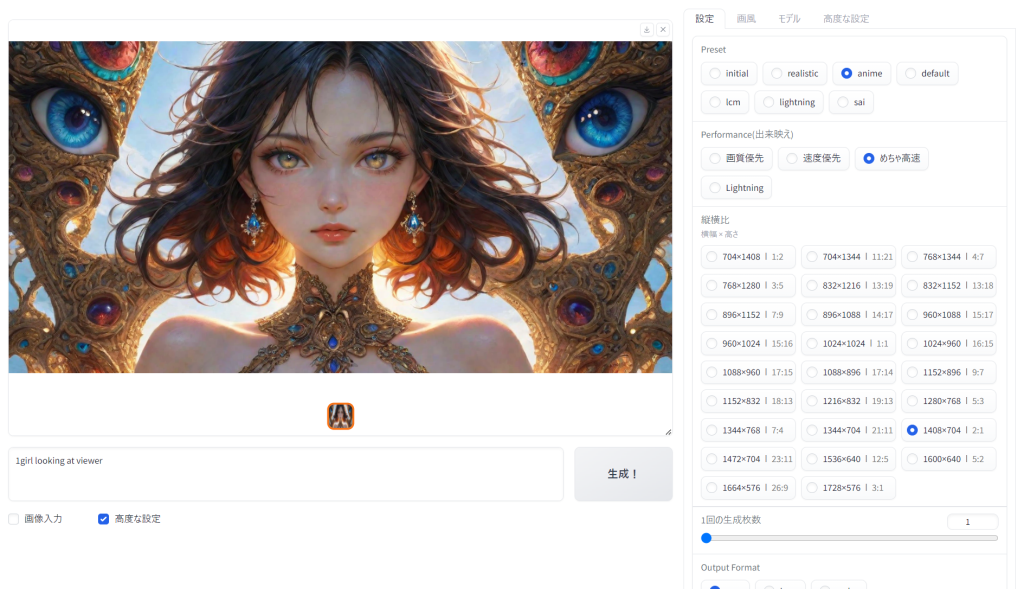
変更点 feat: ミラーサイトからの huggingface ファイルのダウンロードをサポート。 chore: インターポーザーを v3.1 から v4.0 に更新 by @mashb1t in #2717 feat: ページをリロードせずに UI を再接続するボタンを追加 by @mashb1t in #2727 feat: オプションのモデルVAE選択を追加 by @mashb1t in #2867 feat: ランダムスタイルを選択 by @mashb1t in #2855 feat: アニメを animaPencilXL_v100 から animaPencilXL_v310 に更新 by @mashb1t in #2454 refactor: 再接続ボタンのラベル名を変更 by @mashb1t in #2893 feat: 履歴ログに完全な生プロンプトを追加 by @docppp in #1920 修正: 正しい border radius css プロパティを使用するようにしました by @khanvilkarvishvesh in #2845 修正: HTMLヘッダでメタタグを閉じないようにした by @e52fa787 in #2740 機能: uov 画像アップロード時に画像を自動的に記述 by @mashb1t in #1938 nsfw 画像の検閲を設定とチェックボックスで追加 by @mashb1t in #958 feat: 手順を揃えるスケジューラーを追加 by @mashb1t in #2905 lora のインラインプロンプト参照をサポート by @cantor-set in #2323 feat: sgm_uniform (lcmと同じ)に基づくtcdサンプラーと離散蒸留tcdスケジューラの追加 by @mashb1t in #2907 feat: 4step LoRA に基づくパフォーマンス Hyper SD を追加 (@mashb1t 氏による) #2812 修正: HyperSDテスト用に残っていたコードを削除しました。 feature: nsfw 画像検閲のモデル管理を最適化 by @mashb1t in #2960 feat: プログレスバーの改善 by @mashb1t in #2962 feat: インラインローラの最適化 by @mashb1t in #2967 feat: コードの所有者を @lllyasviel から @mashb1t に変更 by @mashb1t in #2948 feat: 有効なインラインローラのみを使用し、サブフォルダをサポート by @mashb1t in #2968 feature: イメージのサイズと比率を読み取り、推奨サイズを与える by @xhoxye in #2971 feature: ghcr.io 用コンテナイメージのビルドとプッシュ、docker.md の更新、その他関連する修正 by @xynydev in #2805。 利用可能なイメージを見る feat: 行末のデフォルト設定を調整 by @mashb1t in #2991 feat: image size description の翻訳を追加しました。 feat: ‘CFG Mimicking from TSNR’ の値をプリセットから読み込む by @Alexdnk in #2990 feat: ブラシのカラーピッカーを追加 by @mashb1t in #2997 feat: ほとんどの画像入力フィールドからラベルを削除 by @mashb1t in #2998 feat: クリップスキップ処理を追加 by @mashb1t in #2999 feat: UI設定をよりコンパクトに by @Alexdnk and @mashb1t in #2590
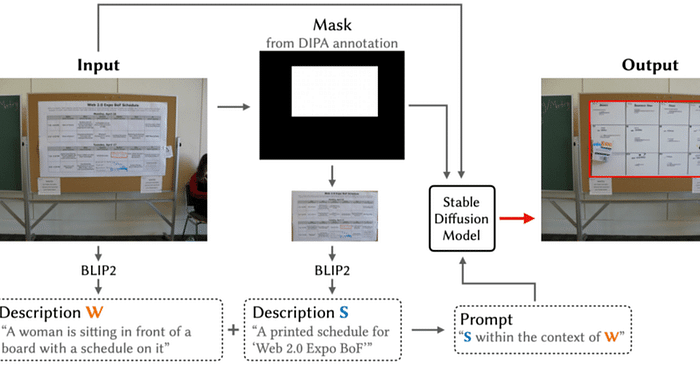
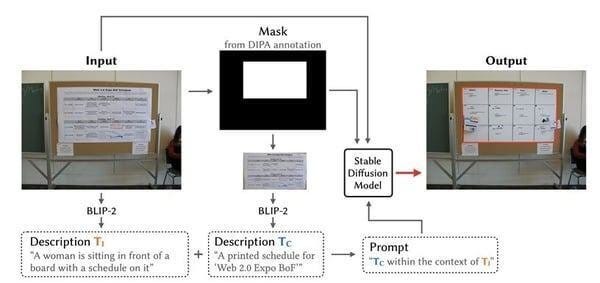
Examining Human Perception of Generative Content Replacement in Image Privacy Protection | Proceedings of the CHI Conference on Human Factors in Computing Systems https://dl.acm.org/doi/10.1145/3613904.3642103
p47 【Start Stable-Diffusion】のセルを実行時 WARNING[XFORMERS]: xFormers can’t load C++/CUDA extensions. xFormers was built for: PyTorch 2.2.1+cu121 with CUDA 1201 (you have 2.3.0+cu121) Python 3.10.13 (you have 3.10.12) Please reinstall xformers というエラーが出てURLも表示されず完了しません。
