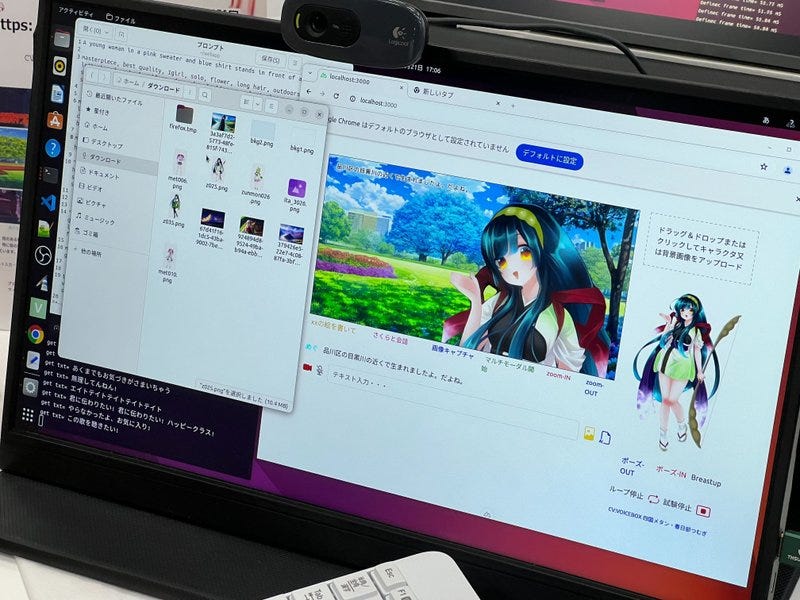
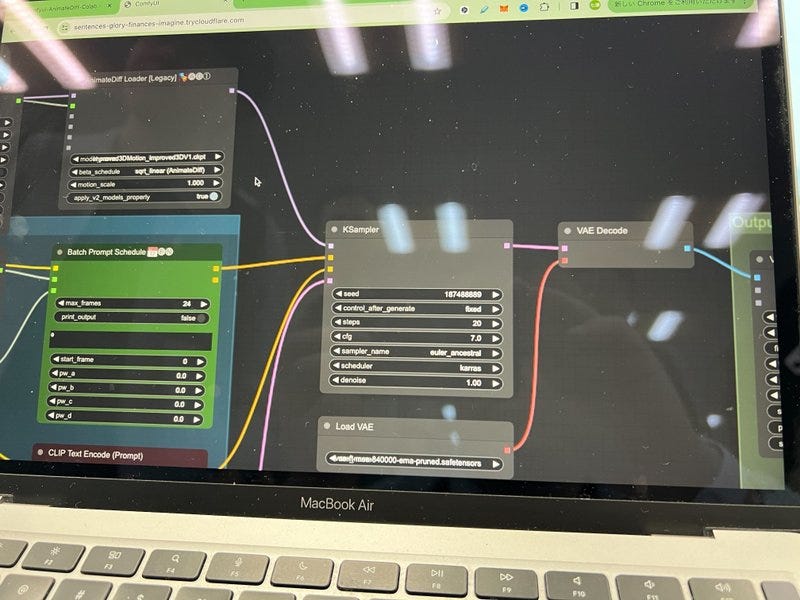
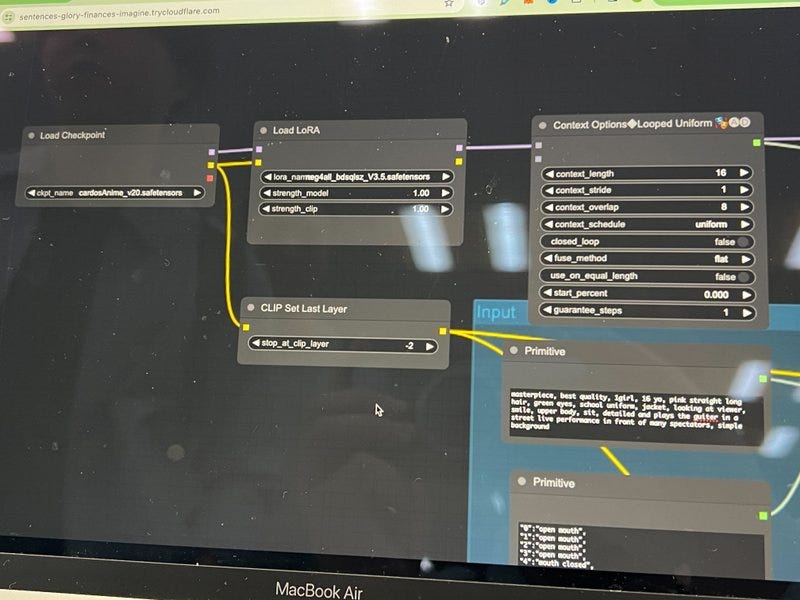
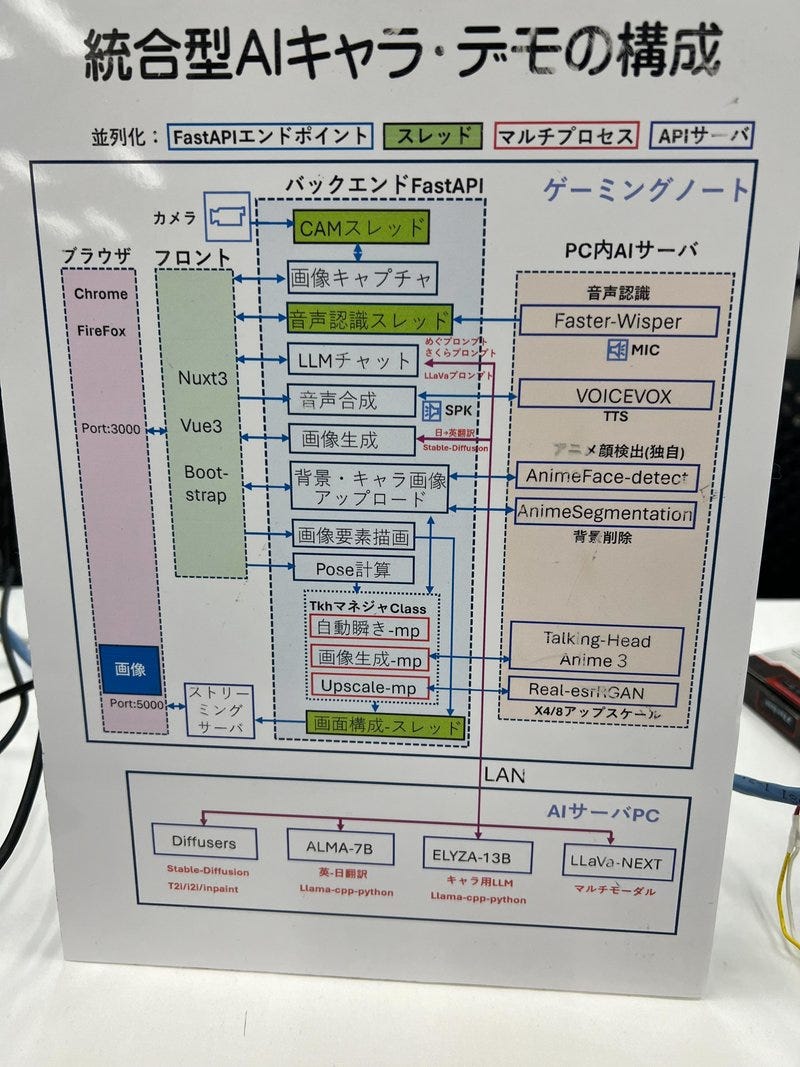
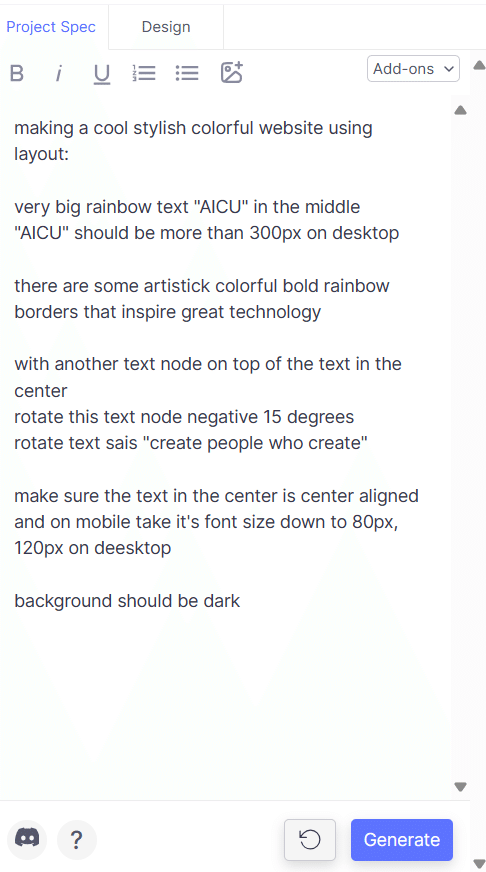
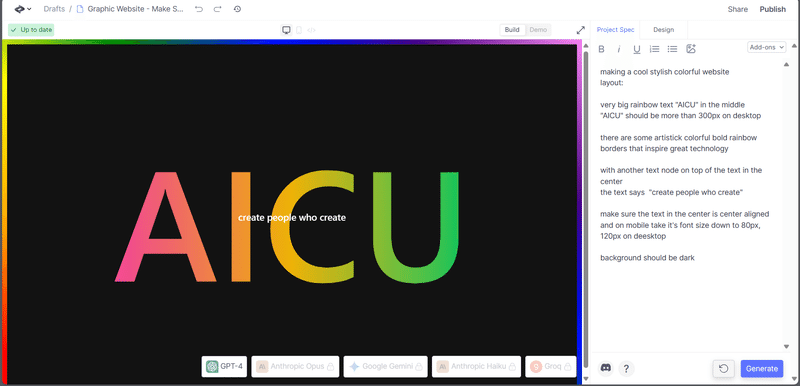
