
世界中のコンピュータビジョンとパターン認識の最先端の論文が集まる国際会議「CVPR2024」採択論文が公開されました。
https://cvpr.thecvf.com/Conferences/2024/AcceptedPapers
採択論文の中に「FAMix」という自動運転車のためのコンピュータビジョン研究で、興味深い論文があったので しらいはかせさん(X@o_ob)が 紹介します。
🍴 FAMix 🍴
A Simple Recipe for Language-guided Domain Generalized Segmentation
(FAMix: 言語ガイド付きドメイン一般化セグメンテーションのためのシンプルなレシピ)
モハマド・ファヘス、トゥアン・フン・ヴー、アンドレイ・ブルスク、パトリック・ペレス、ラウル・ド・シャレット – Inria, パリ, フランス valeo.ai, パリ, フランス
INRIAはフランスの国立情報学研究所です https://www.inria.fr/en
Valeo.ai は自動車アプリケーション向けの人工知能研究センター
Mohammad Fahes さんによる研究

Mohammad Fahes さんは Inriaとvaleo.aiの共同グループであるAstra-visionの博士課程2年生です。現在、Raoul de Charette、Tuan-Hung Vu、Andrei Bursuc、Patrick Pérezの指導の下、様々な条件下におけるラベルとデータ効率の良い2Dシーン理解について研究しています。ENS Paris-Saclayで数学、視覚、学習の修士号、Mines Parisで工学の学位、レバノン大学で機械工学の学位を取得。
https://mfahes.github.io
YouTube動画におけるFAMixの定性的結果
プロジェクトページ: https://astra-vision.github.io/FAMix/
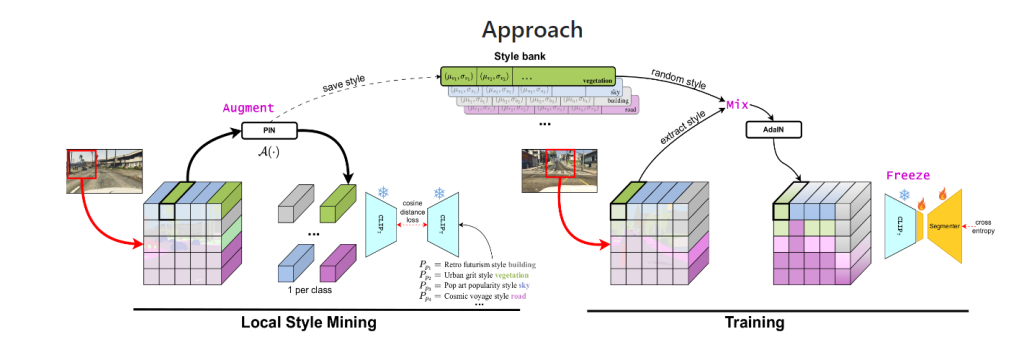
トレーニング中に見られなかった新しいドメインへの汎化は、実世界のアプリケーションにニューラルネットワークを導入する際の長年の目標であり課題の1つである。既存の汎化技術では、外部データセットから得られる可能性のある大幅なデータ増強が必要であり、様々なアライメント制約を課すことで不変な表現を学習することを目指している。最近、大規模な事前学習が、異なるモダリティを橋渡しする可能性とともに、有望な汎化能力を示している。例えば、CLIPのような視覚言語モデルの最近の出現は、視覚モデルがテキストモダリティを利用する道を開いた。本稿では、ランダム化の源として言語を用いることで、セマンティック・セグメンテーション・ネットワークを一般化するためのシンプルなフレームワークを紹介する。すなわち、i) 最小限の微調整によるCLIP本来のロバスト性の維持、ii) 言語駆動型の局所的スタイル拡張、iii) 学習中にソーススタイルと拡張スタイルを局所的に混合することによるランダム化、である。広範な実験により、様々な汎化ベンチマークにおける最先端の結果が報告されています。コードは公開予定。
https://astra-vision.github.io/FAMix/
19都市のパノラマ画像「ACDC」データセット、カリフォルニア大学バークレー校のAIラボ(BAIR)が公開する運転中の動画データセット「BDD100K」 (BDD100K: A Large-scale Diverse Driving Video Database)、ピクセルレベル、インスタンスレベル、汎視野的セマンティックラベリングのための「The Cityscapes Dataset」(高画質アノテーション付き画像5,000枚 – 粗いアノテーション付き画像20,000枚 – 50の異なる都市)、世界中のストリートシーンを理解するための、ピクセル精度とインスタンス固有のヒューマンアノテーションを備えた、多様なストリートレベルの画像データセット「Mapillary Vistas Dataset」、これは25 FPSで生成されたビデオストリームで空、建物、道路、歩道、フェンス、植生、電柱、車、交通標識、歩行者、自転車、車線、信号、セグメンテーション、2Dバウンディングボックス、3Dバウンディングボックス、奥行き情報が含まれるアクティブ・ラーニング用のデータセット「SYNTHIA」そして、GTA5(グランセフトオート)を使った事前学習で、YouTubeの未知の走行動画でのパリ、ベイルート、ニューデリー、ヒューストン、つまり実際に行ったことがない都市でのセグメンテーション(領域分割)が機能しています。
なお、グランドセフトオート(GTA5)を使った学習手法は、2016年にECCV2016(European Conference on Computer Vision)において提案されていました。49時間にわたる収録を手作業によりラベル付けを行っています。
