ComfyUIを使いこなしている皆さん、画像生成の可能性をさらに広げてみませんか?今回は特別編、画像内の髪型をAIが自動で検出し、思い通りの髪型に自由自在に変換する、一歩進んだ応用ワークフローをご紹介します。
人物画像の髪型を変更したいと思った時、従来の画像編集ソフトでは、髪を選択して細かく加工する必要があり、非常に手間がかかりました。しかし、ComfyUIとStable Diffusionを組み合わせることで、プロンプトで指定するだけで、まるで魔法のように髪型を変更することが可能になります。
こんにちわ、AICU media編集部です。
「ComfyUI マスターガイド」第22回目になります。
この記事では、Florence2とSAM2による髪と人物のマスク作成、背景の自動補完、インペイントによる髪型生成、そして最終的な画像合成と補正といった、ワークフローの全貌を詳細に解説します。ComfyUIのノードを活用した高度な画像処理をマスターし、Stable Diffusionによる画像生成を新たなレベルに引き上げましょう!
前回はこちら
▼[ComfyMaster22] レイアウトそのままにアニメを実写化!image-to-imageとスタイル変換で実写化レベルを制御 #ComfyUI
1. 今回実装する処理のフロー
髪型の変更については既に、インペイントのモデルコンディショニングを使って、こちらの記事で解説いたしました。
▼[ComfyMaster20] ComfyUIの高度インペイント技術で自然な髪型変更を実現!#ComfyUI #InpaintModelConditioning
今回の処理は、髪型を変更したい画像に対して、自動で髪の毛を検出し、プロンプトで指定した任意の髪型に変更するワークフローです。大まかな処理の流れは、以下になります。
- Florence2とSAM2で髪と人物のマスクを別個で作成する
- 背景から人物を取り除き、人物がいた箇所を補完する
- 髪のマスクと、人物のマスクを反転させて作成した背景のマスクを合成し、髪と背景のマスクを作成する
- 髪と背景のマスクを利用してインペイントを実行し、任意の髪型を生成する
- 補完した背景と、任意の髪型に変更した人物の画像を合成し、1枚の画像にする
- 合成した画像に対して、低めのDenoising strengthでサンプリングを行い、人物と背景を馴染ませる
このフローにより、画像とプロンプトを与えることで、自動で髪型を変更することができます。
2. 使用するカスタムノード
今回使用するカスタムノードは、以下の通りです。それぞれComfyUI Managerからインストールしてください。
ComfyUI-Florence2
ComfyUI-Florence2は、Florence2をComfyUIで使用するためのカスタムノードです。Florence2は、Microsoftが開発した視覚言語基盤モデルで、画像キャプション生成、物体検出、ビジュアルグラウンディング、セグメンテーション、文字認識、など、幅広いビジョンタスクを実行できます。今回は、プロンプトからのオブジェクト検出(髪と人物)を実現するために使用します。
なお、Florence2に必要なモデルは、インストール時に「ComfyUI/models/LLM」フォルダに自動でダウンロードされます。
リポジトリは、以下になります。
https://github.com/kijai/ComfyUI-Florence2
ComfyUI-segment-anything-2
ComfyUI-segment-anything-2は、SAM2 (Segment Anything Model 2) をComfyUIで利用するためのカスタムノードです。SAM2は、Metaが開発した最新のオブジェクトセグメンテーションモデルで、画像と動画の両方に対応しています。今回は、Florence2で検出した髪や人物をセグメンテーションし、マスクを作成するためにSAM2を使用します。
SAM2に必要なモデルは、Kijai氏のHugging Faceのリポジトリから「ComfyUI/models/sam2」フォルダに自動でダウンロードされます。
リポジトリは、以下になります。
https://github.com/kijai/ComfyUI-segment-anything-2
comfyui-tensorop
ComfyUI-TensorOpは、ComfyUIでテンソル操作を行うためのノードセットです。今回のワークフローで、このノードを直接使用することはありませんが、ComfyUI-Florence2内で使用されているため、インストールが必要になります。
リポジトリは、以下になります。
https://github.com/un-seen/comfyui-tensorops
ComfyUI WD 1.4 Tagger
ComfyUI WD 1.4 Taggerは、画像からDanbooruタグを取得するためのカスタムノードです。背景と人物の合成後の調整でのサンプリングの際に、画像からタグを抽出し、それをプロンプトとして利用するために使用します。
リポジトリは、以下になります。
https://github.com/pythongosssss/ComfyUI-WD14-Tagger
ComfyUI Inpaint Nodes
ComfyUI Inpaint Nodesは、画像のインペイント(欠損部分の補完)をより効果的に行うためのノードセットです。変更後の髪の生成に使用します。
リポジトリは、以下になります。
https://github.com/Acly/comfyui-inpaint-nodes
ComfyUI-KJNodes
ComfyUI-KJNodesは、ComfyUIの既存ノードの機能を組み合わせて作成された便利なノードを提供しています。今回使用するサンプルワークフローで、このカスタムノードを使っているため、インストールが必要になります。インストールは、ComfyUI Managerから可能です。
リポジトリは、以下になります。
https://github.com/kijai/ComfyUI-KJNodes
3. 使用するモデル
チェックポイント
今回は、RealVisXL_V4.0を使用しました。他のSDXLモデルでも問題ありません。以下のリンクよりダウンロードし、「ComfyUI/models/checkpoints」に格納してください。
https://huggingface.co/SG161222/RealVisXL_V4.0/blob/main/RealVisXL_V4.0.safetensors
LoRA
LoRAにMidjourney Mimicを使用します。Midjourney Mimicは、Midjourneyのような美麗な画像を生成するためのLoRAです。全体的に綺麗な画像を生成できるように、このLoRAを使用しています。以下のリンクよりLoRAをダウンロードし、「ComfyUI/models/loras」フォルダに格納してください。
ControlNet
ControlNetには、AnyTest V4を使用します。AnyTest V4は、形状維持をしつつ、スタイル変換の余地を残した柔軟なControlNetです。以下のリンクよりダウンロードし、「ComfyUI/models/controlnet」フォルダに格納してください。
インペイント
インペイントで使用するモデルにMAT_Places512_G_fp16を使用します。以下のリンクよりダウンロードし、「ComfyUI/models/inpaint」フォルダに格納してください。
https://huggingface.co/Acly/MAT/blob/main/MAT_Places512_G_fp16.safetensors
4. 使用する画像素材
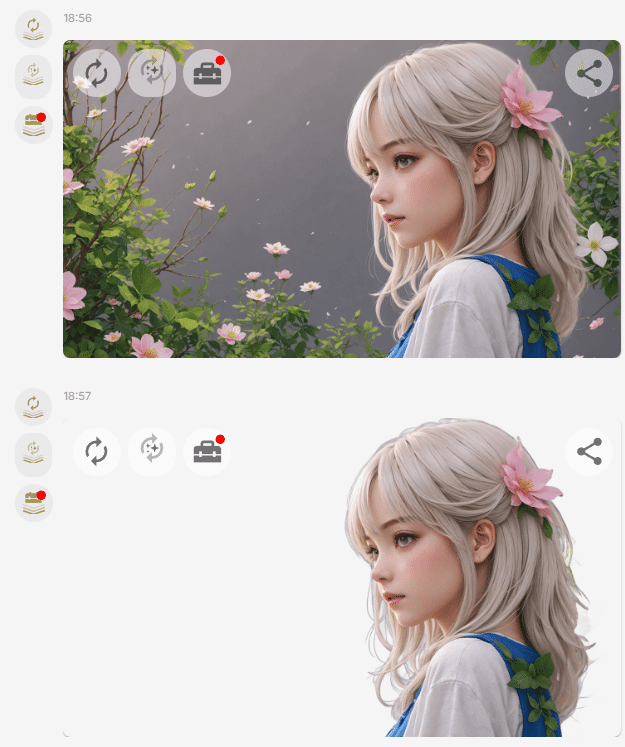
今回は、以下の画像に対して髪形変更処理を行います。