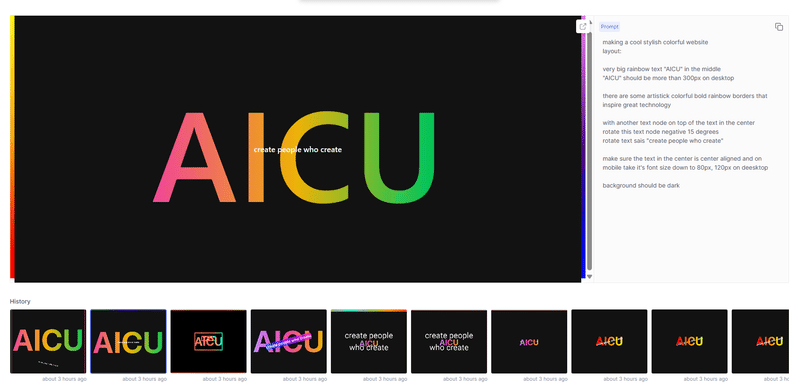
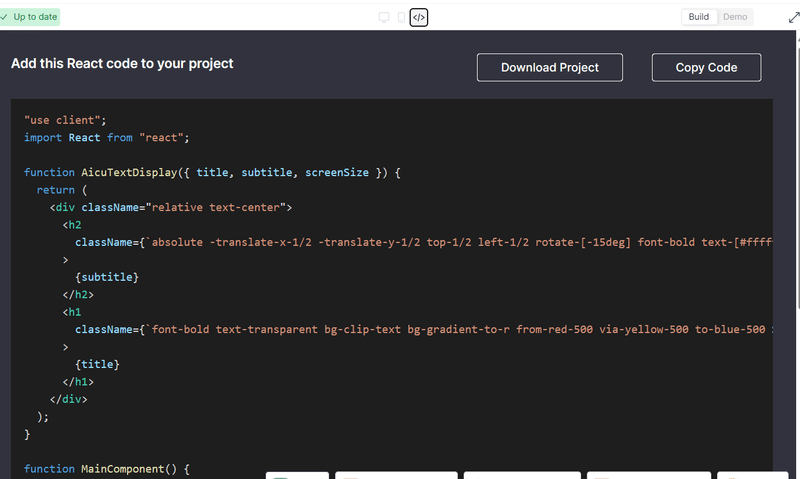
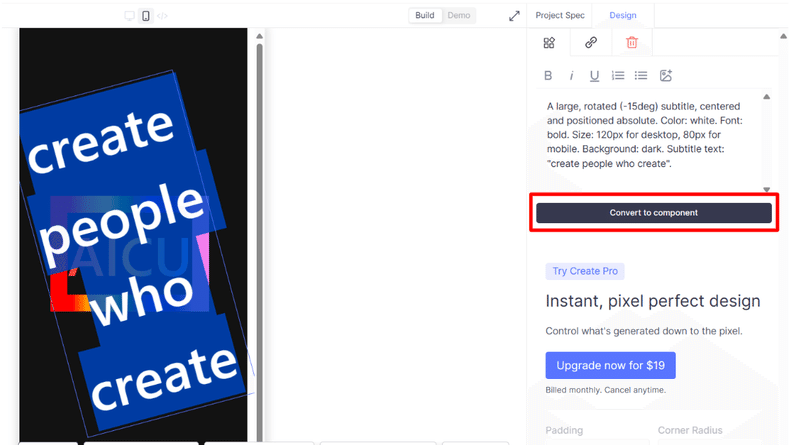
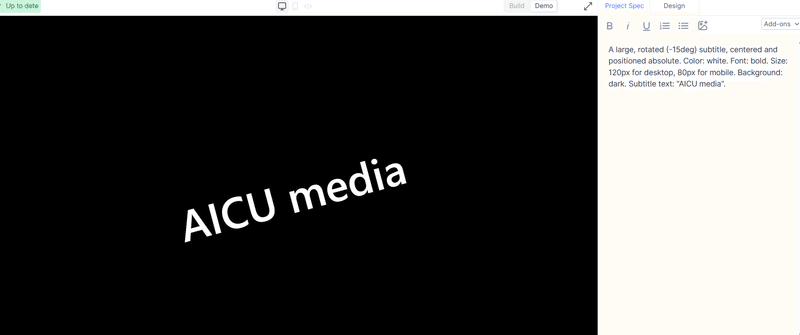
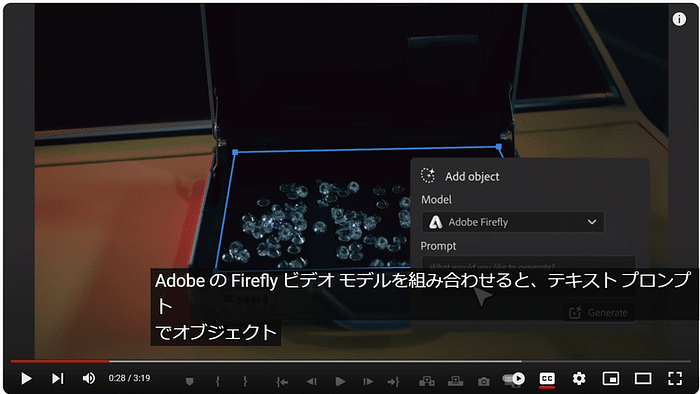