2016年にドイツのダルムシュタット工科大学とインテルラボの科学者によって開発された「Playing for Data: Ground Truth from Computer Games」という研究で、「Grand Theft Auto V」のオープンワールドでのプレイ時の視覚情報をデータセットとして利用しています。
Playing for Data: Ground Truth from Computer Games
http://download.visinf.tu-darmstadt.de/data/from_games/index.html
最近のコンピュータビジョンの進歩は、大規模なデータセットで学習された大容量モデルによって牽引されている。しかし残念ながら、ピクセルレベルのラベルを持つ大規模なデータセットを作成することは、人間の労力を必要とするため、非常にコストがかかる。本稿では、最新のコンピュータゲームから抽出された画像に対して、ピクセル精度の意味ラベルマップを高速に作成するアプローチを紹介する。商用ゲームのソースコードや内部動作にはアクセスできないが、ゲームとグラフィックスハードウェア間の通信から画像パッチ間の関連付けを再構築できることを示す。これにより、ソースコードやコンテンツにアクセスすることなく、ゲームによって合成された画像内および画像間で意味ラベルを迅速に伝播することが可能となる。我々は、フォトリアリスティックなオープンワールドコンピュータゲームによって合成された25,000枚の画像に対して、高密度のピクセルレベルの意味的注釈を生成することによって、本アプローチを検証する。セマンティックセグメンテーションのデータセットを用いた実験では、実世界の画像を補完するために取得したデータを用いることで精度が大幅に向上すること、また、取得したデータを用いることで、手作業でラベル付けした実世界のデータ量を削減できることが示された:ゲームデータとCamVid学習セットのわずか1/3で学習したモデルは、CamVid学習セット全体で学習したモデルよりも優れている。
データ データセットは、便宜上10分割された24966の高密度にラベル付けされたフレームで構成されている。クラスラベルはCamVidとCityScapesデータセットと互換性がある。ラベルマップを読み込むためのサンプルコードと、トレーニング/検証/テストセットへの分割をここに提供します。ラベルマップの小さなセット(60フレーム)は、対応する画像と解像度が異なることに注意してください(Dequan Wang氏とHoang An Le氏の指摘に感謝します)。また、このデータは研究・教育目的にのみ使用されることに注意してください。
さてプロジェクト「FAMix」(公開された論文タイトルは:ASimple Recipe for Language-guided Domain Generalized Segmentation/言語ガイド付きドメイン汎化セグメンテーションの簡単なレシピ)はセマンティックセグメンテーションのためのドメイン汎化(DGSS)をシンプルな材料の組み合わせによるDGSSの効果的なレシピとして提案しています。上記で紹介したデータセットに加え、Stable Diffusionの内部でも使われている言語と画像のマルチモーダル基盤モデル「CLIP」を使用し、最小限の微調整によるCLIP本来のロバスト性の維持、ii) 言語駆動型の局所的スタイル拡張、iii) 学習中にソーススタイルと拡張スタイルを局所的に混合することによるランダム化、そしてImageNetとの比較も行っています。分類、領域分割といったタスクに状況説明のような言語での説明ができることが新たな安全性を生み出す可能性もありますね。
Valeo.aiのWebサイトにはこのような例が挙げられています。

不確実性の推定:予期せぬ事態が発生した場合、天候が悪化した場合、センサーが遮断された場合、乗船した知覚システムは状況を診断し、代替システムや人間のドライバーを呼び出すなど、適宜対応する必要があります。このことを念頭に置き、システムの不確実性を評価し、その性能を予測する自動的な方法を研究しています。
GTA5自体も2013年(11年前)にリリースされた「悪に憧れる全ての人」に向けた爽快なオープンワールドクライムアクションですが、コンピュータビジョンの世界は、舞台となるリアルに描き起こされたアメリカ西部の海岸地帯「ロス・サントス」での自動車強盗だけでなく、未来の実世界の安全走行に寄与しているのがおもしろいですね。
「つくる人をつくる・わかるAIをつたえる」AICU mediaは学術論文の解説記事を募集しています。
寄稿された方にはAmazonギフト券ほか薄謝を進呈いたします。
詳しくはX(Twitter)@AICUai までDMにて御御相談ください。