こんにちわ!AICU media編集部です。
「AWS 生成 AI 実用化推進プログラム」に採択されました!
クリエイティブAIで「つくるひとをつくる」をビジョンに、「わかるAIを届ける」をコンセプトに活動しているAICU mediaは、高い技術力と、わかりやすい記事を通して今後もより一層力を入れて、AWS(Amazon Web Services)の企業での社内開発やプロフェッショナル向けの使いこなし事例を当事者目線でお届けしていきます。
あらためまして、こんにちわ、AICU media編集部です。
「ComfyUI マスターガイド」第30回目になります。
本記事では、AWS上にComfyUI環境を構築するテクニックを詳細に解説します。お値打ち記事ですが、ちょっと長いので3編に分けて、お送りします!
AWS編第2回はこちら、「コスト効果大なComfyUIのAWSデプロイ(Cost Effective AWS Deployment of ComfyUI)」を準備していきます。
「Cost Effective AWS Deployment of ComfyUI」
つまり「お財布に痛くない、AWSでのComfyUI運用」というオープンソース(MITライセンス)のプロジェクトです。AWS公式サンプルとして公開されています。
https://github.com/aws-samples/cost-effective-aws-deployment-of-comfyui/blob/main/README_ja.md
このサンプルリポジトリは、強力な AI画像生成ツールである ComfyUI を AWS 上にシームレスかつコスト効率の高い方法でデプロイ(インストールして利用)するソリューションを提供しています。このリポジトリは、AWSの主要サービスであるECS(Amazon Elastic Container Service)や、EC2(Amazon Elastic Compute Cloud)、その他の AWS サービスを活用した構成の設定を無償提供しています。しかも日本語の解説付きです。
このリポジトリの説明にもあるように、このソリューションの利用については AWS の費用が発生します。また設定次第では高額な費用になる可能性もあります。費用に関する詳細情報は、コスト セクションに記載されていますが、本記事では、まずAICU編集部での実用的な実験データで計測して共有していきたいと思います。
AICUコラボクリエイター・Yasさんによる動画での解説冒頭はこちら
動画での学びを求める方にはこちらがオススメです!
それでは準備作業からはじめましょう
(1) AWSのアカウントを作成
(2) クォータの引き上げ申請
(3) インストール環境をCode Editorで構築
(4) デプロイオプションの変更
(5) ComfyUI のデプロイ
(6) 利用開始!
(1)AWSアカウントの作成
AWSを使用するためには、AWSのアカウントが必要になります。AWS公式が公開している以下の記事を参考にアカウントを作成しておいてください。
https://aws.amazon.com/jp/register-flow
IAMによる開発者アカウントの作成
最初に作られるアカウントを「ルートユーザー」といいます。
このユーザーは、アカウントの新規作成や削除、支払いなど全ての根幹的権限を持っていますので、操作するのはできるだけ短期間で終わらせたいところです。またパスワード等の流出によるリスクが大きすぎます。
そこで、開発に頻繁に使うアカウントは分けておきたいと思います。
AWSではこのユーザー作成及び管理を「AWS Identity and Access Management」つまり、「IAM」と呼ぶサービスで管理します。
一番上の検索窓に「IAM」と打って、出てきたIAMの「主要な機能」から「ユーザー」を選びましょう。

左側の「アクセス管理」→「ユーザー」でも構いません。

ユーザ作成ボタンを押してください。
この先、何か間違った?というときも「削除」を押せば元通りです。

次はユーザー作成です。

ユーザーの詳細を指定
・ユーザ名: 「ComfyUI-server」とします
・[チェックON] AWS マネジメントコンソールへのユーザーアクセスを提供する
・ユーザーにコンソールアクセスを提供していますか?
→ユーザータイプ「IAMユーザーを作成」 でユーザーを指定する

