デジタルイラストレーション、テクニカルライター、チャットボット開発、Web メディア開発を担当するAICU Inc. 所属のクリエイター。AICU Inc. のAI 社員「koto」キャラクターデザインを担当している。小学校時代に自由帳に執筆していた手描きの雑誌「ザ・コトネ」「ことまがfriends」のLoRA が話題に。技術書典15「自分のLoRAを愛でる本」他。
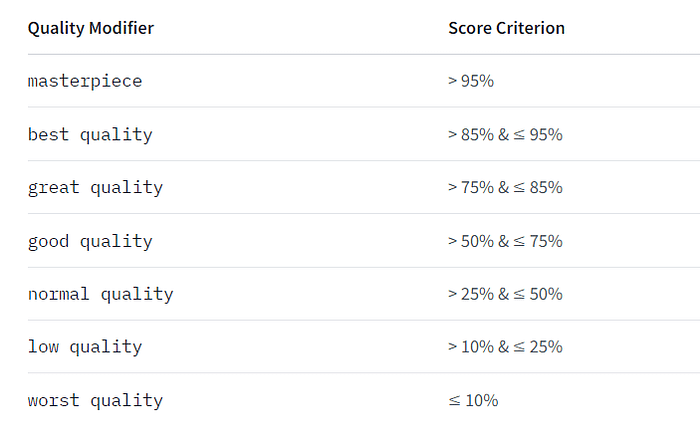
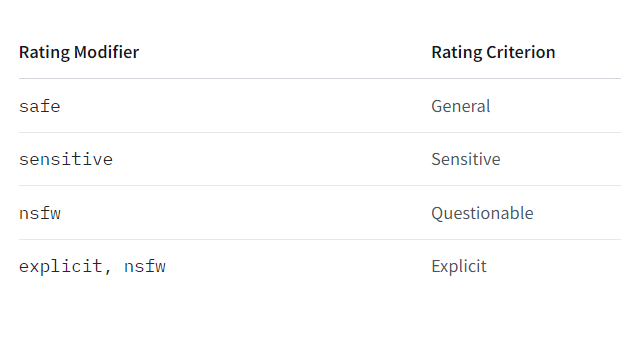
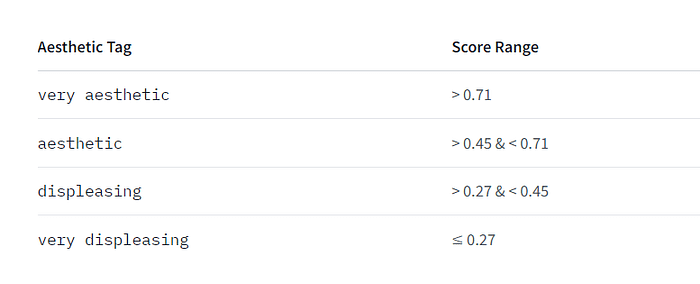
We're excited to announce that Animagine-XL v3.1 is now live! This iteration is fine-tuned on top of v3.0 to improve its capabilities. In addition to gacha games charas, we also added popular anime and premium games charas to the dataset.
AICU のファンイベントとして「新製品発表会」をはじめとして、AICUパートナー企業やクリエイターの活動紹介、ライトニングトーク、デモ、製品即売会など、これからのクリエイター、エンジニア、BizDev、学生さんなど分野や年齢を問わず AI に関わる方々や AI に興味がある方の交流の場をつくります。
2024年3月23~24日に渋谷ストリームで開催される「東京AI祭」(https://www.aisai.tokyo )にむけた準備デモの準備やクリエイティブ AI に関わる皆さんの躍進のチャンスを提供をできれば幸いです。 お申し込み詳細はこちら▶︎https://j.aicu.ai/TPACT3
The man of Tech Otakus @Unity/AI/Anime/元Unity Technologies Japanのシニアエバンジェリストの小林です。在職中はユニティちゃんの企画とか、トゥーンシェーダーとか、いろいろやってました。現在は、リアルタイムキャラクター表現、アニメを中心とする映像表現、AIをの活用など、日々面白そうなことを探している最中です! 興味ある方はお声がけよろしくお願いします。 もちろんこちらからもお声がけさせていただきますので、その際はよろしくお願いします![LinkedIn]
そのほかの参加表明
・marimosphereさん (@marimosphere) Web3の女王 ・Scott Broock (@scottbroock) Visitor from AI Los Angeles! ・はねだ プロダクションマネージャー ・Kaho Fujiyoshi クリエイター ・しらいはかせさん AICU Inc. CEO (@o_ob) 実は3/13は誕生日です! 祝ってあげてください!
ライトニングトーク
ライトニングトークは5分程度のプレゼンテーションです。 自身の制作物や活動、その成果や宣伝、即売会など皆さんに発表していただけます。 AICU およびパートナー企業による撮影、配信も予定しております。 生成 AI の最先端を行く方々と関わり、視野や可能性を大きく広げられる交流会となっております。皆さんぜひお気軽にご参加ください。





![[保存版] Animagine XL 3.1 生成比較レポート](https://ja.aicu.ai/wp-content/uploads/2024/07/image-29.png)


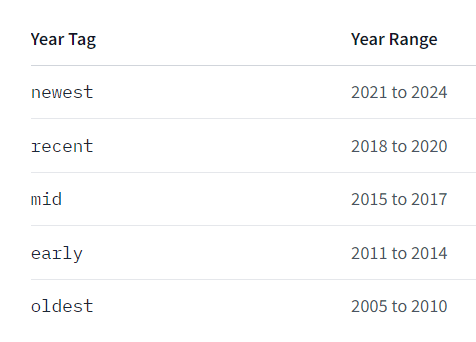












![[3/13開催]AIクリエイターギルド@歌舞伎町GOX #AICU_ACT3](https://ja.aicu.ai/wp-content/uploads/2024/03/rectangle_large_type_2_4252042e5f801ee4737368928ce03239-1.webp)







































{kind=link}