
2024年5月9日(日本時間)、Stability AIから新たな日本語大規模言語モデル「Japanese Stable LM 2 1.6B」がリリースされました。
モデルのサイズも小さく性能も高いLLMです。比較的シンプルな環境で動作しそうです。今回の記事は特殊な環境が不要なGoogle Colabで、最新のサンプルを、非常に短いコードで実験できることを確認したので紹介していきます。
まずは Stability AI 公式リリースから
https://ja.stability.ai/blog/japanese-stable-lm-2-16b
🎉日本語特化の言語モデル「Japanese Stable LM 2 1.6B」をリリースしました🎉
Japanese Stable LM 2 1.6B(JSLM2 1.6B)は16億パラメータで学習した日本語の小型言語モデルです。
こちらのモデルはStability AI メンバーシップにご加入いただくことで商用利用が可能です。
詳細はこちら💁♀️… pic.twitter.com/b35t2Il4lm
– Stability AI Japan (@StabilityAI_JP) May 9, 2024
- Japanese Stable LM 2 1.6B(JSLM2 1.6B)は16億パラメータで学習した日本語の小型言語モデルです。
- JSLM2 1.6Bのモデルサイズを16億パラメータという少量にすることによって、利用するために必要なハードウェアを小規模に抑えることが可能であり、より多くの開発者が生成AIのエコシステムに参加できるようにします。
- ベースモデルとしてJapanese Stable LM 2 Base 1.6Bと、指示応答学習(Instruction tuning)済みのJapanese Stable LM 2 Instruct 1.6Bを提供します。両モデルとも Stability AI メンバーシップ で商用利用が可能です。また、どちらのモデルもHugging Faceからダウンロードすることができます。
Stability AI Japanは16億パラメータで学習した日本語の言語モデルJapanese Stable LM 2 1.6B(JSLM2 1.6B)の ベースモデルと 指示応答学習済みモデルをリリースしました。ベースモデルの学習ではWikipediaやCulturaX等の言語データを利用、指示応答学習では jaster、 Ichikara-Instruction 、Ultra Orca Boros v1の日本語訳等、商用データおよび公開データを利用しました。今回のJSLM2 1.6Bでは言語モデリングにおける最新のアルゴリズムを活用し、適度なハードウェアリソースで迅速な実験を繰り返すことを可能にし、スピードと性能を両立しました。
性能評価
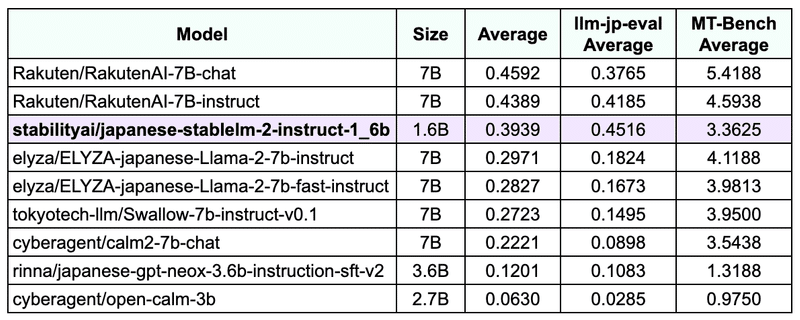
Nejumiリーダーボードを用いて、他の小規模パラメータのモデルと比較したJSLM2 1.6Bの性能は以下のとおりです。今回は llm-leaderboard(の社内Fork)のcommit c46e165 を用いています。
(サイズが)16億パラメータという小型モデルでありながら、40億パラメータ以下のモデルのスコアよりも高いスコアを達成し、70億パラメータのモデルに近いスコアを獲得しています。
高性能な小型言語モデルをリリースすることで、言語モデル開発の敷居を下げ、より高速に実験を反復することを可能にします。なお、少ないパラメータ数の小型モデルであるため、より規模の大きいモデルで発生しうるハルシネーションや間違いをおかす可能性があります。アプリケーションでのご利用の際には適切な対策を取るようご注意下さい。JSLM2 1.6Bのリリースを通じて、日本語LLMのさらなる開発と発展に貢献できると幸いです。
商用利用について
JSLM2 1.6Bは Stability AI メンバーシップで提供するモデルのひとつです。商用でご利用したい場合は、 Stability AIメンバーシップページから登録し、セルフホストしてください。
Stability AI の最新情報は 公式X、 Instagram をチェックしてください。
(以上、公式リリース情報終わり)
Google Colabで実際に使ってみる
それでは早速Google Colabで体験していきましょう。
基本は 公式のサンプルコードに従って、Google Driveで新規作成→Google Colab Notebookで構築していきます。
(完動品のコードへのリンクはこの記事の最後に紹介します)
Google ColabはGPUや搭載メモリサイズなどを気にしなくて良いので気軽に学習環境として試すことができます。
以下は公式のサンプルコードです。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "stabilityai/japanese-stablelm-2-instruct-1_6b"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# The next line may need to be modified depending on the environment
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto",
trust_remote_code=True,
)
prompt = [
{"role": "system", "content": "あなたは役立つアシスタントです。"},
{"role": "user", "content": "「情けは人のためならず」ということわざの意味を小学生でも分かるように教えてください。"},
]
inputs = tokenizer.apply_chat_template(
prompt,
add_generation_prompt=True,
return_tensors="pt",
).to(model.device)
