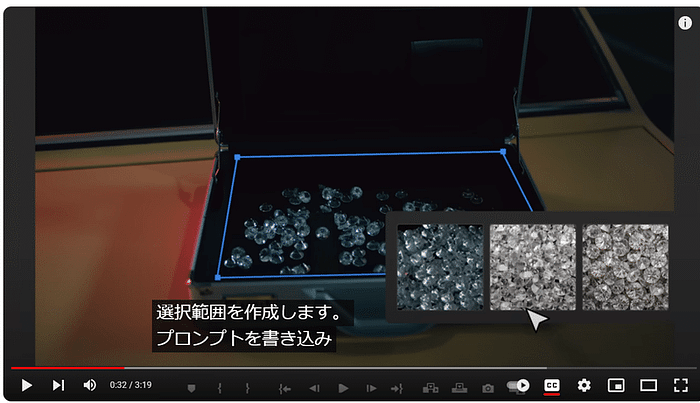
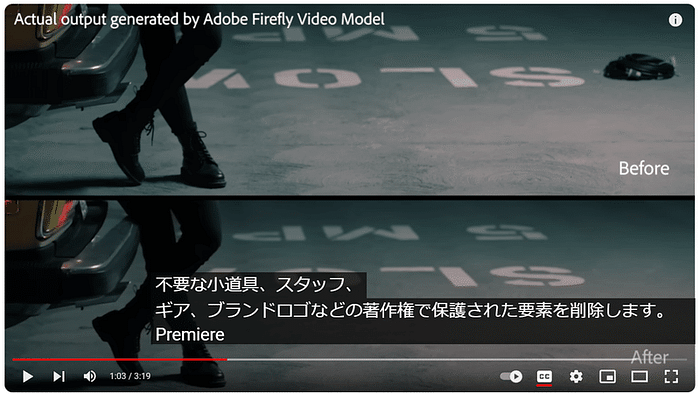
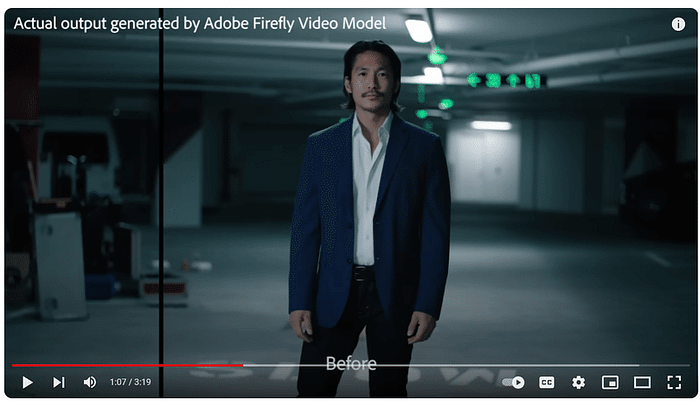
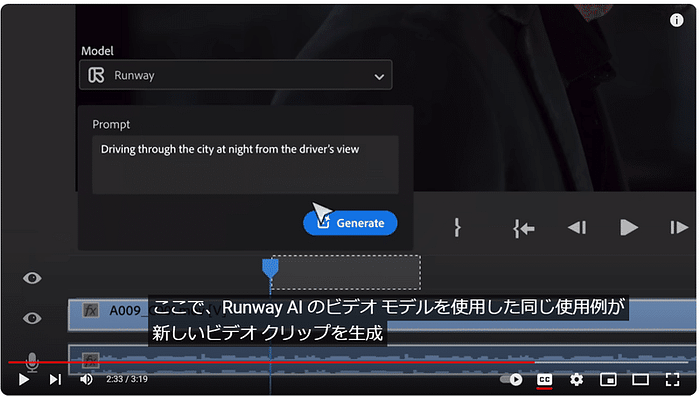
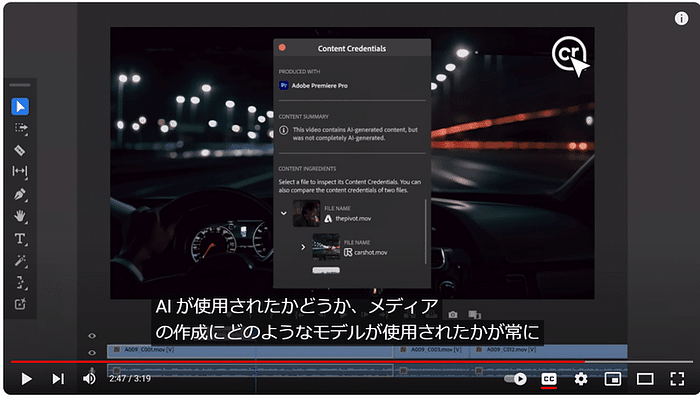
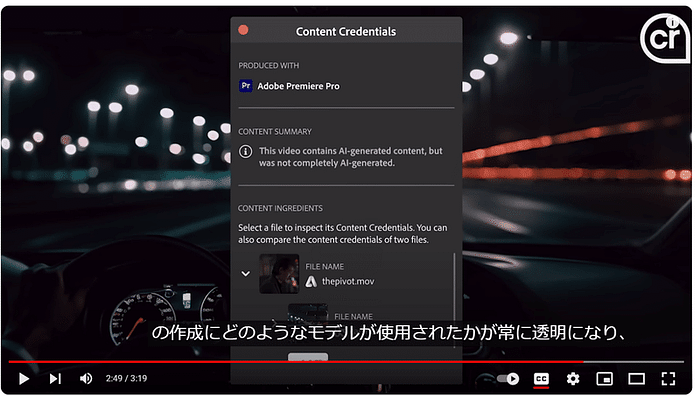
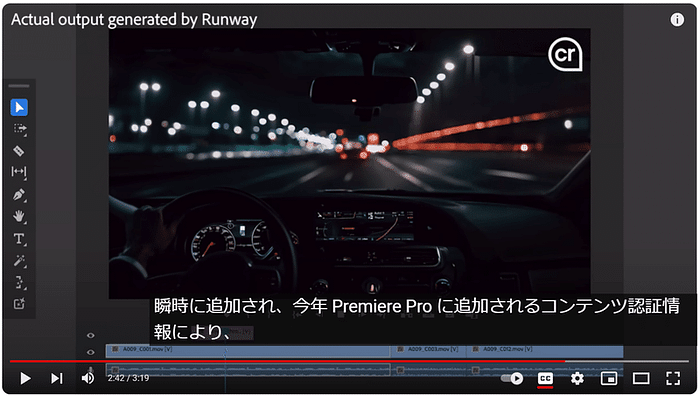
今回リリースされたGoogle公式ブログは「Gemma 2 is now available to researchers and developers」というタイトルで、クレメント・ファラベット(Google DeepMindリサーチ担当副社長)、トリス・ワーケンティン(Google DeepMindディレクター)によるものです。
記事中でGemini AI Studio でりようできるとありましたので早速、試してみました。 以下、AICU media編集部の操作による Gemini AI Studio で Gemma2による翻訳でお送りします。