☆ワークフローのJSONファイルと画像ファイルは文末にございます
5. ワークフローの全体像
ワークフローの全体像は以下になります。

このワークフローをフローチャート化したものが以下になります。

各ノードの詳細は以下になります。グループごとに解説します。
- 画像読み込み: 元の画像を読み込みます。
- 物体検出: Florence2モデルを使用して、元の画像内の髪と人物を検出します。
- 領域分割: SAM2(Segment Anything Model 2)を使用して、髪と人物の正確なマスクを作成します。
- マスク処理: 人物のマスクを反転し作成した背景マスクと、髪のマスクを合成し、インペイント用の領域を作成します。
- 背景生成: 人物マスクを利用して、マスクされた領域を埋めるための背景を別のプロセスで生成します。
- インペイント: 背景マスクと髪マスクを合成したマスクを利用して、髪型を変更するインペインティングを行います。
- 初期サンプリング: 背景マスクと髪マスクを合成したマスクを利用したインペインティングで、新しい髪の初期バージョンを作成します。
- 人物マスクの再作成: Florence2とSAM2を再度使用して、初期サンプリングで生成された画像から人物を検出し、マスキングします。
- 画像合成: 再作成された人物マスクを利用して、背景画像と初期サンプリングで生成された画像を合成します。
- 最終サンプリング: 合成された画像を弱いdenoiseでサンプリンクし、最終的な画像を洗練します。
6. ワークフロー解説
ここでは、セクションごとに処理内容を解説します。
Florence2によるオブジェクト検出