「次へ」を押すと「許可の設定」に移動します。

ユーザーグループを設定します
ここでは「ComfyUI-users」というAdministratorAccess権限のみを持ったユーザーグループを作成します。

続いて、「ポリシーを直接アタッチする」を使って以下のポリシーをアタッチしてください。

- ServiceQuotasFullAccess
- AWSCloudFormationFullAccess
- AmazonEC2FullAccess
- IAMFullAccess
- AWSCloudTrail_FullAccess
- AmazonSageMakerFullAccess
- AWSLambda_FullAccess
- AWSAppSyncPushToCloudWatchLogs
※ここでは詳細な権限設定を考えるべきですが、設定の簡易のために、いったん「AdministratorAccess」と続く設定で必要となる権限のFullAccessのみを設定してすすめます。
次のステップ「パスワードの取得」で、ユーザーのAWS マネジメントコンソールにサインインするための手順とパスワードを取得できます。

「コンソールパスワード」の表示をして、ブラウザの別ユーザのウインドウでコンソールサインインURLにアクセスします。このURLの冒頭の12桁の数字がアカウントIDです。

あらかじめ設定されたパスワードでの初回ログインが終わると、パスワード変更を求められます。ここでのパスワード設定は、英数大文字、数字、記号など、高い難度でお願いします。
MFA(多要素認証)デバイスの設定もしておくことをおすすめします。
作成したアカウントでAWSダッシュボードに入れるようになったら次のステップです。
ここまでの作業を単純化したい場合は、次のステップでは、ルートユーザーでログインします(非推奨)。
(2)スポットインスタンスの上限解放
今回使うこのリポジトリでは、GPUのスポットインスタンス「All G and VT Spot Instance Requests」を使用しますが、このスポットインスタンスの上限のデフォルトは0であり、このままでは使用できません。さらに、この上限は自由に設定できるものではなく、AWSのサポートで変更してもらう必要があります。そのため、ここではスポットインスタンスの上限解放のリクエストを送る方法を説明します。
まず、AWSに作成したユーザー(もしくはルートユーザー)でログインし、トップページに当たる「コンソールのホーム」画面を表示します。
https://console.aws.amazon.com/console/home

次にリージョン(地域)を選択します。
右上のプルダウンで選ぶことができます。

ここでは「us-west2」(オレゴン)を選んでおきましょう。
新しい機械学習サービスなどが入りやすく、利用しやすい価格になっている事が多いためです。もちろん東京リージョンのほうが良い、など都合に合わせていただいて構いません。
次に左上の検索ボックスに「service quotas」と入力し、表示されたサービス一覧から「Service Quotas」を選択します。
こちらのURLでもアクセスできます。
https://us-west-2.console.aws.amazon.com/servicequotas/home/services


Service Quotasの画面が開くので、左サイドメニューから「AWSのサービス」を選択します。

AWSのサービス一覧画面が表示されるので、上部の検索バーに「ec2」と入力し、下部のサービス一覧から「Amazon Elastic Compute Cloud (Amazon EC2)」を選択します。

もしこのタイミングで以下のような画面になる場合は、必要な権限「ServiceQuotasFullAccess」が足りません(一つ前のステップを確認してきてください)。

EC2のスポットインスタンス一覧が表示されるので、一覧から「All G and VT Spot Instance Requests」にチェックを入れ、右上の「アカウントレベルでの引き上げをリクエスト」をクリックします。

表示されたダイアログボックスの左中央にある「クォータ値を引き上げる」の入力欄に「4」と入力し、下部の「リクエスト」ボタンをクリックします。

※ここでクォータ値が「4」以上になっている場合は、すでに同一アカウントでクォータの引き上げが実施されています。申請する必要はありません。
「リクエスト」すると画面上部に「Submitting Quota increase request for All G and VT Spot Instance Requests with requested Value of 4.」と表示され、リクエストの送信が行われます。

