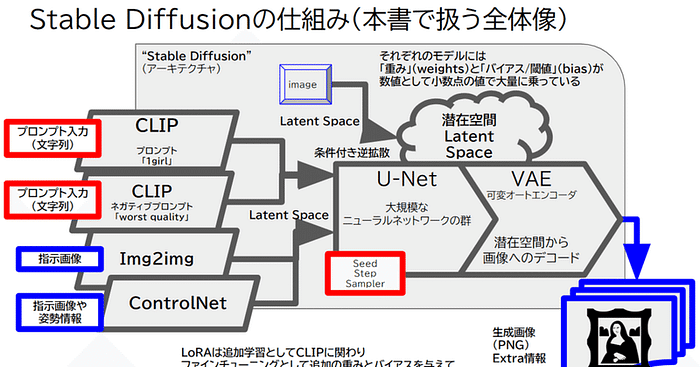
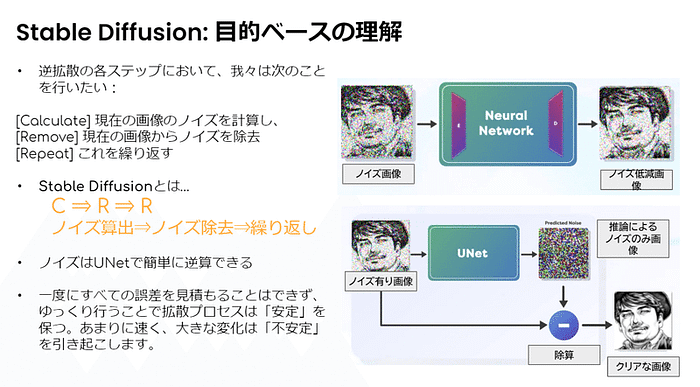
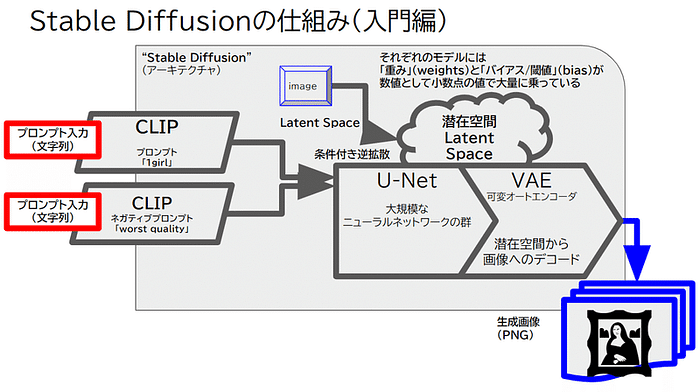
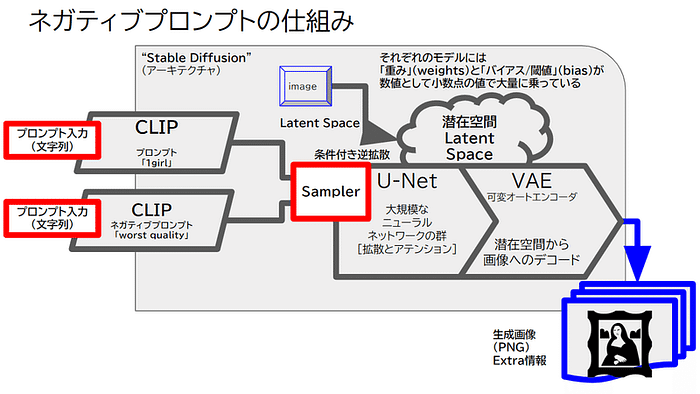
2024年7月18日、Create.XYZ のミートアップ第二弾が渋谷・Trunk(hotel)で開催されました。創業者のドゥルヴさん (@dhruvtruth) をはじめとする開発者首脳陣が直接、ランチボックスを囲みながら、ディープな質問や今後のストラテジーの共有をしました。

前回の記事で「CREATE.xyz」に興味を持った人もはじめてみたくなったと思います。
■プロンプトからサイトが作れる!?話題の「Create.xyz」を使ってみた!
■Text to AppなAI開発ツール「CREATE.xyz」首脳陣が渋谷でミートアップを開催 #CreateTokyo

会場の方からでてきたアイディアをその場でゲームに!
会場はランチボックスを囲みながら和やかな雰囲気で実施されました。
2名の英日翻訳者が参加し、Create.XYZの概要と、デモが始まりました。


ドゥルヴさんの提案で、会場からのゲームのアイディアをいただいて、そのアイディアをその場でゲームにするというデモが行われました。
実際にやってみた!「10をつくるゲーム」
AICU media編集部もその場で手を動かして見ます!
まず「Create.XYZ」にログインします。パスワードは不要です。
登録したメールアドレス宛にマジックリングが届きますのでそちらをクリックしてください。

