「生成AI時代に つくる人をつくる」AICUの しらいはかせ です。
ご高評いただいております「画像生成AI Stable Diffusion スタートガイド」
(通称 #SD黄色本 )掲載の主要なプログラム(SBXL1, SBXL2)につきまして、編集部が本日、Google ColabでのAUTOMATIC1111において不具合を発見いたしましたので、本日、解説とともに修正を実施いたしました。
【現象1】SD1.5系でGradioURLが表示されない
p47 【Start Stable-Diffusion】のセルを実行時 WARNING[XFORMERS]: xFormers can’t load C++/CUDA extensions. xFormers was built for: PyTorch 2.2.1+cu121 with CUDA 1201 (you have 2.3.0+cu121) Python 3.10.13 (you have 3.10.12) Please reinstall xformers というエラーが出てURLも表示されず完了しません。
読者の方からも同様のご報告を頂いております(SBクリエイティブさんありがとうございます)。
【現象2】起動には成功するが画像生成に失敗する
「Generate」ボタンを押すと以下のようなエラー表示されます。
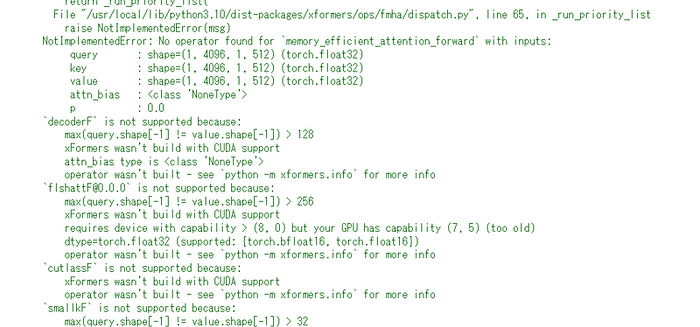
AUTOMATIC1111側にはこちらのエラーが表示されています

NotImplementedError: No operator found for `memory_efficient_attention_forward` with inputs:
query : shape=(1, 4096, 1, 512) (torch.float32)
key : shape=(1, 4096, 1, 512) (torch.float32)
value : shape=(1, 4096, 1, 512) (torch.float32)
attn_bias : <class 'NoneType'>
p : 0.0
`decoderF` is not supported because:
max(query.shape[-1] != value.shape[-1]) > 128
xFormers wasn't build with CUDA support
attn_bias type is <class 'NoneType'>
operator wasn't built - see `python -m xformers.info` for more info
`flshattF@0.0.0` is not supported because:
max(query.shape[-1] != value.shape[-1]) > 256
xFormers wasn't build with CUDA support
requires device with capability > (8, 0) but your GPU has capability (7, 5) (too old)
dtype=torch.float32 (supported: {torch.bfloat16, torch.float16})
operator wasn't built - see `python -m xformers.info` for more info
`cutlassF` is not supported because:
xFormers wasn't build with CUDA support
operator wasn't built - see `python -m xformers.info` for more info
`smallkF` is not supported because:
max(query.shape[-1] != value.shape[-1]) > 32
xFormers wasn't build with CUDA support
operator wasn't built - see `python -m xformers.info` for more info
unsupported embed per head: 512
ChatGPTによるログと日本語解説はこちら
https://chatgpt.com/share/41ae4cbb-74ce-4e72-8851-42d1698f8bf0
なお、xFormersとは、Facebook Research (Meta)がオープンソースソフトウェアとして公開しているPyTorchベースのライブラリで、Transformersの研究を加速するために開発されたものです。xFormersは、NVIDIAのGPUでのみ動作します。NVIDIAのGPUを演算基盤として動作させるためのCUDAやそのビルド時のバージョンをしっかり管理する必要があります。
https://github.com/facebookresearch/xformers
【関連】PyTorchとCUDAバージョンエラーの警告について
実はPyTorchとCUDAバージョンエラーの警告も出ています。
PyTorch 2.2.1+cu121 with CUDA 1201 (you have 2.3.0+cu121)
Python 3.10.13 (you have 3.10.12)
AUTOMATIC1111のインストールマニュアルによると
https://github.com/AUTOMATIC1111/stable-diffusion-webui
Install Python 3.10.6 (Newer version of Python does not support torch), checking “Add Python to PATH”.
