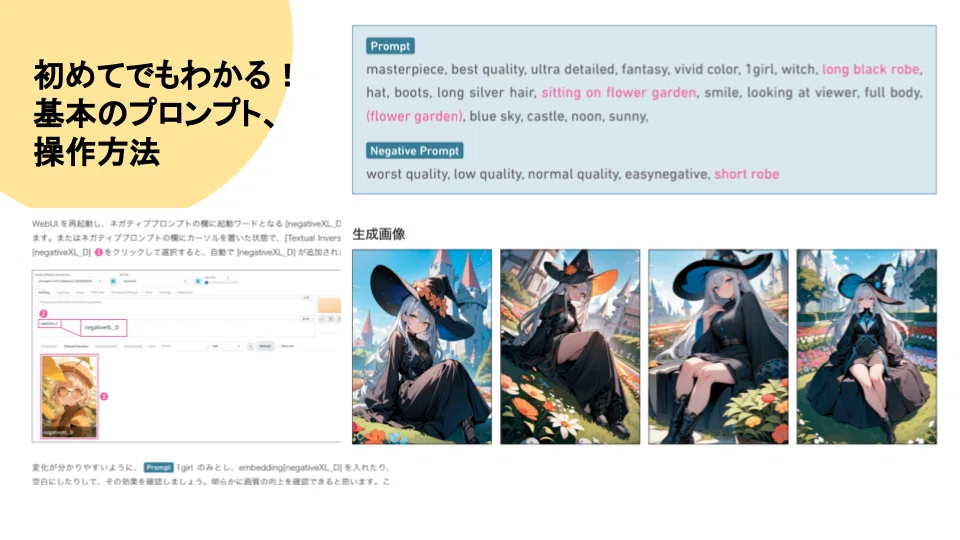
プロンプト「best quality , monochrome , lineart,1girl, bob cut, flat chest , short hair , school uniform, round_eyewear, hand on hip,looking at viewer,open mouth,white background」
ネガティブプロンプト「worst quality, low quality,blush, lowres, bad anatomy, bad hands」
プロンプト「masterpiece, best quality, face focus,1girl, lip, red lip, white skin」(ライティング指定なし) ネガティブプロンプト「worst quality, best quality, nomal quality, bad anatomy, bad hands」
プロンプト「masterpiece, best quality,cinematic lighting, professional lighting, face focus,1girl, lip, red lip, white skin」 ネガティブプロンプト「worst quality, best quality, nomal quality, bad anatomy, bad hands」
モデルや全体的な雰囲気の深み、重厚感や瑞々しさが全く違うことがわかるでしょうか。
またここに「intricate composition」(直訳すると『複雑な構図』)を追加すると、さらにリアルな質感を演出することができます。これは AICU media 編集部の知山が ChatGPT にプロンプトを考えてもらっている時に発見したプロンプトなので、他には出回っていないレア情報だと思われます。皆さんぜひ試してみてください!
プロンプト「masterpiece, best quality,cinematic lighting,professional lighting, intricate composition, face focus,1girl, dinner, pink lip, dinner,wine,smiling, black formal dress,long sleeves,sophisticated restaurant」 ネガティブプロンプト「worst quality, best quality, nomal quality, bad anatomy, bad hands」
飲料とドラマ
プロンプト「masterpiece, best quality, cinematic lighting, professional lighting, intricate composition, face focus,1girl, drinking beer, can, at home, night」 ネガティブプロンプト「worst quality, best quality, normal quality, bad anatomy, bad hands」
深みのある大人っぽい画像が生成できました!