新規プロジェクトを作ります。
右上の「New Project」ボタンを押します。
以後は📁の括りでプロジェクトが表示されます。

プロジェクト名に「New Game」と名前をつけました。

「New Page」で新規ページを作ります

白紙のページが作られたら右側の「Prompt」にプロンプトを打ちます。

会場のプロジェクターで見た感じはこんなプロンプトでした。

Make me a game where you have to make
10 using number 1 to 9
You can only use each number once
You can use any operation you want to add up to 10 (additions, subtraction, multiplication, division)
Make it look funky
Show a you win when the user gets it
日本語訳するとこんな感じです。
1から9までの数字を使って10を作るゲームを作ってください
各数字は一度しか使えません
10までの足し算に好きな演算を使うことができます
(足し算、引き算、掛け算、割り算)
ファンキーに見えるようにしてください
ユーザーがそれを得たら勝ちと表示します。
ちなみにプロンプトは日本語でも動作します。
プロンプトを設定したら下の「Generate」を押します。

左側のCREATEのアイコンの下に「Building…」という表示が出ます。
これはプロンプトから React(動的なWebサイトを記述する言語)のコードが生成されている状態で、暫く待ちましょう(数十秒~1分程度)。

「Up to date」と表示されたら、その右にある「Demo」を押すと……もう遊べます!

ゲームとしては、数字ボタンを1つ押して、その後に「+/-/x/÷」を押して、数字ボタンを1つ押して…最後に「Calculate」ボタンを押すと判定!という結果になることが多いです。
デザインやボタンの名前などは気に入らない場合はプロンプトを書き直したり、「Demo」→「Build」に切り替えてデザインを変更することもできます。上手くいかないときは「🔃」を押してリトライしましょう。コードの動作や見た目を変えたいときは「Generate」を押して再度やり直しましょう。Generateした場合は毎回生成されるものは異なります。

画面の要素をクリックすると、右下にその部品に該当するプロンプトが表示されます。

React用語でUIの部品はコンポーネントというのですが、「Convert to component」というボタンで部品化することができます(…が今回のデモでは触らなくていいです!)。

本当にあっという間です!

Google Maps や Stable Diffusionを使う
次のデモは本日の会場となった「Trunk Hotel」でのイベントWebサイトを作るというデモになりました。
先程と同じく新規プロジェクトを作り、与えたプロンプトは以下のようなものです。
make me an event page for the Trunk Hotel
It should have a map Google Maps
The address is Address: 5 Chome-31, Jingumae, Shibuya City, Tokyo 150-0001
Add sections:
• Testimonials
• Influencer cards
• Benefits of using Create
• A sign up form to register
トランクホテルのイベントページを作ってください地図があるべきです Google Maps 住所は住所です: 150-0001 東京都渋谷区神宮前5丁目31番地追加セクション:
– お客様の声
– インフルエンサーカード
– クリエイトを利用するメリット
– 登録フォーム
“Google Maps”のところがアドオン(Add-ons)です。
プロンプト窓右上の「Add-ons」か
/(スラッシュ)でGoogle Mapsアドオンを探します。

“Google”とタイプすると表示されます。他にも多様なアドオンがありますね。

紫色で「Google Maps」が表示されたら、そのアドオンに続いて住所の文字列をつなぎます。

これで「Generate」、本当にこれだけです!

タイトル、イベントの開催地へのGoogle Maps、

おすすめ情報(お客様の声/Testimonials)、インフルエンサー、

Createを使う利点、そして登録フォームです。

続いて、プロンプトを以下のように書き足しました。

Use this screenshot of the Trunk Hotel’s design as inspiration for how it should look. Don’t copy the content, just try to match the design whare it makes sense:
トランクホテルのデザインのスクリーンショットを参考にしてください。内容はコピーせず、意味のあるところだけデザインに合わせるようにしてください:
どこかお気に入りのサイトで、
Windows+Shift+Sでスクリーンショットを撮ってきてください!
実際のTrunk Hotelはこんな感じのおしゃれなWebサイトです。
https://catstreet.trunk-hotel.com

プロンプトに加えて…Ctrl+Vでスクリーンショットを貼り付けてみます。

貼り付けたら「Generate」します。

1回目の生成…


他にも「パックマンみたいなゲームを作って」とプロンプトに書けばそれらしいものを作ってくれるよ!というところで質疑応答になりました。
プロ用のサイトを作るには?
イベントサイトの例ではこのあと「Publish」ボタンを押すことで、サイトを公開できます。
例えば「demo-trunk-hotel-event-240718」として「Claim URL and continue」(URLを申請して続ける)を押してみます。


公開対象にするページが表示されるのでボタンをONにして、アクセスするルート(URLの下)この場合は「/」を確認して「Publish changes」を押します。

https://demo-trunk-hotel-event-240718.created.app
出来上がりです!

