ベースとなった共通プロンプト: {style*} best quality, trending on art station, looking at viewer, 1girl has a panel which is written [AICU], V-sign , in Shibuya crossroad
今回は最終的に動画を作ることになりましたので、もし同じ実験を追従される方がいらっしゃいましたら、生成時間の測定、連番ファイルでの生成やデータベースとの連動なんかも考えてみるとその後の活用がしやすいのかなと思いました。特に生成時間はローカルGPUや Google Colabでの生成と比較しても非常に高速で、数秒です。これ自身が価値あると考えます。
映像制作目的では、Google Apps Script + Google Slidesでのバリエーション広告での活用事例などもご参考にいただければ幸いです。AICU AIDX Labとしては、カスタマイズ依頼も歓迎です。
この画像の場合には、ファイル名が analog-film style, best quality, trending on art station, looking at viewer, 1girl has a panel which is written [AICU], V-sign , in Shibuya crossroad_14117_1_Ca.png となっています。
modeling-compound style, best quality, trending on art station, looking at viewer, 1girl has a panel which is written [AICU], V-sign , in Shibuya crossroad_9240_5_Ca.png こちらもCa、つまりCoreAPIでプロンプト指定によって生成されています。CoreAPIには文字を描く能力はないはずですが、胸には「ACU」の文字が確認できます。指は本数は5本できちんとVサインをしていますが、掌と親指がちょっと怪しげな結果です。しかしこのぐらいであればPhotoshopや image to image で修正できる可能性は高いと考えます。
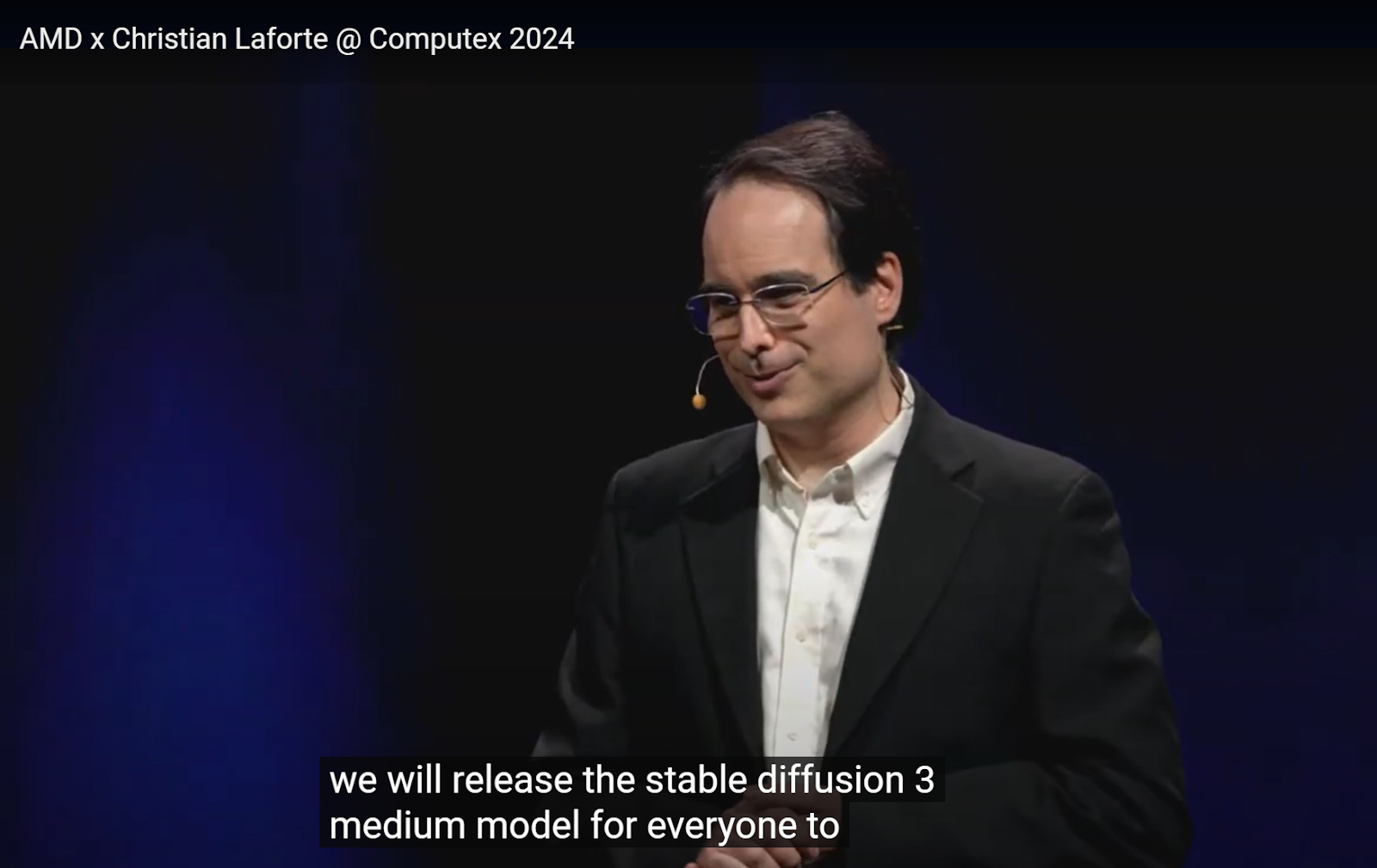
Stable Diffusion 3 シリーズの最新かつ最も高度なテキストから画像へのAIモデルである Stable Diffusion 3 Medium を発表できることを嬉しく思います。Stable Diffusion 3 Medium は、生成AIの進化における重要なマイルストーンであり、このパワフルなテクノロジーを民主化するというStability AI のコミットメントを継続するものです。
SD3 Medium の特徴
SD3 Medium は、SD3の20億パラメーターモデルで、いくつかの特筆すべき特徴を備えています。