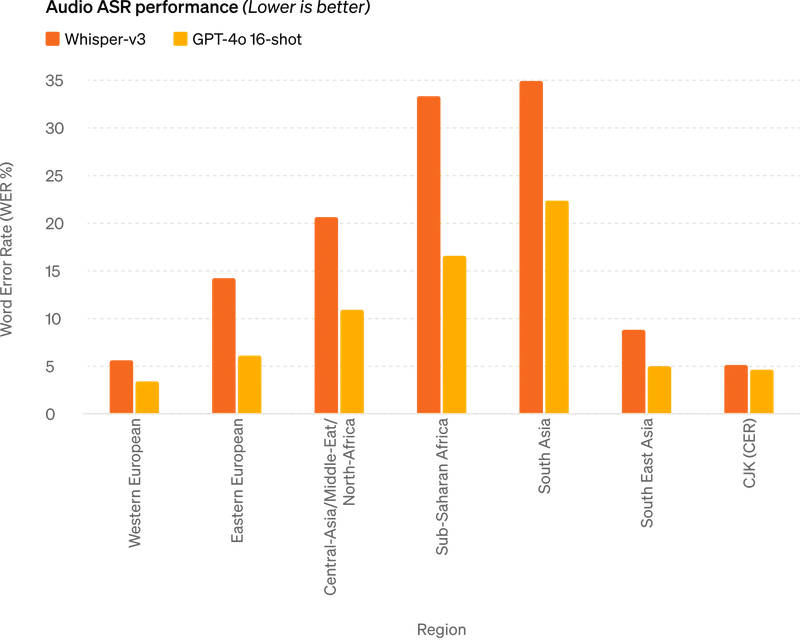
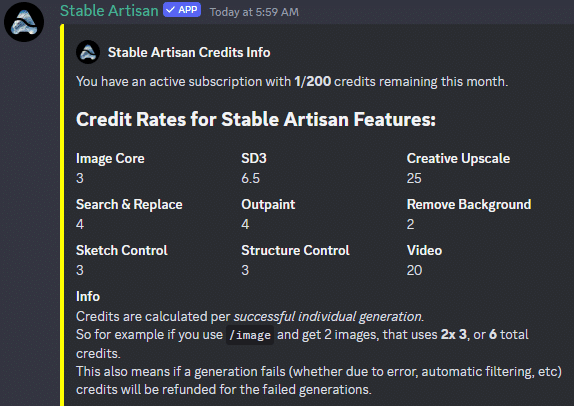
あらゆるハードウェアでの高速推論: Gemma 2は、高性能なゲーミングノートパソコンやハイエンドデスクトップからクラウドベースのセットアップまで、さまざまなハードウェアで驚異的な速度で動作するように最適化されています。Google AI Studioで完全精度でのGemma 2を体験したり、Gemma.cppを使用してCPUで量子化バージョンをアンロックしたり、Hugging Face Transformers経由でNVIDIA RTXまたはGeForce RTX搭載の家庭用コンピューターで試すことができます。
Jun 27, 2024 • #GoogleIO#GoogleIO2024 While many early large language models were predominantly trained on English language data, the field