生成AIクリエイターユニオン『AICU: AI Creators Union』は、「つくる人をつくる」をビジョンに活動するアメリカのスタートアップ企業「AICU」社が「note」で提供するプロ生成AIクリエイター養成ユニオンです。このユニオンでは、画像生成AIやLLMなど、高速に進化する生成AIの最先端を学びながら、一緒に生成AIの価値を生む仲間を得ます。メンバーは、生成AIに関する最新の知識と技術を自分のペースと興味の深さで追い、それを社会に明確に伝えて価値を生む能力を養うことに焦点を置いています。 Google Colabで動くGPU不要な環境についても紹介しています。 AICU社のパートナーである生成AIトップの企業での技術と専門知識や情報にいち早く触れる機会を得られます。プロフェッショナルな環境で学び、実践的なライティング技術、PoC開発、コンテンツ作成のノウハウを習得しましょう。 プロのクリエイターを目指す学生さんや、個人ブログでの執筆を超え生成AIでの転職や起業を考えるプロフェッショナル志向の方々の参加を歓迎します。もちろん「これから勉強したい」という人々も歓迎です。
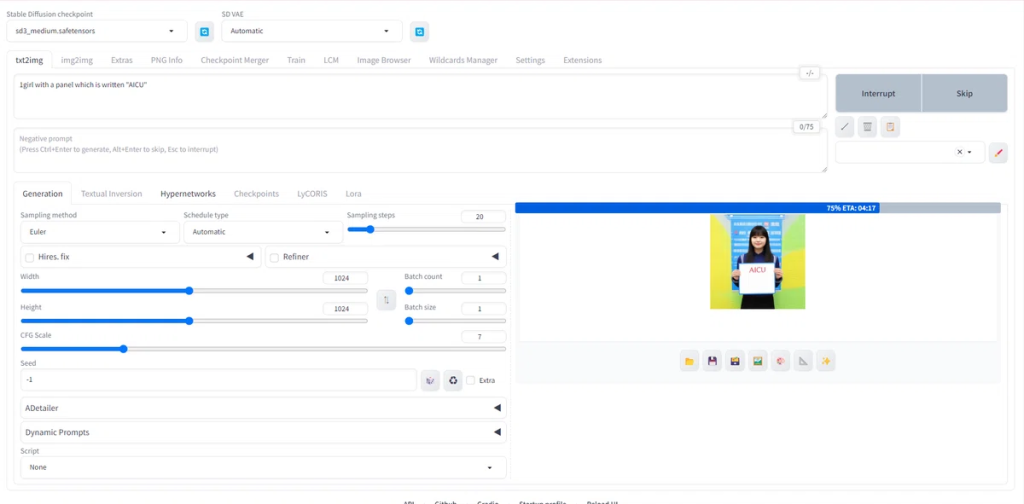
A bustling urban street scene with skyscrapers, busy pedestrians, and colorful street art. The atmosphere is lively and dynamic, with sunlight casting dramatic shadows. Negative prompt: Avoid elements like excessive clutter, overly dark shadows, or underexposed areas. Exclude dull or washed-out colors, empty or lifeless streets, graffiti with inappropriate content, and chaotic or confusing compositions. Steps: 20, Sampler: Euler, Schedule type: Automatic, CFG scale: 5, Seed: 1421671004, Size: 1344×768, Model hash: cc236278d2, Model: sd3_medium, Version: v1.10.0 Time taken: 16 min. 3.3 sec.
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
basicsr 1.4.2 requires lmdb, which is not installed.
gfpgan 1.3.8 requires lmdb, which is not installed.
clean-fid 0.1.31 requires requests==2.25.1, but you have requests 2.28.2 which is incompatible.
fastai 2.7.15 requires torch<2.4,>=1.10, but you have torch 2.4.0 which is incompatible.
torchaudio 2.3.1+cu121 requires torch==2.3.1, but you have torch 2.4.0 which is incompatible.
torchvision 0.18.1+cu121 requires torch==2.3.1, but you have torch 2.4.0 which is incompatible.