しばらくすると、AWSサポートより以下のような文面のメールが送信されてきます。おそらく人力で確認が実施されているようです。
ご担当者様
以下内容にて上限緩和申請を受領いたしました。
[US West (Oregon)]: EC2 Spot Instances / All G and VT Spot Instance Requests, 新しい上限数 = 8
現在、担当部署にて当上限緩和の申請内容について確認しております。
進歩があり次第ご連絡いたしますので、今しばらくお待ちいただきますようお願いいたします。
※確認作業のためお時間をいただく場合がございます、予めご了承くださいませ
Amazon Web Services
さらにしばらくすると、上限緩和リクエストが受理された内容のメールが届きます。これで上限緩和が完了になります。
ご担当者様
以下内容にて、ご依頼いただきました上限緩和リクエストの設定が完了いたしました。
反映されるまでに30分ほどかかる場合がございますことご了承くださいませ。
[US West (Oregon)]: EC2 Spot Instances / All G and VT Spot Instance Requests, 新しい上限数 = 8
何卒よろしくお願いいたします。
Amazon Web Services
(3) インストール環境をCode Editorで構築
クォータの申請が終わったらしばらく時間がありますので、ここで一休みしても良いのですが、せっかくなのでもうちょっとだけ進めていきましょう。
続いてのステップはインストール環境の構築です。
cost-effective-aws-deployment-of-comfyuiの環境構築方法には、ローカル環境で行う方法と、SageMakerで行う方法があります。ローカル環境を使ったインストールは、ユーザー個々の環境でブレが大きく「おま環」(=「お前の環境だけで起こっている」)になりがちです。
そのため最近の多くのAWSセットアップ手順では、SageMaker Studioでセットアップを行う手順が推奨されています。
せっかくなので今回も、SageMaker Studioを体験しつつ、SageMaker Studio上で環境構築していきましょう!
SageMaker Studioの起動
SageMakerには、テンプレートが用意されています。このテンプレートを利用することで、最初からdockerやコードエディターなどの環境がインストールされた状態でSageMaker Studioを立ち上げられます。以下のリンクよりテンプレート用のリポジトリにアクセスしてください。
https://github.com/aws-samples/sagemaker-studio-code-editor-template
リポジトリにアクセスし、下の方にスクロールすると、「Deploymet (1-click)」という項目があることが確認できます。ここから好きなリージョンの「Launch Stack」ボタンを押下することで、そのリージョンでSageMaker Studioを起動できます。今回は、us-west-2を起動します。


AWSにログイン済みの場合、以下のような画面が表示されます。

AWSダッシュボードにログインできるにも関わらず、以下のような画面が表示された場合は、CloudFormationに関する必要な権限が足りません。一つ前のステップを確認するか、ルートユーザーで「AWSCloudFormationFullAccess」の権限追加を行ってください。

さて、正しく権限がある場合は、ここで以下のパラメータ設定を行えます。

- AutoStopIdleTimeInMinutes: SageMaker Code Editorが自動で停止するまでの時間を設定します。デフォルトは120分で、起動してから120分後にCode Editorが停止します。今回は、120分あれば十分なので、120分に設定します。
- EbsSizeInGb: Code Editorで使用する容量を設定します。今回、Code EditorはIDEとしてデプロイを行うためだけに使用するため、デフォルトの容量「20GB」で問題ありません。
- InstanceType: Code Editorを起動するインスタンスを設定します。デフォルト設定は「ml.t3.medium」で、選択できるインスタンスの中で最も性能が低いものになりますが、インストールのみに使用するので、これで問題ありません。
- UseDefaultVpc: 各リージョンにデフォルトで用意されているVPCを利用するかどうかを決定します。デフォルト設定は「true」で、デフォルトのVPCを利用する設定になっています。デフォルトのVPCを使用したくない理由がなければ、デフォルト設定のままで問題ありません。
上記の設定後に、下部の「AWS CloudFormation によって IAM リソースがカスタム名で作成される場合があることを承認します。」にチェックを入れ、「スタックの作成」ボタンをクリックします。
そうすると、CloudFormationが実行され、SageMaker Studioの環境構築が行われます。