# this is for reproducibility.
# feel free to change to get different result
seed = 23
torch.manual_seed(seed)
tokens = model.generate(
inputs,
max_new_tokens=128,
temperature=0.99,
top_p=0.95,
do_sample=True,
)
out = tokenizer.decode(tokens[0], skip_special_tokens=False)
print(out)
リポジトリへの利用申請
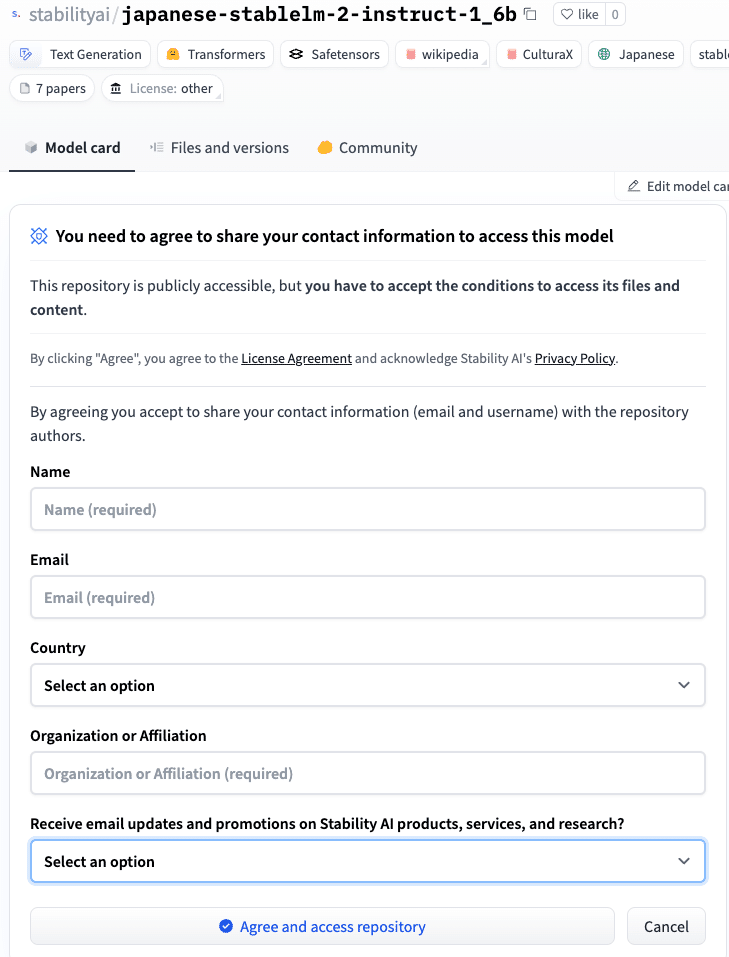
まずは下準備として、HuggingFaceでアカウント作成し、 モデルカード からStability AIリポジトリへの利用申請、以下の質問に答えましょう。
大事なポイントは最後のメールニュースの受信のためのメールアドレスを入れることですね。
✨️なお AICU は Stability AI 商用メンバーです✨️
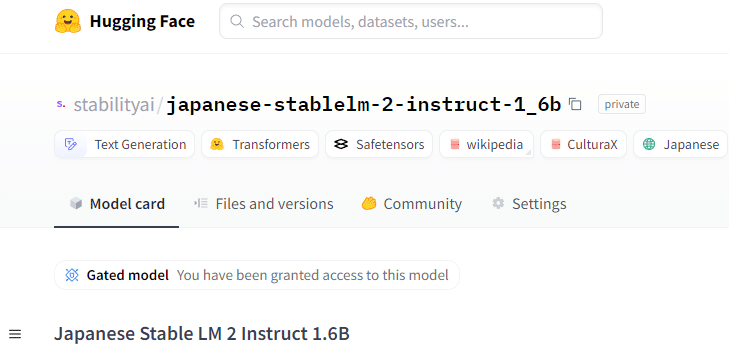
利用申請が承認されていると、上のフォームは表示されず、「Gated model」と表示されます。
Google Colabのシークレット機能
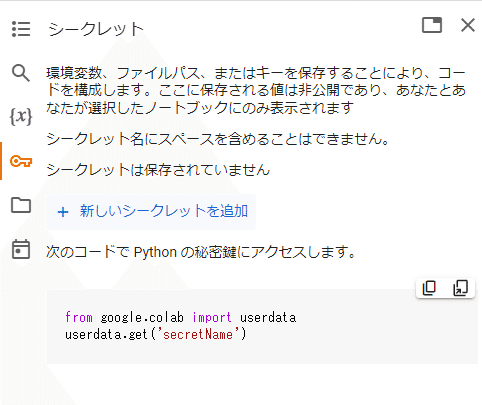
Google ColabとHuggingFaceに最近実装された機能なのですが、左側の「シークレット」から「HF_TOKEN」という環境変数を指定します。
環境変数、ファイルパス、またはキーを保存することにより、コードを構成することができます。ここに保存される値は非公開であり、ユーザ自身と選択したノートブックにのみ表示されます
「+新しいシークレットを追加」を押します
並行して、HuggingFaceの「Settings」>「Access Tokens」でトークンを作りましょう。
https://huggingface.co/settings/tokens

「Colab-HF_TOKEN」という名前をつけて、権限は「WRITE」をONにします(READだけでも動きますが、 HuggingFace推奨はWRITE)。
取得したユーザーアクセストークン(hf_で始まる文字列)を「HF_TOKEN」の「値」に貼り付けます。
「ノートブックからのアクセス」をONにします。
これで
token = userdata.get(‘HF_TOKEN’)
と書くだけで、HuggingFaceのトークンが参照できます。
もちろん、Pythonスクリプトに直書きしたいひとは
token=”(あなたのHugginFaceトークン)”
もしくは
!huggingface-cli login — token $token
でも動くと思います!
スクリプトを起動
コードはこちらです
吾輩は猫である、名前は…
Setting `pad_token_id` to `eos_token_id`:100257 for open-end generation.
