日本時間2024年3月2日、人気のあるオープンソース画像生成WebUI「AUTOMATIC1111/Stable Diffusion WebUI」の最新版v1.8.0 がリリースされました。
- Update torch to version 2.1.2
- Support for SDXL-Inpaint Model (#14390)
- Automatic backwards version compatibility (when loading infotexts from old images with program version specified, will add compatibility settings)
- Implement zero terminal SNR noise schedule option (SEED BREAKING CHANGE, #14145, #14979)
- Add a [✨] button to run hires fix on selected image in the gallery (with help from #14598, #14626, #14728)
- Separate assets repository; serve fonts locally rather than from google’s servers
- Official LCM Sampler Support (#14583)
- Add support for DAT upscaler models (#14690, #15039)
- Extra Networks Tree View (#14588, #14900)
- Prompt comments support
以下、主要な機能の日本語訳です
torch をバージョン2.1.2に更新
ソフトインペイント (#14208) を追加
FP8のサポート (#14031, #14327)
SDXL-Inpaintモデルのサポート (#14390)
アップスケーリングと顔復元アーキテクチャにスパンドレルを使用 (#14425, #14467, #14473, #14474, #14477, #14476, #14484, #14500, #14501, #14504, #14524, #14809)
古いバージョンとの自動互換性 (プログラムバージョンを指定して古い画像からテキスト情報を読み込む場合、互換性設定を追加)
ゼロターミナルSNRノイズスケジュールオプションを実装 (SEED BREAKING CHANGE, #14145, #14979)
ギャラリーで選択された画像の hires.fix を実行する[✨]ボタンを追加 (#14598, #14626, #14728からのヘルプ)
アセットリポジトリを分離し、フォントをgoogleのサーバーからではなくローカルで提供するように。
公式LCMサンプラーのサポート (#14583)
DATアップスケーラーモデルのサポートを追加 (#14690, #15039)
ネットワークツリービューの追加(#14588, #14900)
NPUのサポート(#14801)
プロンプトコメントのサポート
Stability Matrixのほうはまだ対応できていないようです。
追記:自動アップデートで対応されました。
破壊的変更#14145 #14978 はともにリファイナーのスケジューラに関するものです。
1.7.0→1.8.0の全てのコミットログはこちらです
機能関係
微細な修正:
ExtentionsとAPI:
パフォーマンス
14507に対処するため、膨大な数のファイルを含むextra networksディレクトリのパフォーマンスを大幅に改善した (#14528)
余分なnetworkディレクトリの不要な再インデックス作成を削減 (#14512)
不要なisfile/exists呼び出しを回避 (#14527)
バグ修正:
その他:
現在、Issuesは1899件存在します。
全てのオープンソースの開発者に敬意を持って・・・応援したい。
まだまだ元気なAUTOMATIC1111プロジェクトです。
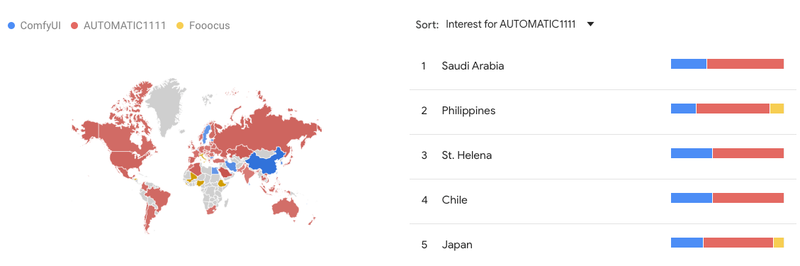
世界中でも多くの国で使われています。
これについてはまた別の機会にレポートします。
Originally published at https://note.com on March 2, 2024.