しばらくすると、ステータスが「CREATE_IN_PROGRESS」から「CREATE_COMPLETE」に変わり、SageMaker Studioの環境構築が完了します。

もしROLLBACK_FAILDEDというエラーになった場合は、「SageMakerStudio」に関する必要な権限が足りません。

この場合はいったんこのCodeEditorStackを「削除」して、ルートユーザー必要な権限を追加してきてください。
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/troubleshoot_roles.html
理解のために CodeEditorStack.template.yaml を使ってChatGPT等に訊いてみるのもよいでしょう。
このCloudFormationのデプロイに必要なARNを教えて
1. EC2関連の権限必要な権限:
ec2:CreateVpc, ec2:DescribeVpcs, ec2:CreateSubnet, ec2:DescribeSubnets
ec2:CreateInternetGateway, ec2:AttachInternetGateway
ec2:CreateRouteTable, ec2:CreateRoute, ec2:AssociateRouteTable
理由: VPCやサブネット、ルートテーブルを作成し、インターネットゲートウェイをアタッチするために必要です。
2. IAM関連の権限必要な権限:
iam:CreateRole, iam:AttachRolePolicy, iam:PutRolePolicy, iam:PassRole
理由: LambdaやSageMaker Studioの実行用ロール作成とポリシーのアタッチ、およびPassRole権限を必要とする可能性があります。
3. SageMaker関連の権限必要な権限:
sagemaker:CreateDomain, sagemaker:CreateUserProfile, sagemaker:CreateApp, sagemaker:DescribeDomain, sagemaker:DeleteDomain
理由: SageMaker Studioのセットアップに必要な権限です。ドメイン、ユーザープロファイル、アプリの作成・削除を行うために必要です。
4. CloudWatch Logs関連の権限必要な権限:
logs:CreateLogGroup, logs:CreateLogStream, logs:PutLogEvents
理由: Lambda関数の実行時にCloudWatch Logsへ出力するために必要です。
5. Lambda関連の権限必要な権限:
lambda:CreateFunction, lambda:InvokeFunction, lambda:DeleteFunction
理由: CloudFormationスタックでLambda関数を作成・実行・削除するために必要です。
6. CloudFormation関連の権限追加の権限として AWSCloudFormationFullAccess が必要ですが、他にも以下のような権限を確認してください:
cloudformation:DescribeStacks, cloudformation:ListStackResources
これらはスタックの管理に必要です。
7. Service Quotas関連の権限すでにServiceQuotasFullAccessが提案されていますが、サービスクォータの確認と調整が必要な場合はこれを付与します。
- AmazonEC2FullAccess
- IAMFullAccess
- AWSCloudTrail_FullAccess
- AmazonSageMakerFullAccess
- AWSLambda_FullAccess
- AWSAppSyncPushToCloudWatchLogs
以上のような権限があれば設定できるはずです。
※どうしてもうまく行かない場合はルートユーザーで実験しましょう。
さて、デプロイに成功している場合、ここで「出力」タブを選択すると、「SageMakerStudioUrl」が出力されていることが確認できます。この値にあるURLを選択します。

そうすると、SageMakerの画面が開きます。

「Skip Tour for now」して、左上に5-6個のアイコンが並んでいるところから、「Code Editor」を選択します。

Code Editorの起動画面に遷移します。既に起動中のCode Editorがあるので、このCode Editorの「Open」をクリックします。

SageMaker Code Editorの画面が開きます。これでSageMakerの準備ができました。

Microsoft の Visual Studio Code (vscode) そっくりですが、そもそも vscode もオープンソースです。こちらは「SageMaker Code Editor」というプロジェクトのようです。

