDiffusionアプローチには、興奮が沸き起こりました。さらに重要なこととして、コモディティ化されたハードウエアで動かすことが可能、ということがわかり、世界中の多くの研究者や技術者、そして一般人までが一気に飛びついたのでした。
ここから先の歴史についてはみなさんご存知のことも多いかと存じます。
レポートは次回に続きます。
生成AI(GenerativeAI)という言葉が世間で言われるようになったのはここ2、3年のことなので、2014年のAIというのは全く馴染みが無く、逆に新鮮に聞こえてしまいました。こうして振り返って見ると、とても短い期間に画像生成AIが広まっていったことが再確認できますね。
Kotone&しらいはかせの感想
Kotone:VAE、GAN、CLIPなどはStable Diffusionをさわっていると時々視界に入る単語ですね!
はかせ:「 AIとコラボして神絵師になる 論文から読み解くStable Diffusion」で解説したつもりだったのですが、公開から1年、さらに俯瞰する時期が来ているかもしれませんね。
Kotone:用語集助かります、整理して勉強していきたいと思います。
はかせ:私は 東京工業大学 総合理工学研究科 知能システム科学 という専攻で博士を取得したのですが、当時は「知能システム」という分野は1970年代からサイバネティックス、ロボット・制御工学といった分野で研究されていました。もちろん2000年ごろにはすでに機械学習といった分野も存在し、研究室では強化学習、バックプロパゲーションなどをシミュレーションしたり、VRで体験できるようにしたり、ソフトウェアロボットにしたり、それを人間の脳から筋骨格系への信号と比較したり…といった研究です。制御となると目標とすべき正解やゴールがありますが、私の分野のようにエンタテインメント、アート、インタラクティブといった分野は定義も難しく、推論をするにも正解は何なのか、といったところで議論が終わる事が多かったです。
講演は続きます。次回は Stable Diffusionの内部構造、仕組みについての解説になるそうです!
Originally published at https://note.com on November 16, 2023.