深みのある大人っぽい画像が生成できました! 口元が気に入らないときは、image to image (img2img)でインペイントします。ついでにビールではなくジュースに置き換えてみます。
プロンプト「masterpiece, best quality, cinematic lighting, intricate composition, looking at viewer, 2girls, kissing cheek, whispering, index finger to index finger raised, looking at another, earrings, short blonde hair, eyewear, purple beret , summer muffler, green brown contact lens, catch light on the eyes, pink lips, indigo fingernails, <BREAK>looking at viewer, earrings, indigo short bob cut, round glasses, pink beret , blue brown contact lens, catch light on the eyes, pink lips, indigo fingernails」
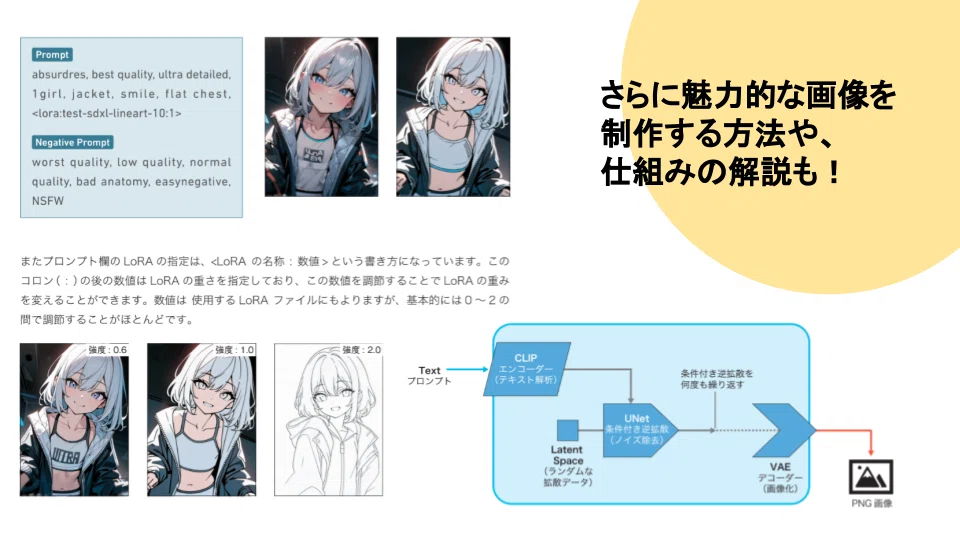
また「BREAK」という大文字の単語を挿入することで、それ以前のトークンというプロンプトのまとまりを打ち切ることができ、BREAK以降のプロンプトが反映されやすくなります。詳しくは2024年3月に発売開始している書籍「画像生成 AI Stable Diffusion スタートガイド」で学ぶことができます。レベルアップしたい方は要チェックです!
3月に書籍「画像生成AI Stable Diffusion スタートガイド」を出版したAICU media 編集部ですが、映像業界や広告クリエイティブ方面の読者の方から「漫画やイラストレーション以外の画像も作りたい!」というフィードバックをいただきました。
そこでこの記事では、AICUクリエイティブ・ディレクターの 知山ことね が中心に、前後編全2回にわたってこれまでのデジタルイラストレーションではなく、広告写真や映像業界、ミュージックビデオなどに使えるアーティスティックな写真、キービジュアルや背景を AI で生成し、文字やロゴを付け足してポスターや広告を制作する手法を画像生成 AI を触ったことがない方に向けて解説します。
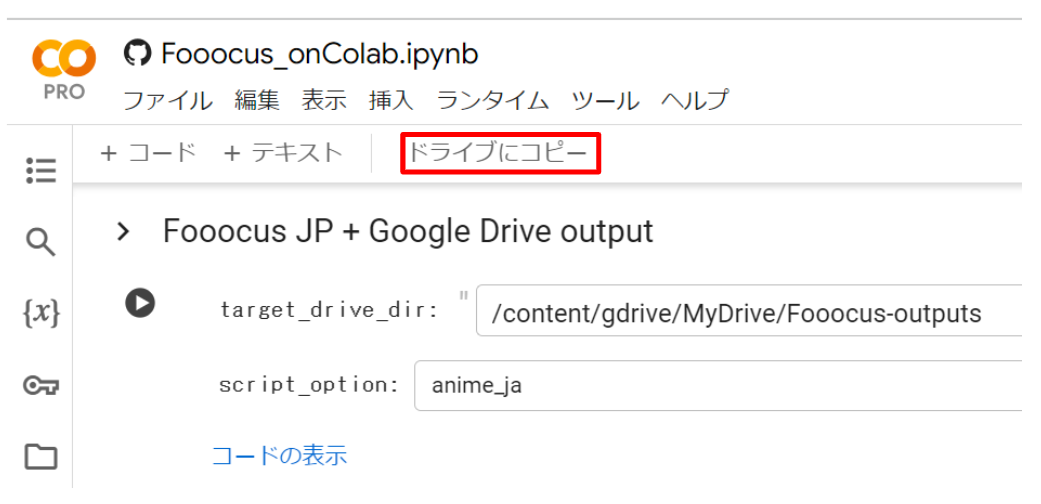