(4) デプロイオプションの変更
今回はまずデプロイオプションの変更は行わずに、デフォルト状態でのデプロイを実験していきます。
今回の手順では企業等での利用を想定して、ユーザーIDとパスワードによるログインを必須としています。この状態で問題なければ次のステップに進んでいただいて構いません。
以下はセルフサインアップや自動シャットダウンなどの設定を行うデプロイオプションの変更点です。デプロイオプションは、主にcdk.jsonの内容を編集することで設定可能です。
セルフサインアップの有効化
Cognitoのセルフサインアップは、ログイン画面で新規アカウントをアクセスしたユーザーが作成することを可能とします。セルフサインアップの有効化は、cdk.jsonのコンテキストでselfSignUpEnabledをtrueに設定します。デフォルトはfalseですので「今回の手順でいますぐ使いたい!」という方はtrueにしておきましょう。
{
"context": {
"selfSignUpEnabled": true
}
}MFAの有効化
ユーザーの多段階認証 (MFA) を有効化します。MFAの有効化は、cdk.jsonのコンテキストでmfaRequiredをtrueに設定します(デフォルトはfalseです)。
{
"context": {
"mfaRequired": true
}
}サインアップ可能なメールアドレスのドメインを制限
allowedSignUpEmailDomainsコンテキストで、許可するドメインのリストを指定できます(デフォルトはnull)。文字列リストとして値を指定し、”@”シンボルは含めません。メールアドレスのドメインが許可ドメインのいずれかに一致する場合、ユーザーはサインアップ可能です。nullを指定すると制限なしで全ドメインが許可され、[]を指定すると全ドメインが禁止され、どのメールアドレスもサインアップできません。
設定されると、許可されていないドメインからのユーザーは「アカウント作成」でエラーが表示され、サインアップが阻止されます。この設定は既存のCognitoユーザーには影響しません。新規サインアップやユーザー作成のみに適用されます。
例:amazon.comドメインのメールアドレスでのみサインアップを許可する場合
{
"context": {
"allowedSignUpEmailDomains": ["amazon.com"]
}
}IPアドレス制限
IPアドレスでWebアプリケーションへのアクセスを制限するために、AWS WAFを使用してIP制限を有効にできます。cdk.json内のallowedIpV4AddressRangesに許可するIPv4 CIDR範囲の配列、allowedIpV6AddressRangesに許可するIPv6 CIDR範囲の配列を指定します。
{
"context": {
"allowedIpV4AddressRanges": ["192.168.0.0/24"],
"allowedIpV6AddressRanges": ["2001:0db8::/32"]
}
}SAML認証
Google WorkspaceやMicrosoft Entra ID(旧称Azure Active Directory)などのIdPによって提供されるSAML認証機能と統合することができます。
samlAuthEnabled: trueに設定すると、SAMLのみの認証画面に切り替わります。Cognitoユーザープールを使用した従来の認証機能は利用できなくなります。
"samlAuthEnabled": trueスポットインスタンス
重要でないワークロードでコストを削減するためにスポットインスタンスを使用できます(デフォルトはtrue)。コンテキストでuseSpotをfalseに設定して無効にすることも可能です。また、spotPriceを変更してスポット価格を指定できます。スポット価格がspotPrice以下である場合のみインスタンスが利用可能です。