このURLは有料アカウントなら独自ドメインにすることができます。
https://www.create.xyz/pricing
月額19ドルのプロアカウントならエクスポート(外部出力)ができます。無料版でも20プロジェクトは作れます。

【Pro招待コードをいただきました!】
CREATETOKYO
こちらを使うと1ヶ月無料でProが使えるそうです。
View Code して Download Project
中央上部に「View Code」というボタンがあります。Generate中に押すと、実際のReactのコードが生成されているのを確認することができるボタンですが、この下に(プロアカウントだと)
・ Embed Project (プロジェクトの埋込)
・Download Project
・Copy code
という3つのボタンが表示されています。ここでは「Download Project」を押してみます。

createxyz-project.zipというファイルがダウンロードされるので、展開すると、以下のようなファイルが生成されています。

これは ReactJSのコード…ではなく Next.JSのプロジェクトのようです。ReactJSはMeta(旧Facebook)が2011年から社内用に開発していたライブラリを2013年に一般に公開したもので、Next.js はVercel が作った オープンソースの JavaScript のフレームワークで、React babel と Webpack をベースにし、React コンポーネントとサーバーサイドレンダリング (SSR) のために使えるソリューションを提供しています。Next.js は静的エクスポート、プレビューモード、プリレンダリング、より高速なコンパイル、自動ビルドサイズの最適化などの多くの開発者向けの効率化機能を備えています。
このプロジェクトで 12ファイル 11.9 KB (12,208 バイト) という小ささです。
AICU の GitHub に公開してみました!
https://cdn.iframe.ly/EFCH8ZT?v=1&app=1
Vercelでデプロイしてみました!
※ここから先はVercelです。
自分の管理ドメインで「Add New…」→「Project」

Import Git Repositoryで上記の(自分のドメインで管理している)リポジトリを選択します。

特に設定する環境変数はなさそうですのでそのまま「Deploy」します。

数十秒のビルドの後に、完成!

一発デプロイ…!?と見てみましたが、慌てすぎでした。
Google MapsのAPIが設定されていませんね!

Error: AuthFailure
A problem with your API key prevents the map from rendering correctly. Please make sure the value of the APIProvider.apiKey prop is correct. Check the error-message in the console for further details.
エラー AuthFailure
API キーに問題があるため、マップが正しくレンダリングされません。APIProvider.apiKey propの値が正しいことを確認してください。詳細については、コンソールのエラーメッセージを確認してください。
README.md をしっかり読んでみます。
このプロジェクトは[create.xyz](https://create.xyz/)から生成されました。
ReactとTailwindCSSで構築された[Next.js](https://nextjs.org/)プロジェクトです。
## はじめに
まず、開発用サーバーを起動します:
bash
npm run dev
# または
yarn dev
# または
pnpm dev
# または
bun dev
“`
http://localhost:3000](http://localhost:3000)をブラウザで開くと結果が表示されます。
src`にあるコードを編集することができます。あなたがファイルを編集すると、ページは自動的に更新されます。
もっと詳しく知りたい方は、以下のリソースをご覧ください:
– React Documentation](https://react.dev/) – Reactについて学びましょう。
– TailwindCSSドキュメント](https://tailwindcss.com/) – TailwindCSSについて。
– [Next.js Documentation](https://nextjs.org/docs) – Next.jsの機能とAPIについて。
– [Learn Next.js](https://nextjs.org/learn) – インタラクティブなNext.jsのチュートリアルです。
## 環境変数
Next.jsには、[環境変数](https://nextjs.org/docs/app/building-your-application/configuring/environment-variables)を読み込むためのビルトインサポートがあります。
.env.localからprocess.envに読み込むことができます。.env.local`ファイルをプロジェクトのルートフォルダに作成し、以下の環境変数を設定します。
“env
next_public_google_maps_api_key=my_api_key
“`
(READMEの日本語訳)
地図を表示するためのGoogle MapsのAPI設定がありません。
このあたりの設定はGoogle Maps APIのNextJSでの使い方解説を観ていただけるとよいのですが、この辺の設定も含めてあっという間にプロトタイピングが作れてしまうCreate.XYZはすごいです!
https://create-demo-trunk-hotel.vercel.app/
欲を言えば今回のサンプルのようにNextJSのサーバーサイドの処理がないのであれば、GitHub Actionsが選択肢にあると良いな!
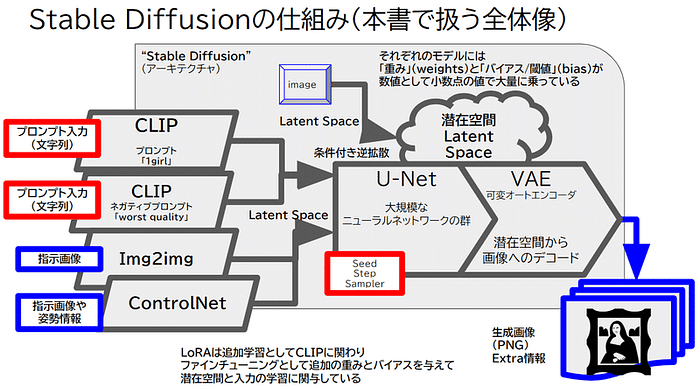
Stable Diffusionアドオンについて
Add-onsには「Stable Diffusion」があります。