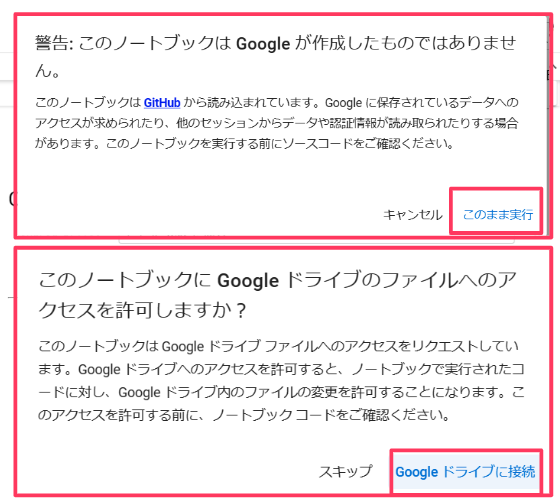
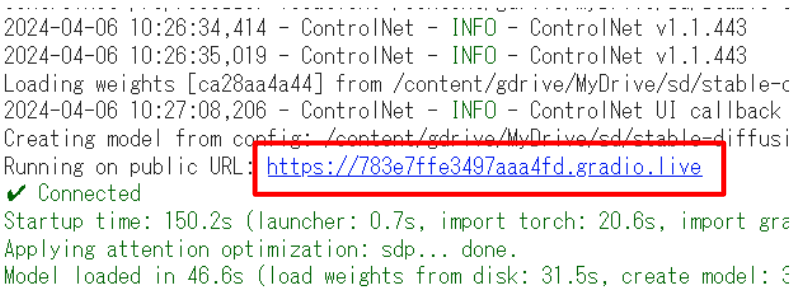
今回はAICUがオリジナルで提供するGPU 搭載 PC が無くてもできるプロセスを紹介していきますので、ぜひハンズオンで一緒に生成してみてください!
AUTOMATIC1111とは
AUTOMATIC1111(以下A1111) とは、Stability AI 社が開発している画像生成AI「Stable Diffusion」を Web ブラウザで操作するために開発された Web UI です。オープンソースで開発されており、GiHub で公開されているプログラムを実行することで誰でも無償で利用することができます。
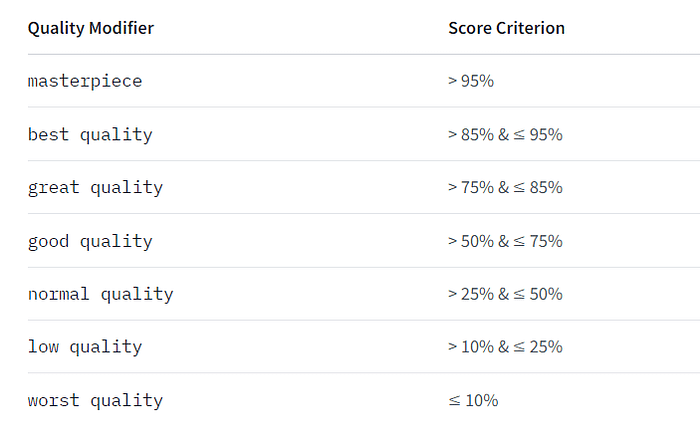
モデルの種類や好みにより様々な書き方があり、またこれと定まった書き方もありませんが、基本的にはプロンプトに「masterpiece, best quality, high quality, ultra detailed」など、ネガティブプロンプトに「worst quality, low quality, bad anatomy, bad hands」などを入力することが一般的です。
デジタルイラストレーション、テクニカルライター、チャットボット開発、Web メディア開発を担当するAICU Inc. 所属のクリエイター。AICU Inc. のAI 社員「koto」キャラクターデザインを担当している。小学校時代に自由帳に執筆していた手描きの雑誌「ザ・コトネ」「ことまがfriends」のLoRA が話題に。技術書典15「自分のLoRAを愛でる本」他。
We're excited to announce that Animagine-XL v3.1 is now live! This iteration is fine-tuned on top of v3.0 to improve its capabilities. In addition to gacha games charas, we also added popular anime and premium games charas to the dataset.
















































![[保存版] Animagine XL 3.1 生成比較レポート](https://ja.aicu.ai/wp-content/uploads/2024/07/image-29.png)