is rapidly evolving. Newer models are increasingly being trained on multilingual datasets, and there’s a growing focus on developing models specifically for the world’s languages. However, challenges remain in ensuring equitable representation and performance across diverse languages, particularly those with less available data and computational resources. Gemma, Google’s family of open models, is designed to address these challenges by enabling the development of projects in non-Germanic languages. Its tokenizer and large token vocabulary make it particularly well-suited for handling diverse languages. Watch how developers in India used Gemma to create Navarasa — a fine-tuned Gemma model for Indic languages. Subscribe to Google for Developers → https://goo.gle/developers
2024 年 6 月 27 日 #GoogleIO#GoogleIO2024 初期の大規模言語モデルの多くは主に英語のデータでトレーニングされていましたが、この分野は急速に進化しています。新しいモデルはますます多言語データセットでトレーニングされており、世界の言語に特化したモデルの開発に重点が置かれています。しかし、特に利用可能なデータや計算リソースが少ない言語では、多様な言語間で公平な表現とパフォーマンスを確保するという課題が残っています。 Google のオープン モデル ファミリーである Gemma は、非ゲルマン語のプロジェクトの開発を可能にすることで、これらの課題に対処するように設計されています。そのトークナイザーと大規模なトークン語彙により、多様な言語の処理に特に適しています。インドの開発者が Gemma を使用して Navarasa を作成した様子をご覧ください。これは、インド系言語向けに微調整された Gemma モデルです。 Google for Developers に登録する → https://goo.gle/developers
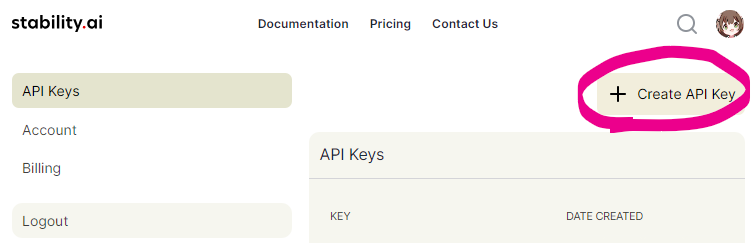
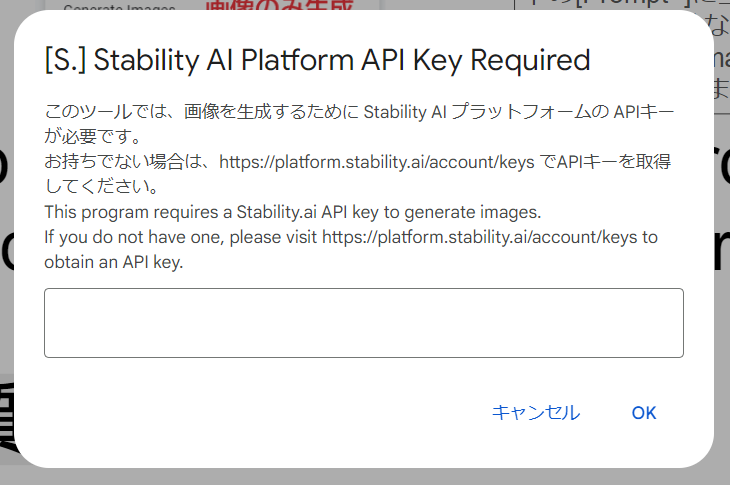
This program requires a Stability.ai API key to generate images. If you do not have one, please visit https://platform.stability.ai/account/keys to obtain an API key.
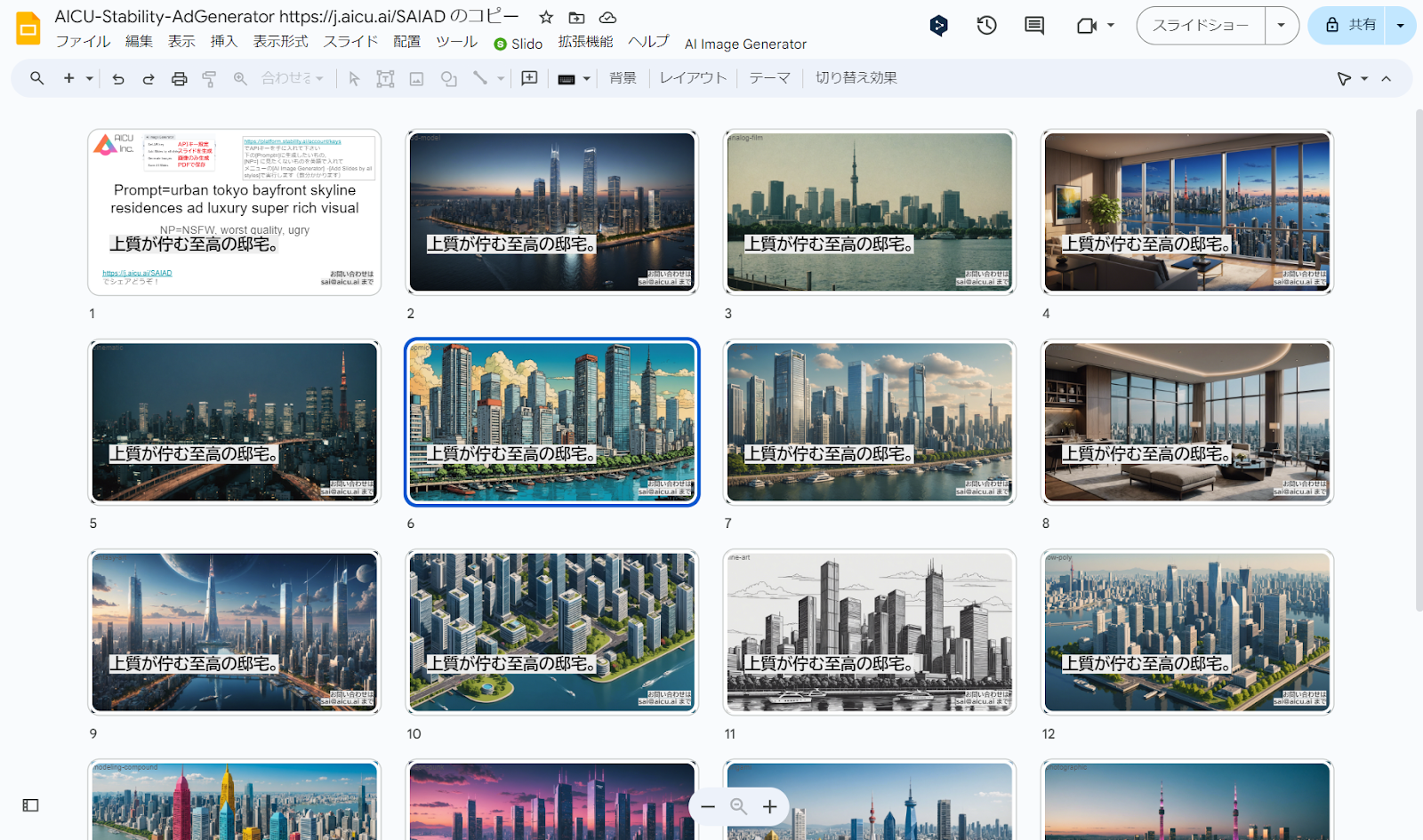