{
"context": {
"useSpot": true,
"spotPrice": "0.752"
}
}自動またはスケジュールでのスケールダウン
コストをさらに削減するために、インスタンスをゼロにスケールダウンできます。
例:活動が1時間ない場合に自動でスケールダウンするには、autoScaleDownをtrueに設定します。
{
"context": {
"autoScaleDown": true
}
}これで自動でスケールダウンしてくれるようになります。
- スケジュール(例: 勤務時間)でスケールダウン/アップするには、scheduleAutoScalingをtrueに設定します。timezone、scheduleScaleUp、scheduleScaleDownでスケールアップ/ダウンのスケジュールを指定できます。
{
"context": {
"scheduleAutoScaling": true,
"timezone": "Asia/Tokyo",
"scheduleScaleUp": "0 9 * * 1-5",
"scheduleScaleDown": "0 18 * * *"
}
}NATインスタンスの使用
NATインスタンスは、NATゲートウェイと比較して安価ですが、利用可能性とネットワークスループットが制限されています。詳細はNATゲートウェイとNATインスタンスの比較を参照してください。
デフォルトでNATインスタンスが使用されます。cheapVpcをfalseに設定すると、NATゲートウェイに変更できます。
{
"context": {
"cheapVpc": false
}
}カスタムドメインの使用
カスタムドメインをサイトのURLとして使用できます。Route53のパブリックホストゾーンがすでに同じAWSアカウントで作成されている必要があります。パブリックホストゾーンの詳細については以下を参照してください:Working with Public Hosted Zones – Amazon Route 53
同じAWSアカウントにパブリックホストゾーンがない場合は、手動でのDNSレコードの追加やAWS ACMでのSSL証明書の検証中にメール認証を利用することも可能です。これらの方法を使用する場合、CDKドキュメントを参照し、適宜カスタマイズしてください:aws-cdk-lib.aws_certificatemanager module · AWS CDK
cdk.jsonで以下の値を設定します。
- hostName … サイトのホスト名。AレコードはCDKによって作成され、事前作成は不要
- domainName … 事前に作成されたパブリックホストゾーンのドメイン名
- hostedZoneId … 事前に作成されたパブリックホストゾーンのID
{
"context": {
"hostName": "comfyui",
"domainName": "example.com",
"hostedZoneId": "XXXXXXXXXXXXXXXXXXXX"
}
}以上が主要な設定です。
いまのタイミングでは見直す必要はありませんが、後ほど使用環境にあわせて変更してみてください。
(5) ComfyUI のデプロイ
ComfyUIのデプロイの実行
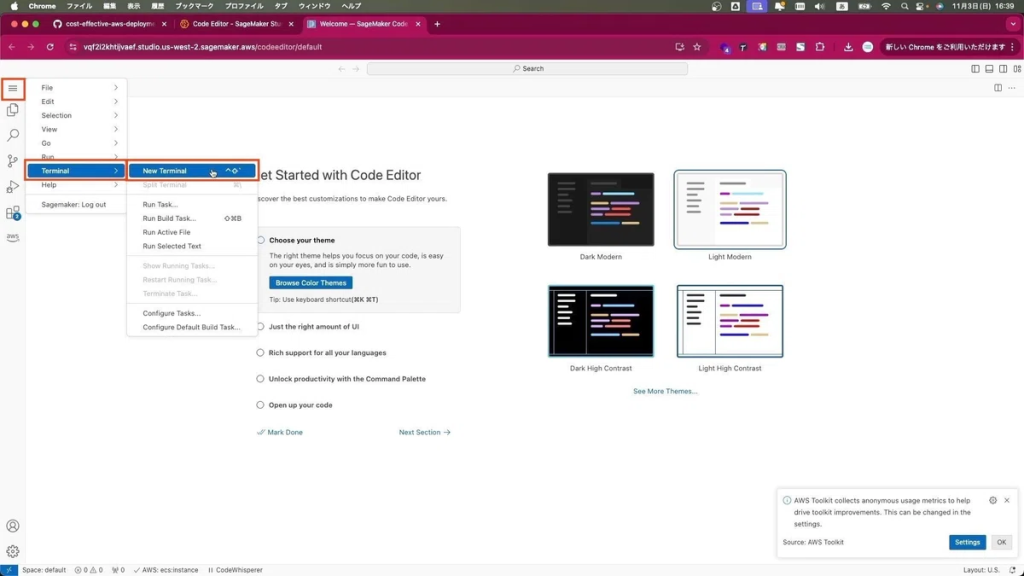
それでは、SageMaker Code Editorを使ってComfyUIのデプロイを実行します。Code Editorの左上にある3本線のアイコンをクリックし、Terminal->New Terminalの順に選択します。
この記事の続きはこちらから https://note.com/aicu/n/ne119480439e8
Originally published at https://note.com on Nov 6, 2024.