以下のようなプロンプトで画像生成サイトを作ることができます。

Create an image generation website using Stable Diffusion V3 1girl, looking at viewer, animation
User can input Prompt, negative prompt
“Generate” button can send request to Stable diffusion.
https://demo-trunk-hotel-event-240718.created.app/sd

Create.XYZの Stable DiffusionはCREATE社のオウンホスティグでベースモデルはSDXLだそうです。Create.XYZのユーザは無料で利用できますが、生成はBuildモード・Demoモードのときは動的に生成されますが、パブリッシュ語は動作はしないようです(Integrationがない)。
でもデザインさえ決まれば 最新の Stable Diffusion Ultraを使ったサイトなども開発できるかもですね!
https://ja.aicu.ai/sd3api1800/

https://demo-trunk-hotel-event-240718.created.app/sd
今後の戦略について
質問(意訳):CREATEはB2B向けなのか、コンシューマ向けなのか?基盤モデルを持っている企業やビッグテックの企業とどういう棲み分けをしているのか。
ドゥルヴさん:顧客満足度、「ユーザの使用感」を第一に考えており、使用した結果、使いやすかったら口コミで広がっていくと考えているのでこれが一番の推進力になると考える。これが時期に大企業に浸透していくと考えている。
他にも機能を持っている会社は居るが「アプリを作るならここが一番、まちがいない」という位置づけ、状態を作ろうとしている。
先程の「基盤モデル」についての質問もあったが、基盤モデルをもつ企業は競合であり友達である。各モデルが良くなっていくと、我々のモデルも良くなる。最終的にはユーザが細かいことを考えなくても良くなるという方向を考えている。ビッグテックの会社に対するストラテジーとしては、全くコーディングをしたことがない新規の顧客に対しての市場を拡げている。顧客は「自分たちが思い描いたものを100%のもの」ではなく「使いやすいもの」を選ぶと考えている。ホストされた技術を使うと信じている。何よりも大事なのは「顧客に満足していただく」、それが口コミで拡がるということが大事だと考えています。
交流も!
ランチはパエリアでした!お弁当で食べる新鮮感覚。

AICU media編集長の しらいはかせ(@o_ob)がインタビューを実施しました。
しらいはかせ:CREATEはなんて読むの?クリエイト?
ドゥルヴさん: CREATEは現在多くのユーザが居るが、その半数以上は日本からのアクセスです。我々のサービス名は「CREATE」ですが、これは検索性もよいわけではないし、日本人のユーザさんたちは「Create.XYZ」と呼んでくれているので、我々も「クリエイト・イクスワイズィー」と呼んで良いのではないかと考えます。
しらいはかせ:これめっちゃ技術的な質問なんだけど、プロンプトが長くなったらどうすればいいの?
ドゥルヴさん:コンポーネント機能を使えばいい。プロンプトが長くなると制御性が下がってくる。コンポーネンツ機能は長くなった部品を分割して小さなパーツに分ける。UIコンポーネント、Functionsをロックして大きなページで扱うことができる。新しいコンポーネントの設計では名前はコンポーネントだが、いかなるエレメントもクリックできて、デザインタブでコンポーネントに変換できる。コードと高レベルのページを行き来して設計できる。
Stable Diffusionの本があるなら、Create.XYZの本もすぐ出るね!

Thanks Dhruv san, have a good stay in Japan!
https://note.com/o_ob/n/n2fc9c059a8d5
Originally published at https://note.com on July 18, 2024.


























![[速報]AICU CEO白井が「ChatGPTとStable Diffusion丸わかりナイト」に登壇いたしました](https://ja.aicu.ai/wp-content/uploads/2024/06/image-2-1.jpeg)