読者の方からも同様のご報告を頂いております(SBクリエイティブさんありがとうございます)。
【現象2】起動には成功するが画像生成に失敗する
「Generate」ボタンを押すと以下のようなエラー表示されます。
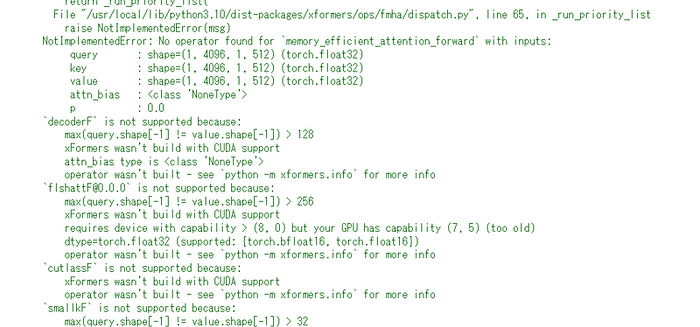
AUTOMATIC1111側にはこちらのエラーが表示されています
NotImplementedError: No operator found for `memory_efficient_attention_forward` with inputs: query : shape=(1, 4096, 1, 512) (torch.float32) key : shape=(1, 4096, 1, 512) (torch.float32) value : shape=(1, 4096, 1, 512) (torch.float32) attn_bias : <class 'NoneType'> p : 0.0 `decoderF` is not supported because: max(query.shape[-1] != value.shape[-1]) > 128 xFormers wasn't build with CUDA support attn_bias type is <class 'NoneType'> operator wasn't built - see `python -m xformers.info` for more info `flshattF@0.0.0` is not supported because: max(query.shape[-1] != value.shape[-1]) > 256 xFormers wasn't build with CUDA support requires device with capability > (8, 0) but your GPU has capability (7, 5) (too old) dtype=torch.float32 (supported: {torch.bfloat16, torch.float16}) operator wasn't built - see `python -m xformers.info` for more info `cutlassF` is not supported because: xFormers wasn't build with CUDA support operator wasn't built - see `python -m xformers.info` for more info `smallkF` is not supported because: max(query.shape[-1] != value.shape[-1]) > 32 xFormers wasn't build with CUDA support operator wasn't built - see `python -m xformers.info` for more info unsupported embed per head: 512
なお、xFormersとは、Facebook Research (Meta)がオープンソースソフトウェアとして公開しているPyTorchベースのライブラリで、Transformersの研究を加速するために開発されたものです。xFormersは、NVIDIAのGPUでのみ動作します。NVIDIAのGPUを演算基盤として動作させるためのCUDAやそのビルド時のバージョンをしっかり管理する必要があります。 https://github.com/facebookresearch/xformers
【関連】PyTorchとCUDAバージョンエラーの警告について
実はPyTorchとCUDAバージョンエラーの警告も出ています。
PyTorch 2.2.1+cu121 with CUDA 1201 (you have 2.3.0+cu121) Python 3.10.13 (you have 3.10.12)
Install Python 3.10.6 (Newer version of Python does not support torch), checking “Add Python to PATH”. Python 3.10.6をインストールし、”Add Python to PATH “をチェックする。
とありますが、実際にGoogle Colab上でデフォルトで動作しているPythonは現在、Python 3.10.12です(!python — version で確認できます)。 Python3.10.6が推奨なので、だいぶ後続のバージョンを使っていることになります。この問題はGoogle Colab上でのPythonのメジャーバージョンに関する問題で、関係はありますが、文末で解説します。
![[速報]AICU CEO白井が「ChatGPTとStable Diffusion丸わかりナイト」に登壇いたしました](https://ja.aicu.ai/wp-content/uploads/2024/06/image-2-1.jpeg)