Successfully installed nvidia-cudnn-cu12-9.1.0.70 torch-2.4.0 triton-2.3.1 xformers-0.0.27.post1
Traceback (most recent call last):File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py", line 13, in <module>initialize.imports()File "/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/initialize.py", line 17, in importsimport pytorch_lightning # noqa: F401File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/init.py", line 34, in <module>from pytorch_lightning.callbacks import Callback # noqa: E402File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/callbacks/init.py", line 14, in <module>from pytorch_lightning.callbacks.callback import CallbackFile "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/callbacks/callback.py", line 25, in <module>from pytorch_lightning.utilities.types import STEP_OUTPUTFile "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/utilities/init.py", line 18, in <module>from pytorch_lightning.utilities.apply_func import move_data_to_device # noqa: F401File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/utilities/apply_func.py", line 29, in <module>from pytorch_lightning.utilities.imports import _compare_version, _TORCHTEXT_LEGACYFile "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/utilities/imports.py", line 153, in <module>_TORCHTEXT_LEGACY: bool = _TORCHTEXT_AVAILABLE and _compare_version("torchtext", operator.lt, "0.11.0")File "/usr/local/lib/python3.10/dist-packages/pytorch_lightning/utilities/imports.py", line 71, in _compare_versionpkg = importlib.import_module(package)File "/usr/lib/python3.10/importlib/init.py", line 126, in import_modulereturn _bootstrap._gcd_import(name[level:], package, level)File "/usr/local/lib/python3.10/dist-packages/torchtext/init.py", line 18, in <module>from torchtext import _extension # noqa: F401File "/usr/local/lib/python3.10/dist-packages/torchtext/_extension.py", line 64, in <module>_init_extension()File "/usr/local/lib/python3.10/dist-packages/torchtext/_extension.py", line 58, in _init_extension_load_lib("libtorchtext")File "/usr/local/lib/python3.10/dist-packages/torchtext/_extension.py", line 50, in _load_libtorch.ops.load_library(path)File "/usr/local/lib/python3.10/dist-packages/torch/_ops.py", line 1295, in load_libraryctypes.CDLL(path)File "/usr/lib/python3.10/ctypes/init.py", line 374, in initself._handle = _dlopen(self._name, mode)OSError: /usr/local/lib/python3.10/dist-packages/torchtext/lib/libtorchtext.so: undefined symbol: _ZN5torch3jit17parseSchemaOrNameERKSs
Stable Video 4D は、1つの目的の動画から、8 つの異なる角度/視点からの斬新な複数視点動画に変換します。
Stable Video 4D は、1回の推論で、8視点にわたる 5フレームを約40秒で生成します。
ユーザーはカメラアングルを指定して、特定のクリエイティブニーズに合わせて出力を調整できます。
現在研究段階にあるこのモデルは、ゲーム開発、動画編集、バーチャルリアリティにおける将来的な応用が期待されており、継続的な改善が進められています。Hugging Face で現在公開中です。
仕組み
ユーザーはまず、単一の動画をアップロードし、目的の3D カメラの姿勢を指定します。次に、Stable Video 4D は、指定されたカメラの視点に従って 8 つの斬新な視点動画を生成し、被写体の包括的で多角的な視点を提供します。生成された動画は、動画内の被写体の動的な 3D 表現を効率的に最適化するために使用できます。
Stable Video 4D は、既存の事例と比較して、より詳細で、入力動画に忠実で、フレームと視点間で一貫性のある斬新な視点動画を生成できます。
研究開発
Stable Video 4D は Hugging Face で公開されており、Stability AI 初の動画から動画への生成モデルであり、エキサイティングなマイルストーンとなっています。現在トレーニングに使用されている合成データセットを超えて、より幅広い実際の動画を処理できるように、モデルの改良と最適化に積極的に取り組んでいます。
![[ComfyMaster] ここからはじめる「ComfyUIマスターガイド」](https://ja.aicu.ai/wp-content/uploads/2025/03/rectangle_large_type_2_7940346ff4990532f281832d5a67a102-45.webp)