デルタもんStampをベースにしたLoRAです。特徴的な日本語の描き文字が化けて可愛いですね。 This LoRA is based on Deltamon Stamp. It is cute with distinctive Japanese drawn characters that have been transformed.
ComfyUIで「思い通りの画像を生成したい!けど思うようにいかない…」という方、TextToImage(t2i)を使いこなせていますか? Stable Diffusionの内部の仕組みを理解し、ComfyUIでのText to Imageテクニックを身につけて、思い通りの画像を生成できるようになりましょう!
face focus, dog ears, 1boy, best quality, 16K, eating hair, dog nose, looking at looking at viewer, short hair, skinny, big eyes, dark skin, tall, naked overalls, 20-year-old,
beautiful, bold black outline, pink, pastel colors, Light Pink, scowl, brown hair, golden eyes, simple line drawing, animal ears, solo, brown hair, overalls, cat ears, dark skin, short hair, dark-skinned female, simple background, choker, sweater, yellow shirt, long sleeves, pink choker, white background, closed mouth, extra ears, animal ear fluff
「face focus, dog ears, 1boy, best quality, 16K, eating hair, dog nose, looking at looking at viewer, short hair, skinny, big eyes, dark skin, tall, naked overalls, 20-year-old, beautiful, bold black outline, pink, pastel colors, Light Pink, scowl, brown hair, golden eyes, simple line drawing, animal ears, solo, brown hair, overalls, cat ears, dark skin, short hair, dark-skinned female, simple background, choker, sweater, yellow shirt, long sleeves, pink choker, white background, closed mouth, extra ears, animal ear fluff」、ネガティブプロンプトは「text, watermark」(2トークン消費)で生成してみます。
前半「face focus, dog ears, 1boy, best quality, 16K, eating hair, dog nose, looking at looking at viewer, short hair, skinny, big eyes, dark skin, tall, naked overalls, 20-year-old」 Negative 「text, watermark」, SDXL, 1344×768, seed=13
CLIP1-Conditioning_to「face focus, dog ears, 1boy, best quality, 16K, eating hair, dog nose, looking at looking at viewer, short hair, skinny, big eyes, dark skin, tall, naked overalls, 20-year-old」 CLIP2-Conditiong_from「beautiful, bold black outline, pink, pastel colors, Light Pink, scowl, brown hair, golden eyes, simple line drawing, animal ears, solo, brown hair, overalls, cat ears, dark skin, short hair, dark-skinned female, simple background, choker, sweater, yellow shirt, long sleeves, pink choker, white background, closed mouth, extra ears, animal ear fluff」 Negative 「text, watermark」, SDXL, 1344×768, seed=13
CLIP1-Conditioning_to「beautiful, bold black outline, pink, pastel colors, Light Pink, scowl, brown hair, golden eyes, simple line drawing, animal ears, solo, brown hair, overalls, cat ears, dark skin, short hair, dark-skinned female, simple background, choker, sweater, yellow shirt, long sleeves, pink choker, white background, closed mouth, extra ears, animal ear fluff」 CLIP2-Conditiong_from「face focus, dog ears, 1boy, best quality, 16K, eating hair, dog nose, looking at looking at viewer, short hair, skinny, big eyes, dark skin, tall, naked overalls, 20-year-old」 Negative 「text, watermark」, SDXL, 1344×768, seed=13
続いてキャラクター2のプロンプトを設定します。もともと頂いたプロンプトからキャラクターとして一貫性がありそうな「1boy, dog ears, dog nose, short hair, skinny, big eyes, looking at viewer, dark skin, tall, naked overalls, 20-year-old, brown hair」(1boy、犬耳、犬鼻、短髪、痩せ型、大きな目、視聴者を見ている、黒い肌、背が高い、裸のオーバーオール、20歳、茶髪)として、先程のキャラクター1の代わりに入れてみます。
