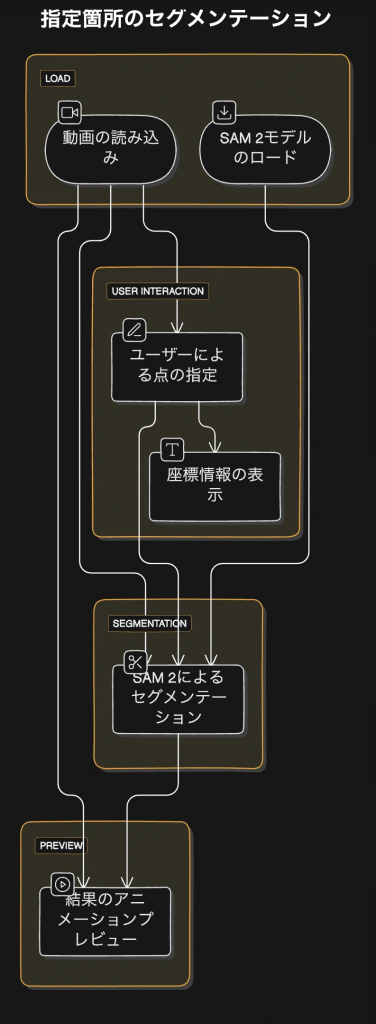
ダウンロードした動画をComfyUIにアップロードします。Load Video (Upload)の「choose video to upload」から動画をアップロードします。 Load Video (Upload)の初期設定では、frame_load_cap(*1)が16になっており、最初の16フレーム(*2)のみを読み込むようになっています。検証としては、それで問題ないですが、もし動画を全て読み込んで欲しい場合は、frame_load_capを0に設定してください。 また、初期設定では、select_every_nthが5になっていますが、これは1に変更してください。select_every_nthは、何フレームごとに1フレームを選択するかを指定するウィジェットです。1を設定することで、フレームをスキップせずに、全てのフレームが対象になります。
*1 読み込むフレーム数を指定するウィジェット。例えば、24fpsの動画で、frame_load_capに16を指定すると、16/24 ≒ 0.7秒となる。 *2 動画を構成する個々の静止画であり、1秒間に表示されるフレーム数(fps: frames per second)によって動きの滑らかさが決まります。
また公式情報として提供されているStability AI 公式のAPIガイド、そしてサンプルに散りばめられたプロンプトテクニックを読むことも重要なヒントになります。さらにコミュニティの開発者や探求者による情報も重要なヒントがあります。大事なポイントは、噂や推測でなく、自分で手を動かして、それを検証しなが「モデルと対話」していくことです。実用的で再現可能な実験手法です。ここでは、いくつかの実践的な例や実験手法を通して、最新のStable Diffusion 3時代の文法や表現力を引き出すコツをお伝えします。
Stability AI API で提供されている各種モデル(Ultra, Core, SD3Large等)は、上記のSD3Mと同じではなく、上位のSD3を使ってより使いやすくトレーニングされたモデルになっています。 前回のポイントを復習しながら、実際に手を動かしながら理解を深めてみたいと思います。同じプロンプト、同じシードを設定すると同様の結果画像が出力されますので、是非お手元で試してみてください。
過去、Stable Diffusion 1.x時代、Stable Diffusion XL (SDXL)時代に画像生成界隈で言及されてきたプロンプトの常識として「クオリティプロンプト」がありました。例えば、傑作(masterpiece)、高クオリティ(high quality, best quality)、非常に詳細(ultra detailed)、高解像度(8k)といった「定型句」を入れるとグッと画質が上がるというものです。これは内部で使われているCLIPやモデル全体の学習に使われた学習元による「集合知(collective knowledge/wisdom of crowds/collective knowledge)」なのですが、「それがなぜ画質を向上させるのか?」を説明することは難しい要素でもあります。 Stability AI APIでも上記のクオリティプロンプトは効果があり、意識して使ったほうが良いことは確かですが、過去と同じ使い方ではありません。 実験的に解説してみます。
ultra detailed, hires,8k, girl, witch, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, fantasy, vivid color, noon, sunny
上記のプロンプトをクオリティプロンプトとしての「ultra detailed, hires, 8k,」を変更して、同じシード(seed:39)を使って Stability AI Generate Ultraによる比較をしてみました。
▼(seed:39), Stability AI Generate Ultraによる比較
「girl, witch, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, fantasy, vivid color, noon, sunny」
▼「girl, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, vivid color, noon, sunny」(seed:39) Stability AI Generate Ultraによる生成
▼「girl, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, vivid color, noon, sunny」(seed:40) Stability AI Generate Ultraによる生成
What you wish to see in the output image. A strong, descriptive prompt that clearly defines elements, colors, and subjects will lead to better results. To control the weight of a given word use the format (word:weight), where word is the word you’d like to control the weight of and weight is a value between 0 and 1. For example: The sky was a crisp (blue:0.3) and (green:0.8) would convey a sky that was blue and green, but more green than blue.