- まず、DownloadAndLoadFlorence2ModelノードでFlorence2のモデルをロードします。ここでは、基本モデルのFlorence-2-baseを選択しました。

- 次に、ロードしたFlorence2モデルと対象画像をFlorence2Runノードに入力します。ここでは、taskにcaption_to_phrase_groundingを選択し、テキストに「human, hair,」を入力しました。caption_to_phrase_groundingは、入力したテキストに対応する画像領域を特定するタスクです。今回は、人物と髪を検出したいので、テキストに「human, hair,」を入力しています。

- 以下がFlorence2Runノードの実行結果です。Florence2Runノードのimage出力をPreview Imageノードで表示しています。人物全体と髪がバウンディングボックスで検出されていることが確認できます。

- Florence2Runノードのdata出力は、Florence2 Coordinatesノードに接続されます。dataはリストになっているため、ここでリストのどのデータを使用するかをindexで選択します。今回の場合、「human, hair,」と入力したので、index0がhuman、index1がhairになります。

SAM2によるセグメンテーション

- Florence2の結果を利用してセグメンテーションするためにSAM2を利用します。まず、(Down)Load SAM2ModelノードでSAM2のモデルをロードします。ここでは、modelにsam2_hiera_base_plus.safetensorsを選択しました。このモデルは、中程度のサイズと性能を持ち、精度と速度のバランスが取れているモデルです。今回は、画像1枚を処理するので、segmentorはsingle_imageになります。

- 次にSam2Segmentationノードでセグメンテーションを行います。入力には、ロードしたSAM2モデル、対象画像、Florence2の検出結果のバウンディングボックスを入力します。今回は、髪と人物を別々でセグメンテーションするので、individual_objectsをtrueに設定します。

- セグメントの結果は以下になります。左が人物全体、右が髪をセグメントでマスクした結果になります。

- 人物のマスクは、InvertMaskで反転させ、背景マスクを作成します。

背景の補完
画像から人物を削除し、背景のみの画像を生成します。

- SAM2で生成した人物マスクをGrowMaskノードで拡張させます。

- インペイントで使用するモデルをLoad Inpaint Modelノードでロードします。

- Inpaint(using Model)ノードに拡張したマスク、ロードしたインペイントモデル、対象画像を入力し、インペイントを実行します。

- 以下のようにインペイントが上手くいかない場合は、マスクの拡張範囲を広げたり、シード値を変えて生成を繰り返してください。

マスクの合成
髪マスクと背景マスクを合成し、人物以外をインペイントするためのマスクを作成します。

- MaskCompositeノードのdestinationに背景マスク、sourceに髪マスクを入力し、マスクを合成します。operation(合成方法)はaddにします。

- 必要に応じて、合成したマスクを拡張してください。

- ImageAndMaskPreviewノードに対象画像と合成したマスクを入力し、結果を確認します。しっかり人物以外がマスクされていることを確認できました。

髪の生成
指定した髪形に変更します。

- まず、Load CheckpointでRealVisXLをロードします。
- 次にLoad CheckpointのMODELとCLIP出力をLoad LoRAに接続します。Load LoRAでは、Midjourney Mimicをロードします。
- Load LoRAのCLIP出力は、2つのCLIP Text Encode (Prompt)ノードに接続します。上のCLIPがポジティブプロンプト、下のCLIPがネガティブプロンプトになります。
- ポジティブプロンプトには、髪形を入力します。今回は「afro」を入力しました。
- ネガティブプロンプトには、以下のプロンプトを入力しました。
worst quality, low quality, illustration, 3d, 2d, painting, cartoons, sketch, nsfw, accessories, human,
- 次にControlNetの設定です。まず、Load ControlNet ModelノードでAnyTest V4をロードします。
- Apply ControlNet(Advanced)にポジティブ/ネガティブプロンプト、ロードしたControlNetモデル、対象画像を入力し、ControlNetを適用します。strengthは弱めに設定してください。

- 次にインペイント用のLatentを作成します。VAE Encode (for inpainting)ノードに対象画像、Load CheckpointのVAE出力、背景マスクと髪マスクを合成したマスクを入力します。必要に応じて、grow_mask_byの値を調整し、マスクを拡張してください。