NVIDIAとコラボレーションし、NVIDIA® RTX™ GPUとTensorRT™を活用することで、Stable Diffusion 3 Medium を含むすべてのStable Diffusion モデルのパフォーマンスを強化しました。TensorRT で最適化されたバージョンは、クラス最高のパフォーマンスを提供し、パフォーマンスが50%向上します。
TensorRT に最適化された Stable Diffusion 3 Medium にご期待ください。
AMD とのコラボレーション
最新のAPU、コンシューマー向けGPU、MI-300XエンタープライズGPUなど、さまざまなAMDデバイス向けにSD3 Medium の推論を最適化しています。
オープンでアクセスしやすいモデル
オープンな生成AIへの Stability AI のコミットメントは揺るぎません。Stable Diffusion 3 Medium は無償の非商用ライセンスでリリースされ、Hugging Face を通じて入手可能です。アーティスト、デザイナー、開発者、AI愛好家の皆さまは新しいクリエイターライセンスをご利用ください。
Stability AI は、安全で責任あるAIの実践を信じています。これは、悪意ある者による Stable Diffusion 3 Medium の悪用を防ぐために、合理的な手段を講じ、それを継続することを意味します。安全性は、モデルのトレーニングを開始した時点から始まり、テスト、評価、デプロイを通して継続します。Stability AI は、このモデルの広範な内部および外部テストを実施し、危害を防止するための数多くのセーフガードを開発し、実施してきました。
研究者、専門家、そしてコミュニティと継続的に協力することで、モデルを改善し続けながら、誠実にさらなる革新を進めていきます。Stability AI の安全性へのアプローチについての詳細は、 Stable Safety をご参照ください。
ライセンス
Stable Diffusion 3 Mediumは、Stability Non-Commercial Research Community Licenseの下でリリースされています。 Stability AI は、コミュニティが Stable Diffusion 3 を活用することを奨励すると同時に、AIをオープンでアクセス可能な状態に保つというミッションのもと、新しいクリエーターランセンスを導入しました。プロのアーティスト、デザイナー、開発者、AI愛好家の皆様には、クリエーターライセンスを利用して、Stable Diffusion を使った開発を始めることをおすすめします。
大規模な商用ユーザーや企業の方は、ご連絡いただき、エンタープライズライセンスを取得してください。これにより、Stability AI の利用ガイドラインを遵守しながら、皆さまがモデルの可能性を最大限に活用できるようになります。
Stability AIより:今後の展開
皆さまからのフィードバックに基づき、Stable Diffusion 3 Medium を継続的に改善し、機能を拡張し、パフォーマンスを向上させる予定です。Stability AI の目標は、AI生成アートにおける創造性の新たな基準を設定し、Stable Diffusion 3 Medium をプロと趣味利用の方の双方に不可欠なツールにすることです。