▼(photoreal:0.5), girl, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, noon, sunny (seed:40)
▼(photoreal:0.5), girl, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, noon, sunny (seed:40)
▼(photoreal:0.1), girl, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, noon, sunny (seed:40)
上手くフォトリアル-アニメ度を制御できました。
逆に、1を超えて大きな値をいれるとどうなるでしょうか。
▼(photoreal:2), girl, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, noon, sunny (seed:40)
▼(photoreal:1) a 10 years old child looks (girl:0.5) (boy:0.5), black robe, hat, long silver hair, sitting, smile, looking at viewer, flower garden, blue sky, castle, noon, sunny (seed:40)
(photoreal:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands-on-own-cheeks:1), black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, noon, sunny (seed:39)
(photoreal:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands on own cheeks:1), black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, noon, sunny (seed:39)
さきほどのプロンプトから「looking at viewer, full body」を外して「(from side:1)」を入れてみます。
▼(photoreal:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands on own cheeks:1), black robe, hat, long silver hair, sitting, smile, (from side:1) ,flower garden, blue sky, castle, noon, sunny (seed:39)
▼(photoreal:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands on own cheeks:1), black robe, hat, long silver hair, sitting, smile, (from side:1), (face focus:1) ,flower garden, blue sky, castle, noon, sunny (seed:39)
いい感じに顔に注目が当たりました。さらに目線をがんばってみたい。
▼(photoreal:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands on own cheeks:1), black robe, hat, long silver hair, sitting, smile, (from side:1), (eyes focus:1) ,flower garden, blue sky, castle, noon, sunny (seed:39)
顔や目だけでなく、指にも気遣いたいのでバランスを取っていきます。
▼(photoreal:1) (from side:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands on own cheeks:1), black robe, hat, long silver hair, sitting, smile, (finger focus:0.5), (eyes focus:0.5) ,flower garden, blue sky, castle, noon, sunny (seed:39)
良いプロンプトができました。 念のため、シードも複数で試しておきますね。
▼(photoreal:1) (from side:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands on own cheeks:1), black robe, hat, long silver hair, sitting, smile, (finger focus:0.5), (eyes focus:0.5) ,flower garden, blue sky, castle, noon, sunny Seed:40
指もいいかんじですね
▼(photoreal:1) (from side:1), a10 years old child looks (girl:0.5) (boy:0.5), (hands on own cheeks:1), black robe, hat, long silver hair, sitting, smile, (finger focus:0.5), (eyes focus:0.5) ,flower garden, blue sky, castle, noon, sunny Seed:41
講座内容はAICU mediaで人気の日々お送りしている生成AIクリエイティブの情報、画像生成AIの歴史や文化、GPU不要・Macでも安心な環境構築、Google Slidesを使ったオリジナルツール、そして「超入門 Stability AI API」でもお送りしている「Stability AI API」を使って基礎の基礎から丁寧に学ぶ「基礎編」、さらに美麗なファッションデザインを自分で制作する「応用編」、広告業界やクリエイティブ業界にとって気になる「広告バリエーション」を生成AIだけで制作する「活用編」、そして画像生成AIにおける倫理など広範になる予定です。
主題:1girl, red one-piece dress, red shoes, braided hair, a bluebird
背景:a cottage, blue sky, meadow, forest, trees, rays of sunlight
その他:fantasy, calm atmosphere, daytime, sunny
ポイント③:「クオリティプロンプトを使用する」
これまで画像生成界隈で言及されてきたプロンプトの常識として「クオリティプロンプト」がありました。例えば、傑作(masterpiece)、高クオリティ(high quality, best quality)、非常に詳細(ultra detailed)、高解像度(8k)といった「定型句」を入れるとグッと画質が上がるというものです。Stability AI APIでもクオリティプロンプトは効果があります。
ultra detailed, hires, 8k, girl, witch, black robe, hat, long silver hair, sitting, smile, looking at viewer, full body, flower garden, blue sky, castle, fantasy, vivid color, noon, sunny
上記のプロンプトをクオリティプロンプトとしての「ultra detailed, hires, 8k,」を変更して、同じシード(seed:39)を使って Stability AI Generate Ultraによる比較をしてみました。
最後に Stability AI APIの Stable Image Ultra で生成したカバーアートの探求を共有します。
AICUのAIキャラクター「全力肯定彼氏くんLuC4」です
3D化して
実写化してみました
そのまま学位帽をかぶせて3Dアニメーション風に…
完成です!
best quality, photorealistic, graduation cap, mortarboard, 1boy, very cool high school boy, solo, gentle smile, gentle eyes, (streaked hair), red short hair with light highlight, hoodie, jeans, newest, colorful illuminating dust, in a mystical forest seed:39
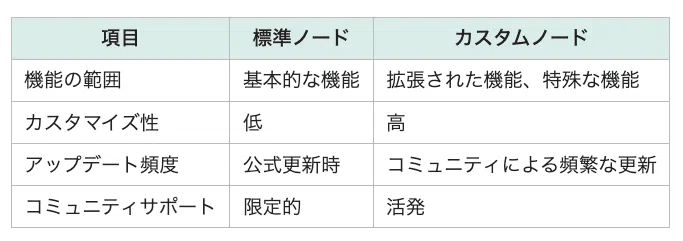
標準ノードは、ComfyUIにデフォルトで搭載されている基本的な機能を提供するノードです。例えば、画像を読み込む「Load Image」や、プロンプトを入力する「CLIP Text Encode (Prompt)」などが挙げられます。これらのノードは、ComfyUIの基本的な操作を行うために必要不可欠です。