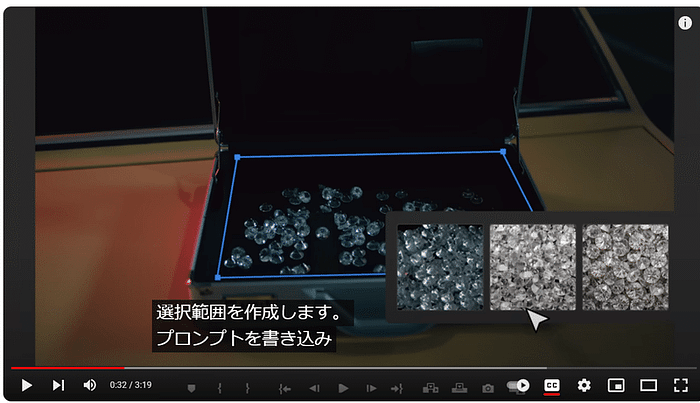
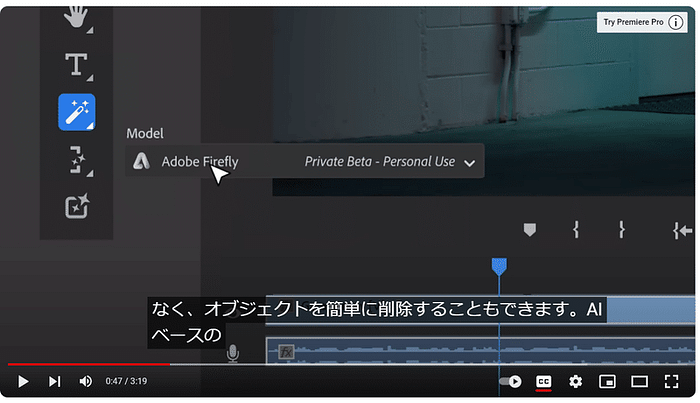
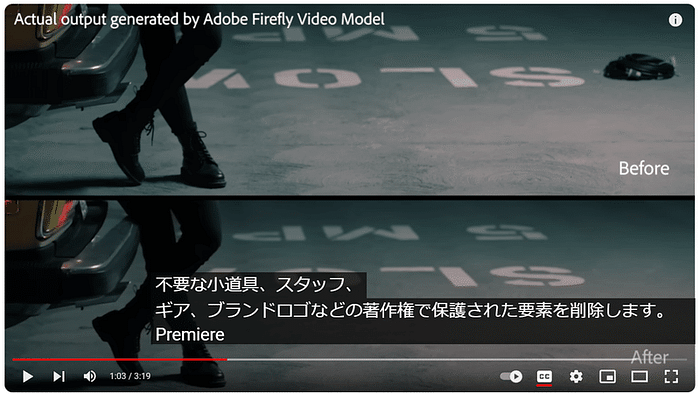
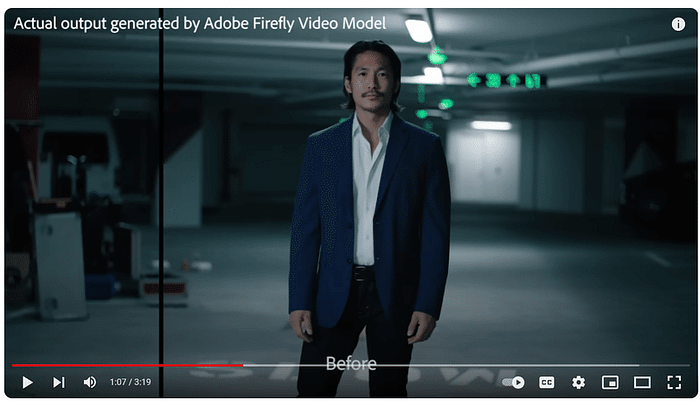
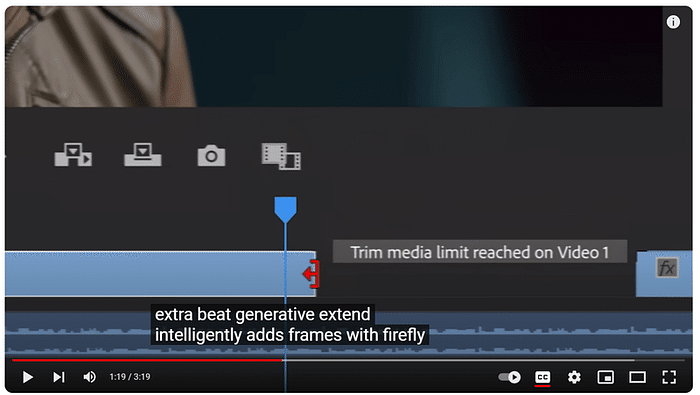
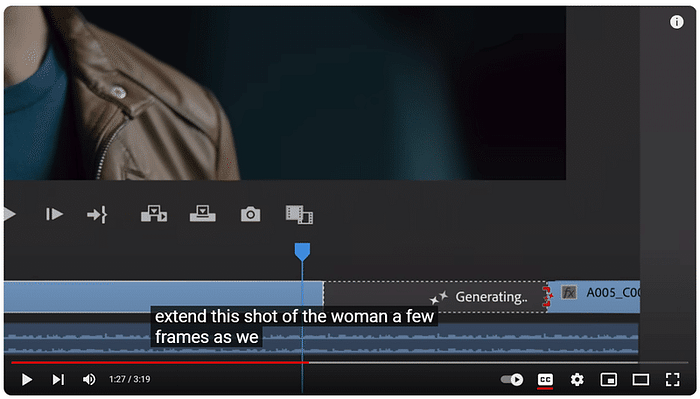