Conditioning_to「1boy, dog ears, dog nose, short hair, skinny, big eyes, looking at viewer, dark skin, tall, naked overalls, 20-year-old, brown hair」 Conditioning_from「beautiful, bold black outline, simple line drawing, simple background, white background, best quality, 16K」
入れ替えてみます。
Conditioning_to「beautiful, bold black outline, simple line drawing, simple background, white background, best quality, 16K」 Conditioning_from「1boy, dog ears, dog nose, short hair, skinny, big eyes, looking at viewer, dark skin, tall, naked overalls, 20-year-old, brown hair」
CLIPを2つでConcatだけで構成する場合にはこんな感じです。 [CLIP1] best quality, beautiful, 1girl and 1boy, [CLIP2] best quality, beautiful, 1girl and 1boy, ここまでいれる、というテクニックが非常に重要です。 こんな絵も作れるようになります。
[CLIP1] best quality, beautiful, 1girl and 1boy, 1girl, female, 20-year-old, cat ears, pink choker, sweater, yellow shirt, long sleeves, white background, closed mouth, extra ears, animal ear fluff, solo, brown hair, overalls, pink, pastel colors, Light Pink, face focus,
[CLIP2] best quality, beautiful, 1girl and 1boy, blue choker, eating hair, dog ears,16K, dog nose, looking at looking at viewer, short hair, skinny, big eyes, dark skin, tall, naked overalls, bold black outline, scowl, brown hair, golden eyes, simple line drawing, animal ears, simple background, dark skin, short hair, dark-skinned
CLIP0(conditioning_to) : 1boy and 1girl looking each other, beautiful, bold black outline, simple line drawing, simple background, white background, best quality, 16K
CLIP1(Conditiong_from) : 1boy and 1girl looking each other,1boy face focus, dog ears, 1boy, best quality, 16K,, dog nose, looking at looking at viewer, short hair, skinny, big eyes, dark skin, tall, naked overalls, 20-year-old
CLIP2(Conditioning_from) : 1boy and 1girl looking each other, 1girl , pink, pastel colors, Light Pink, scowl, golden eyes, animal ears, solo, overalls, cat ears, dark skin, short hair, dark-skinned female, choker, sweater, yellow shirt, long sleeves, pink choker, closed mouth, extra ears, animal ear fluff
これまで4回にわたってComfyUIでSD1.5およびSDXLを使ってプロンプトの基本的な方法から、応用的なテクニックまでを紹介してきました。今回はイラストレーションで「複数のキャラクターを同時制御する」という実験を行いましたが、プロンプトだけでなく、CLIPの内部やConditioningを使ってComfyUIならではの絵作りを探求していくベースになったようであれば幸いです。実はconditioningにはたくさんあり、今回紹介したCombine、Concatの他にはAverage、 Set Areaなど複数存在します。例えばAverageは結合ではなく線形補間します。
ComfyUIで「思い通りの画像を生成したい!けど思うようにいかない…」という方、TextToImage(t2i)を使いこなせていますか? Stable Diffusionの内部の仕組みを理解し、ComfyUIでのText to Imageテクニックを身につけて、思い通りの画像を生成できるようになりましょう!
extract this stable diffusion prompt longer to 75 tokens. “A beautiful garden with red roses and white lilies blooming under a clear blue sky” make more detail for each words.
A stunning, vibrant garden filled with deep red roses, their petals velvety and rich, alongside pristine white lilies, their petals delicate and gracefully open, all flourishing under a vast, clear blue sky with soft clouds gently drifting in the distance.