吾輩は猫である、名前は…まだない。 そもそも「名前を付ける必要があるのか?」 それを考えるのに、10歳を目前にしている吾輩である。 しかし、他の猫達との差別化という意味では、あった方が良いとも思うし、なんせ名前があるという安心感から、猫は猫らしく、自由気ままにやりたい
Colabは動作環境を選べるのですが、CPUでの実行だとでだいたい1分以下で生成されます。
吾輩は猫である、名前は…名無しである。 名前はない。 何故なら、吾輩は名前を言いたくないのだ。 それを、そのことを知っている奴らが「名無し」と呼ぶのである。 そいつらを、「名付き」の奴らと呼ぼう。 吾輩が名無しと呼ばれるのは「何も持っていないから」である。 何も持っていないから、それ
吾輩は猫である、名前は… といえるほど、名前が思い浮かばないのは、私だけでしょうか? そうは言っても、「猫じゃらし」は、その場によって名前のバリエーションがたくさんありますよね。 そういう「猫じゃらし」が持つ、イメージとか、意外な性格とか、飼い猫のネコじゃらしの場合を
吾輩は猫である、名前は…まだないのである。 ここは、吾輩が住み慣れた部屋、何も特徴のないところだ。 場所は不確かだが、とにかく部屋だけはここになって、ずっとこの部屋で暮らしているのだ。 なんでこんなことを言っているかというと、吾輩の部屋が消えて、別…

続いてT4 GPUで実行してみました。
4–5秒で以下のテキストが生成されました。
途中で、Do you wish to run the custom code? [y/N] が表示されたら、y を押してEnterキーで入力してください(環境によるようです)。
GPUのメモリ(GPU RAM / VRAM)は7.7GBと、標準的なゲーミングPC2搭載されている8GB以下でも動きそうです。
Setting `pad_token_id` to `eos_token_id`:100257 for open-end generation.というワーニングが表示されますが、これは このあたりの 情報を見ながら実際の設定を作っていくと良さそうです。
GUIでチャットボットを試したい方は Instruct版を試してみよう!
時同じくして、アドボケーター仲間のDELLさんが Japanese Stable LM 2 Instruct 1.6B の Google Colab版コードを公開してくれています。
Gradioインタフェースで日本語チャットを楽しめます!
まとめ
以上、Stability AIが公開した最新の日本語大規模言語モデル「Japanese Stable LM 2 1.6B」をGoogle Colabのシークレット機能で短いコードを書いてみました。Google Colabでの環境も今回のシークレット機能の他にもTransoformersが標準搭載になったりしていますので、いきなりローカル環境で試すよりも良いことがいっぱいありそうですね!
AICU mediaでは日本語LLMについての実験的な話題も増やしていきたいと思います。ぜひフィードバックやシェア、X(Twitter)でのコメントなどいただければ幸いです。
腕だめしをしたいライターさんや学生インターンも引き続き募集中です。
Originally published at https://note.com on May 9, 2024.