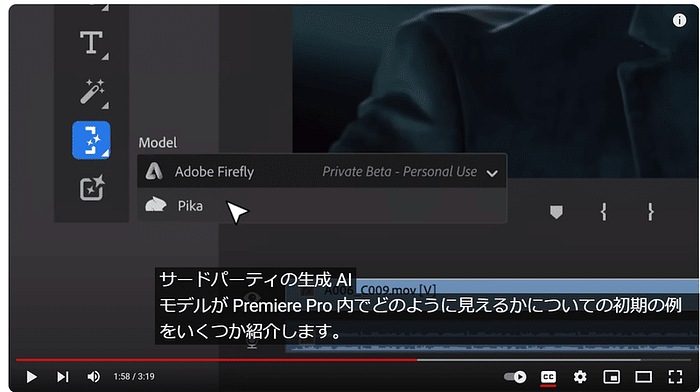
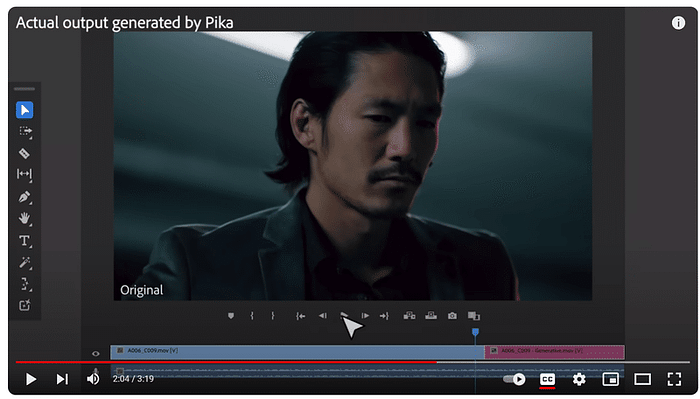
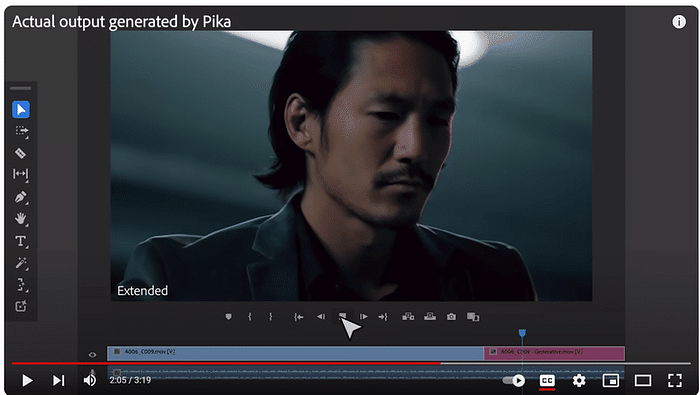
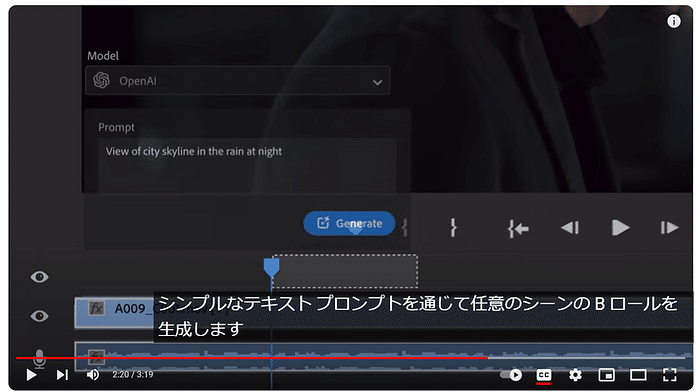
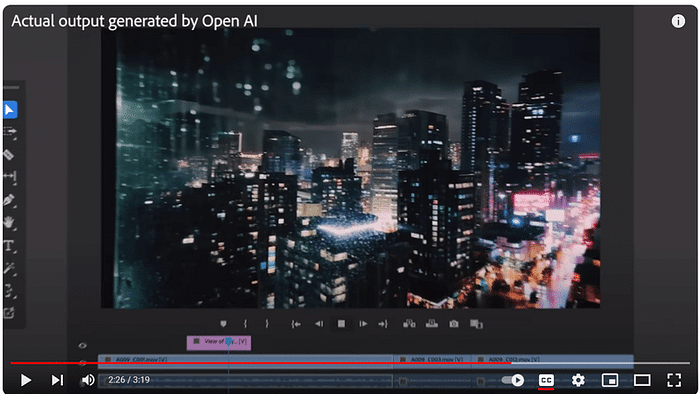
このセッションでは、クリエイティブ産業におけるAIの変革的役割を探ります。