- KSamplerノードには、Load LoRAのMODEL出力、Apply ControlNet(Advanced)のpositive/negative出力、VAE Encode (for inpainting)のLATENT出力を入力し、髪の生成を行います。
- KSamplerノードの生成結果のLATENTは、VAE Decodeノードで画像に変換します。

人物と背景の合成と補正
新たに髪を生成した画像から人物を抽出し、背景と合成します。その後、合成した画像に弱いノイズでサンプリングを行い、画像を補正します。

- まず、新たに髪を生成した画像から人物を抽出するために、Florence2Run、Florence2 Coordinates、Sam2Segmentationノードで人物マスクを再作成します。Florence2Runノードには、新たに髪を生成した画像と「Florence2によるオブジェクト検出」でロードしたFlorence2モデルを入力します。Florence2Runノードのテキストには、「human,」を入力します。その他は、「Florence2によるオブジェクト検出」セクションで説明した内容と同じです。

- 次にImageCompositeMaskedノードで背景と人物を合成します。destinationには「背景の補完」で生成した背景画像を、sourceには新たに髪を生成した画像を、maskには再作成した人物マスクを入力します。
- 合成した画像は、VAE EncodeノードでLatentに変換します。

- 合成した画像の補正に使用するControlNetを新たに用意します。「髪の生成」セクションで使用したControlNetは、ポジティブプロンプトが「afro」のみであり、画像の特徴を捉えたポジティブプロンプトではないため、新たにポジティブプロンプトを作成し、補正の精度を上げます。
- WD14 Taggerノードで合成画像からタグを抽出します。それをCLIP Text Encode(Prompt)ノードに入力し、その出力をApply ControlNet (Advanced) ノードに入力します。
- CLIP Text Encode(Prompt)ノードのclip入力には、Load LoRAノードのCIP出力を入力します。
- Apply ControlNet (Advanced)ノードのnegative入力には、「髪の生成」セクションのネガティブプロンプトのCLIP Text Encode(Prompt)ノードの出力を入力します。control_netには、「髪の生成」セクションのLoad ControlNet Modelノードの出力を入力します。image入力には、合成画像を入力します。strengthの値は、少し強めの1.10を設定しました。画像のテイストを崩さないように補正するためです。

- 最後にKSamplerノードで補正を実行します。KSamplerノードのmodel入力には、「髪の生成」セクションのLoad LoRAノードの出力、positive/negative入力にはApply ControlNet (Advanced)ノードの出力、latent_imageには合成画像をLatentに変換したものを入力します。

7. ワークフローの実行
それでは、ワークフローを実行してみます。以下が髪形をアフロに変換した画像です。しっかりアフロに変換されています。色を指定していなかったので、この時は金髪になっています。

他の髪型にも変更してみました。以下が一覧になります。

いかがでしたでしょうか?ComfyUIを上手く使うと、このように実用的な画像の生成システムの構築が可能になります。みなさんも様々な画像生成に挑戦してみてください!
X(Twitter)@AICUai もフォローよろしくお願いいたします!
画像生成AI「ComfyUI」マスターPlan
画像生成AI「Stable Diffusion」特に「ComfyUI」を中心としたプロ向け映像制作・次世代の画像生成を学びたい方に向けたプランです。最新・実用的な記事を優先して、ゼロから学ぶ「ComfyUI」マガジンからまとめて購読できます。 メンバーシップ掲示板を使った質問も歓迎です。
- メンバー限定の会員証が発行されます
- 活動期間に応じたバッジを表示
- メンバー限定掲示板を閲覧できます
- メンバー特典記事を閲覧できます
- メンバー特典マガジンを閲覧できます
- 動画資料やworkflowといった資料への優先アクセスも予定
ゼロから学ぶ「ComfyUI」マガジン
https://note.com/aicu/m/md2f2e57c0f3c
マガジン単体の販売は1件あたり500円を予定しております。
2件以上読むのであればメンバーシップ参加のほうがお得です!というのもメンバーシップ参加者にはもれなく「AICU Creator Union」へのDiscordリンクをお伝えし、メンバーオンリー掲示板の利用が可能になります。
https://note.com/aicu/membership/boards/61ab0aa9374e/posts/db2f06cd3487?from=self
もちろん、初月は無料でお試しいただけます!
毎日新鮮で確かな情報が配信されるAICUメンバーシップ。
退会率はとても低く、みなさまにご満足いただいております。
✨️オトクなメンバーシップについての詳細はこちら
■ボーナストラック:今回のワークフローファイルと画像
この記事の続きはこちらから https://note.com/aicu/n/n2bc8d72e0eb4
Originally published at https://note.com on Oct 12, 2024.