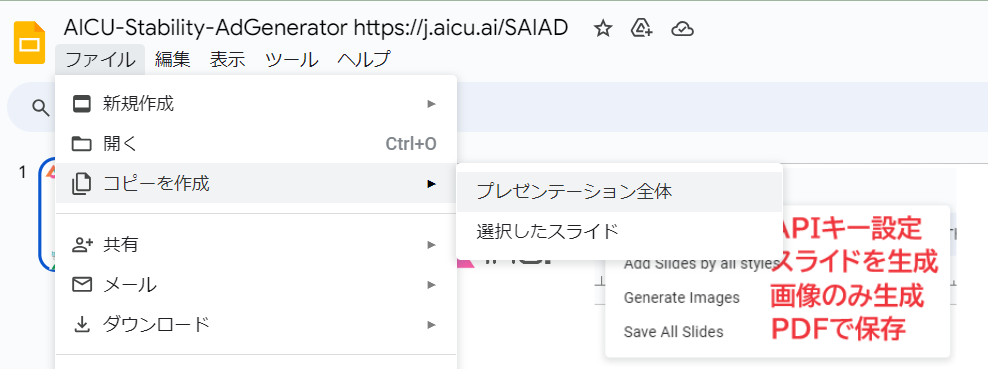
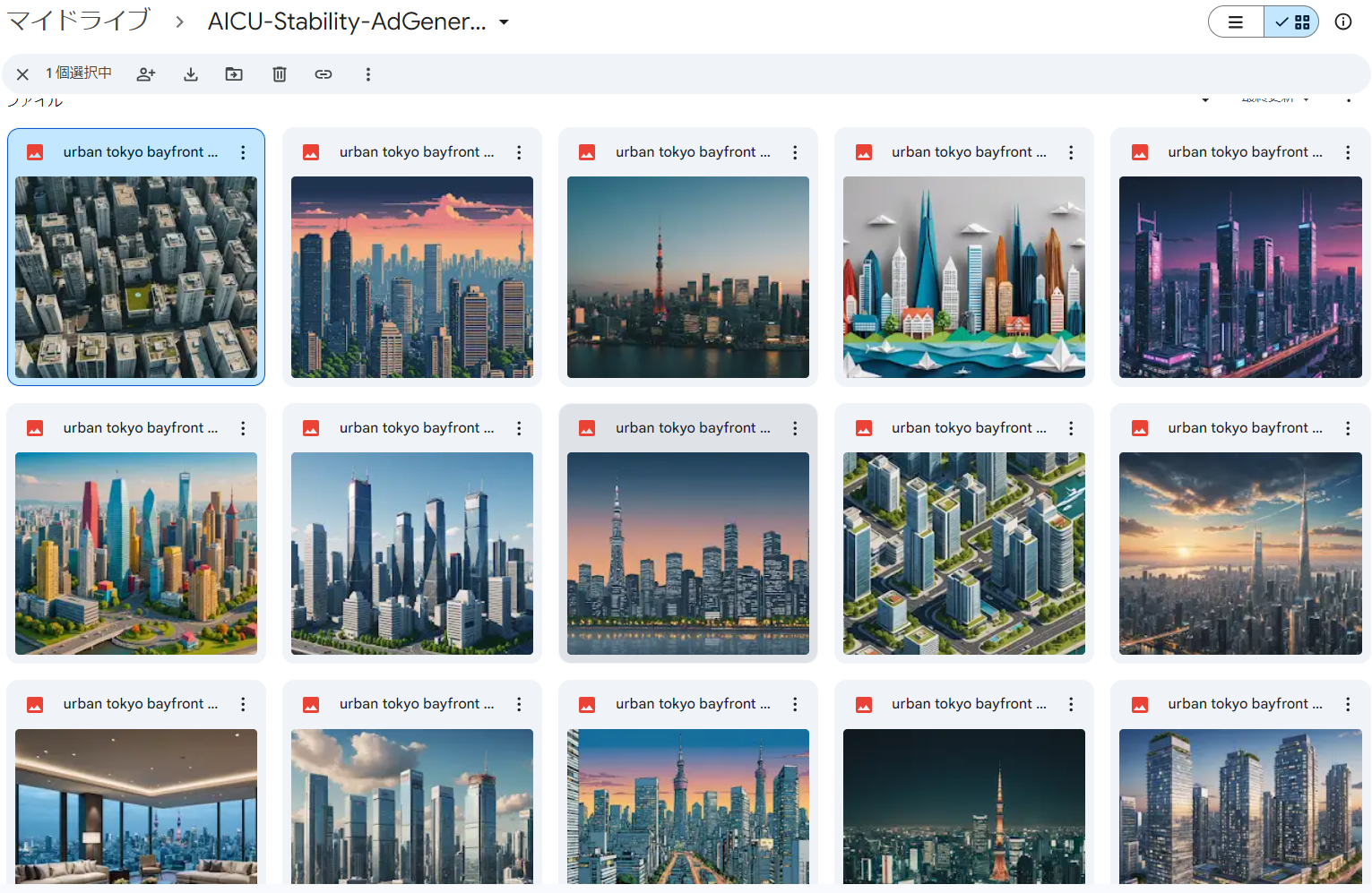
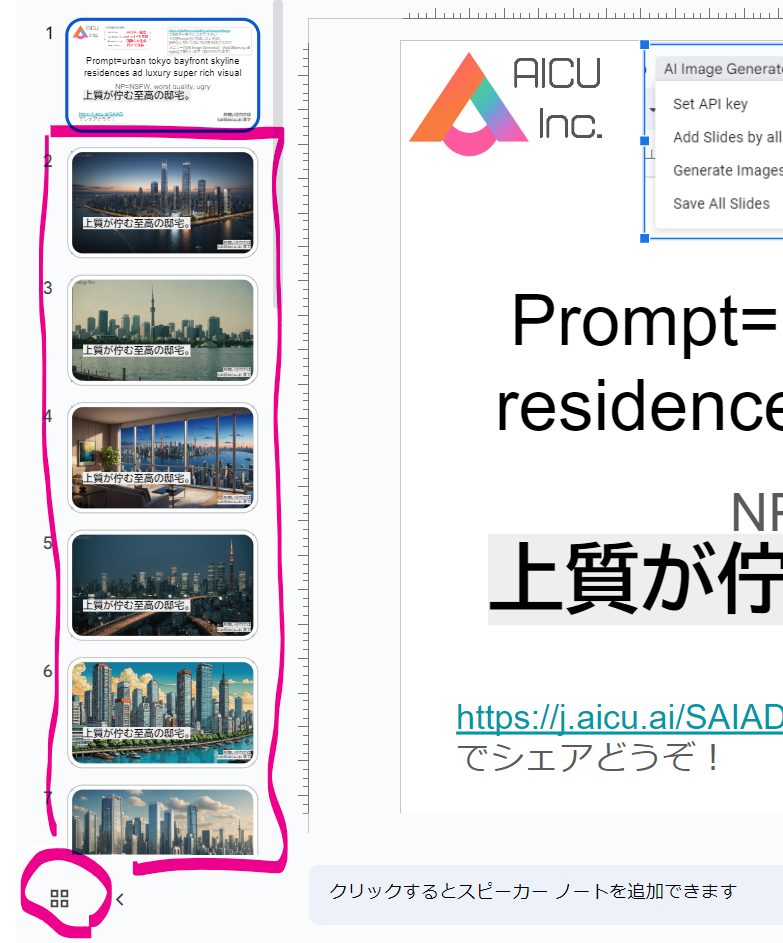
初期状態では「Prompt=urban tokyo bayfront skyline residences ad luxury super rich visual」(プロンプト=東京ベイフロントのスカイライン・レジデンス広告の豪華なスーパー・リッチ・ビジュアル)となっているので、このまま何度でも「Add Slides by all styles」を実行すれば15枚づつ、東京湾ベイエリアの高級そうな住居の画像が生成されます。第1ページにある「Prompt=」と「NP=」を変えるだけなので、例えばこんなプロンプトにしてみます
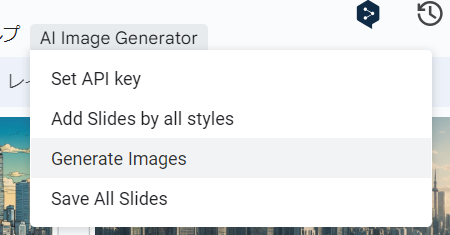
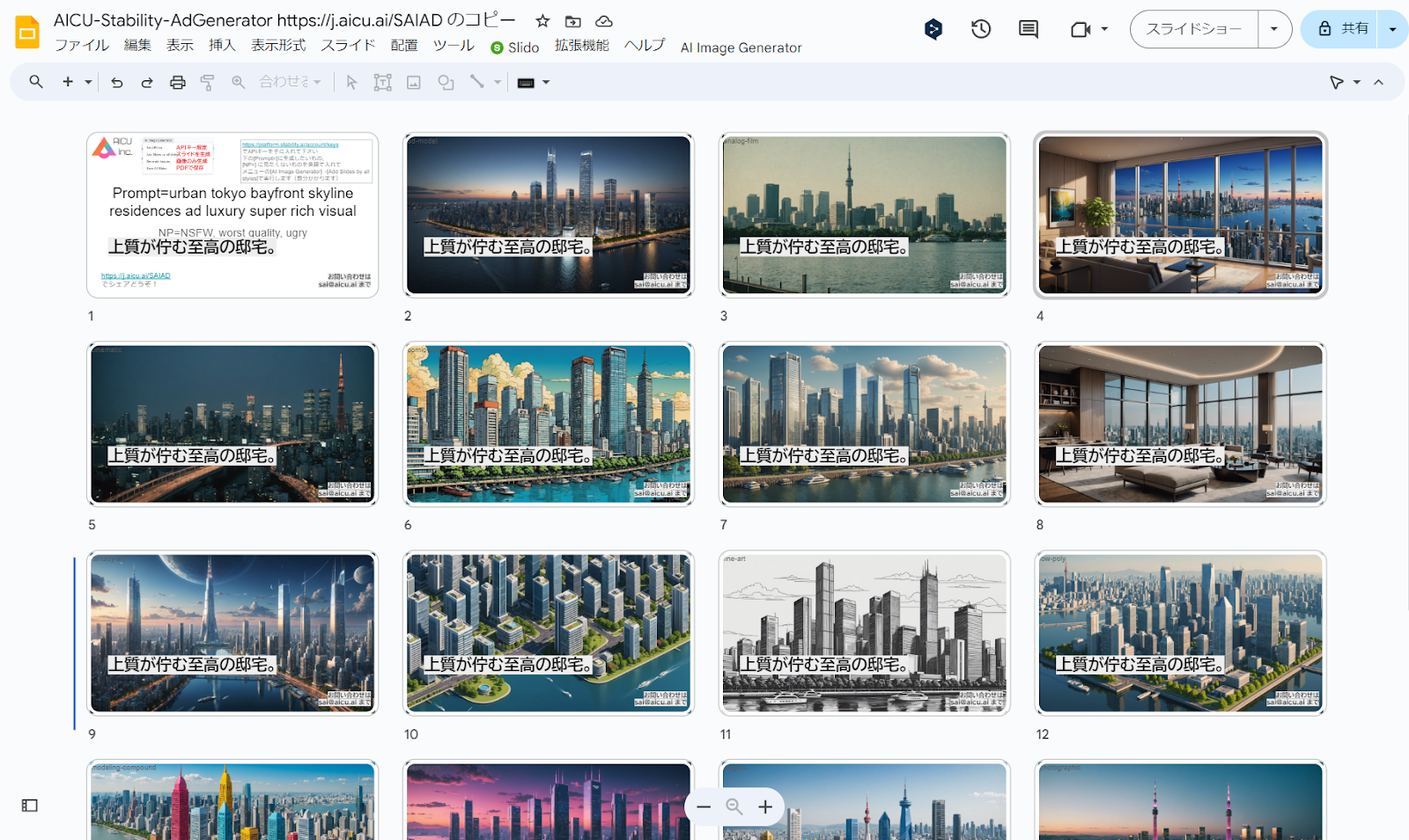