“A breathtaking, lush garden teeming with radiant, deep crimson roses, each petal exquisitely velvety and glowing under the sunlight. The roses stand tall and proud, surrounded by elegant, snow-white lilies with intricate, soft petals that curve gracefully outward. The lilies’ golden stamens catch the light, contrasting with their pure white petals. The garden is bathed in warm sunlight, the vibrant greenery of the foliage complementing the vivid flowers. Above, the expansive sky is a brilliant, azure blue, with delicate wisps of clouds painted across the horizon, creating a serene and peaceful atmosphere, where every bloom flourishes in perfect harmony with nature.”
SD1Tokenizer Token Details Token RangeMinimum token value: 0 (pad token when `pad_with_end` is False) Maximum token value: Size of the vocabulary – 1 Special TokensStart token: Typically 49406 End token: Typically 49407 Maximum Length`max_length`: 77 (default, can be set in the constructor) `max_tokens_per_section`: 75 (max_length – 2) Note: The actual vocabulary size and special token values may vary depending on the specific CLIP tokenizer used.
def token_weights(string, current_weight):
a = parse_parentheses(string)
out = []
for x in a:
weight = current_weight
if len(x) >= 2 and x[-1] == ')' and x[0] == '(':
x = x[1:-1]
xx = x.rfind(":")
weight *= 1.1
if xx > 0:
try:
weight = float(x[xx+1:])
x = x[:xx]
except:
pass
out += token_weights(x, weight)
else:
out += [(x, current_weight)]
return out
Today is the start of a new chapter! Super excited to announce the start of https://t.co/dmDZZ0xfeo w/ a super star lineup. It includes comfyanonymous(ComfyUI), mcmonkey4eva(SwarmUI), Dr lt Data(UI Manager), and a few star developers. Our goal is to take ComfyUI to the next level pic.twitter.com/4y1eNYZ5HH
POST リクエストでエンドポイント https://api.stability.ai/v2beta/3d/stable-fast-3d を呼び出してください。 Colabのサンプルコードより
#@title Stable Fast 3D#@markdown - Drag and drop image to file folder on left#@markdown - Right click it and choose Copy path#@markdown - Paste that path into image field below#@markdown <br><br>
image = "/content/cat_statue.jpg" #@param {type:"string"}
texture_resolution = "1024" #@param ['512', '1024', '2048'] {type:"string"}
foreground_ratio = 0.85 #@param {type:"number"}
host = "https://api.stability.ai/v2beta/3d/stable-fast-3d"
response = image_to_3d(
host,
image,
texture_resolution,
foreground_ratio
)
# Save the model
filename = f"model.glb"
with open(filename, "wb") as f:
f.write(response.content)
print(f"Saved 3D model {filename}")
# Display the result
output.no_vertical_scroll()
print("Original image:")
thumb = Image.open(image)
thumb.thumbnail((256, 256))
display(thumb)
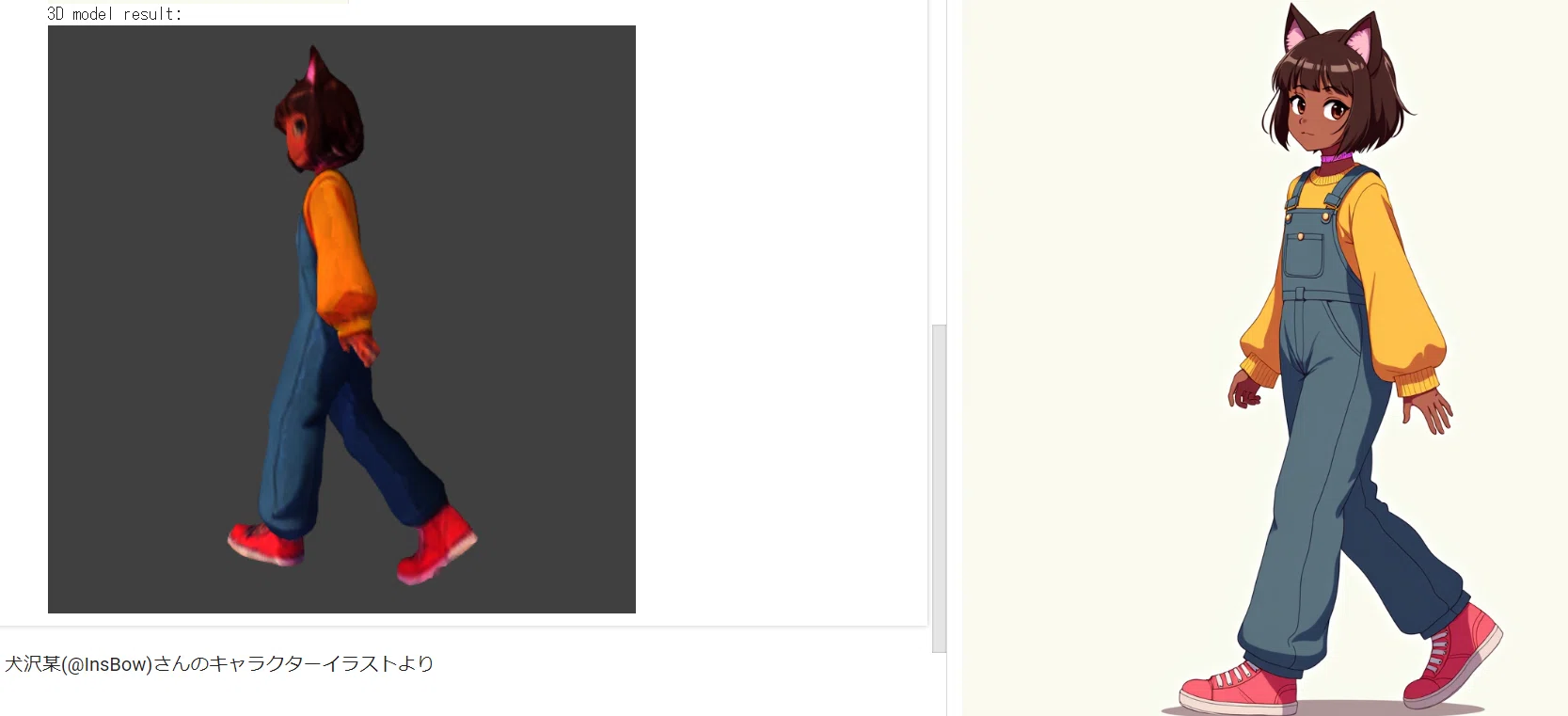
print("3D model result:")
display_glb(filename)
リクエストのヘッダーには、authorization フィールドに API キーを含める必要があります。リクエストの本文は multipart/form-data でなければなりません。
Stable Fast 3Dは、TripoSRを基にした重要なアーキテクチャの改善と強化された機能により、単一の画像からわずか0.5秒で高品質な3Dアセットを生成します。これはゲームやVRの開発者、リテール、建築、デザイン、およびその他のグラフィック集約型の分野の専門家に役立ちます。
Stable Video 4D
Stable Video 4Dは、単一の動画をアップロードすることで、8つの視点からダイナミックな新視点動画を受け取ることができるモデルです。単一のオブジェクト動画を複数の新視点動画に変換し、約40秒で8つの視点から5フレームの動画を生成します。カメラアングルを指定することで、特定のクリエイティブニーズに合わせて出力を調整できます。これにより、新たなレベルの柔軟性と創造性が提供されます。
SV3Dは、Stable Video Diffusionのパワーを活用し、斬新なビュー合成において優れた品質と一貫性を保証することで、3D技術における新たなベンチマークを設定します。このモデルには2つの異なるバリエーションがあります: SV3D_uは単一画像から軌道動画を生成し、SV3D_pは単一画像と軌道画像の両方からフル3D動画を生成するための強化された機能を提供します。