Python 3.10.6をインストールし、”Add Python to PATH “をチェックする。
とありますが、実際にGoogle Colab上でデフォルトで動作しているPythonは現在、Python 3.10.12です(!python — version で確認できます)。
Python3.10.6が推奨なので、だいぶ後続のバージョンを使っていることになります。この問題はGoogle Colab上でのPythonのメジャーバージョンに関する問題で、関係はありますが、文末で解説します。
AICU版の原作となったTheLastBenさんのリポジトリでも同様の問題がレポートされています。
Xformers Google Colab ERROR · Issue #2836 · TheLastBen/fast-stable-diffusion
Getting Error in the last cell during the launch: WARNING[XFORMERS]: xFormers can’t load C++/CUDA extensions. xFormers…
Google Colabが xformers や JAX といった関連ライブラリを更新してしまうことが問題の根幹でもありますので不具合報告を Google Colab 側にも入れておきます。
Python and xformers version conflict · Issue #4590 · googlecolab/colabtools
Describe the current behavior I’m Google Colab Pro+ user and using TheLastBen’s Automatic1111 (A1111) frequently…
【解決】とりいそぎの回避方法
Start Stable-Diffusionの手前にセルを追加して、以下のコードを入れて実行してください。これで問題の xformersをアンインストールし、解決したバージョンの xformers を再インストールできます。
#@markdown ### xformers の再インストール(v20240522)
!python --version
!yes | pip uninstall xformers
!pip install xformers
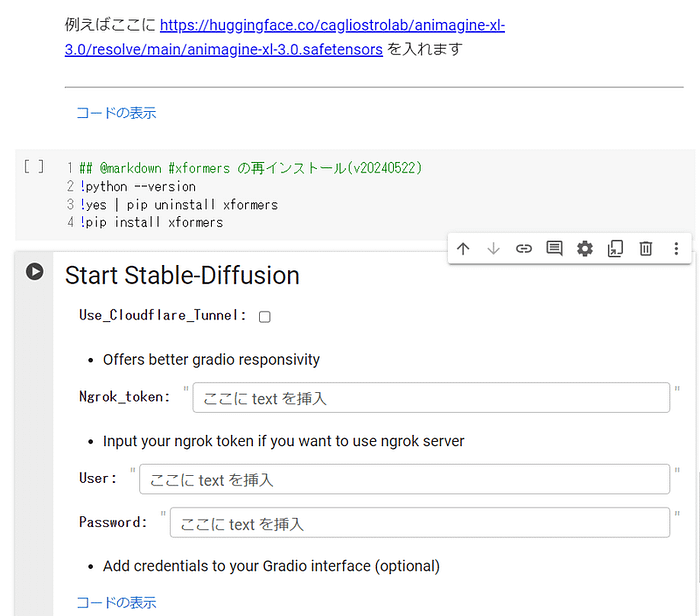
この「xformers 0.0.26.post1」がインストールされていれば、問題なく動作するはずです。
【補足】Google ColabのPythonはいつまで現行のバージョン3.10.xなのか
ところで、いい機会なので Google Colab上でのPythonはいつまで現行のバージョンなのか、調べてみました。実は2024年4月にPython自体のメジャーバージョンアップが予定されているようです。
https://colab.google/articles/py3.10
Colab Updated to Python 3.10 With the upgrade to Python 3.10, it brings Colab into alignment with the cadence of final…
Python 3.10 へのアップグレードにより、Colab はPython バージョンの最終的な定期的なバグ修正リリースのペースに合わせられます。 Python の次のバージョン (3.11) は、2024 年 4 月に最終的な定期バグ修正リリースが予定されています。
最終リリースとなる Python3.11.9 は2024年4月2日にリリースされているので、実はもういつ移行してもおかしくない時期なんですね…これはAUTOMATIC1111ユーザーにとってはたいへん重要なアップデートとなります。いきなり使えなくなるのは困るのでGoogle Colab上での切り替えも用意されると良いですね…。
Google Colab上での賢い方法を期待しつつ、さいごにPythonのメジャーバージョンのロードマップをチェックしておきましょう。
https://devguide.python.org/versions
The main branch is currently the future Python 3.13, and is the only branch that accepts new features. The latest…
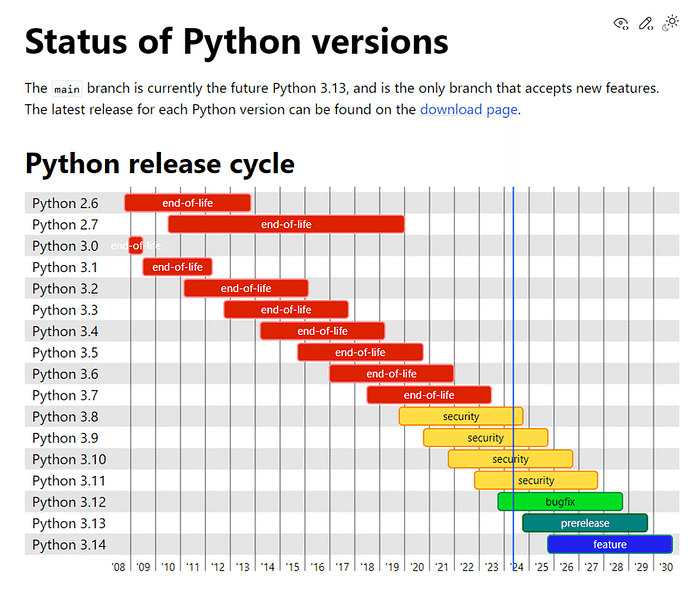
Python3.10は2026年中、Python3.11は2027年に終了(end-of-life ; EOL)が宣言されています。
AICU Inc.は生成AI時代のつくる人をつくるとともに、オープンソースソフトウェアや日本語コミュニティへの貢献を常に行っています。
書籍なのに最新のオープンソースソフトウェアがアップデートされる、
新感覚の画像生成AIの教科書「画像生成AI Stable Diffusion スタートガイド」の購入はこちらから! https://j.aicu.ai/SBXL

書籍[画像生成AI Stable Diffusionスタートガイド] – つくる人をつくる AICU Inc.
著者:AICU media、白井 暁彦 発売日:2024年3月29日(金) ISBN:978-4-8156-2456-9サイズ:B5判 ページ数:224定価:2,640円(本体2,400円+10%税) 画像生成AIの1つであるStable…
Originally published at https://note.com on May 22, 2024.