・Add Slides by all styles:タイトル(1枚目のスライド)で「Prompt=」で与えられたプロンプトと「NP=」で与えられたネガティブプロンプト(英語)から Stability AIの Stable Image Core API を使用して15種類のスタイル適用済み画像をGPU不要で画像を生成し、1枚生成されるごとに、スライドの画面全体に表示されるように背景画像として配置しています。追加された各スライドのタイトルとメモに 使用したstyleとプロンプトを設定しています。
・Generate Images:タイトル(1枚目のスライド)で与えられたプロンプトから、スライドのファイル名と同じ名前のディレクトリにすべてのスタイルの2,040 x 1,152pixelsの画像を15スタイル生成します。
・Save All Slides:PDF がDriveに保存されます。Google Slidesの[ファイル]⇢[ダウンロード]で保存でも構いません。
・15スタイルの生成は3分程度で51credit (80円ぐらい)です。
※安全のため、他人とシェアするときは Set API Keyを使って有効ではないAPIキーを設定しておくことをおすすめします。 ※本ツールのソースコードが気になる方は Google Slides上でスクリプトエディタをご参照ください。このコードの著作権はAICU Inc. が保有しています。この記事で公開されているツールの使用における損害等についてAICU Inc.は責任を負いません。 ※実際の広告等への利用など Stable Diffusionの商用利用に関するご質問は sai@aicu.ai までお問い合わせください。
技術解説「Slidesだけでも画像生成できる」
Google SlidesをコピーしてAPIキーを貼り付けるだけで様々なスタイルの画像を生成をすることができました!
AICU media では今後も話題の Stable Diffusion 3.0 やStable Image Core を用いた記事を発信していく予定です。面白かったらぜひフォロー、いいねをお願いします!
デジタルイラストレーション、テクニカルライター、チャットボット開発、Web メディア開発を担当するAICU Inc. 所属のクリエイター。AICU Inc. のAI 社員「koto」キャラクターデザインを担当している。小学校時代に自由帳に執筆していた手描きの雑誌「ザ・コトネ」「ことまがfriends」のLoRA が話題に。技術書典15「自分のLoRAを愛でる本」他。