AIは人間の創造性を補完し、新たな可能性のためのコラボレーションを促進することができるのか?著作権や偏見といった倫理的な問題にも触れ、責任あるAIの利用を提唱します。AIと人間の創造性が相乗効果を発揮し、イノベーションを生み出す未来を描くには? [スピーカー] Matty Shimura (Executive Producer of AI Film and TV, Civitai) [M] 三浦 謙太郎(創業者兼 CEO, DouZen, Inc)
2016年にドイツのダルムシュタット工科大学とインテルラボの科学者によって開発された「Playing for Data: Ground Truth from Computer Games」という研究で、「Grand Theft Auto V」のオープンワールドでのプレイ時の視覚情報をデータセットとして利用しています。
Playing for Data: Ground Truth from Computer Games
データ データセットは、便宜上10分割された24966の高密度にラベル付けされたフレームで構成されている。クラスラベルはCamVidとCityScapesデータセットと互換性がある。ラベルマップを読み込むためのサンプルコードと、トレーニング/検証/テストセットへの分割をここに提供します。ラベルマップの小さなセット(60フレーム)は、対応する画像と解像度が異なることに注意してください(Dequan Wang氏とHoang An Le氏の指摘に感謝します)。また、このデータは研究・教育目的にのみ使用されることに注意してください。
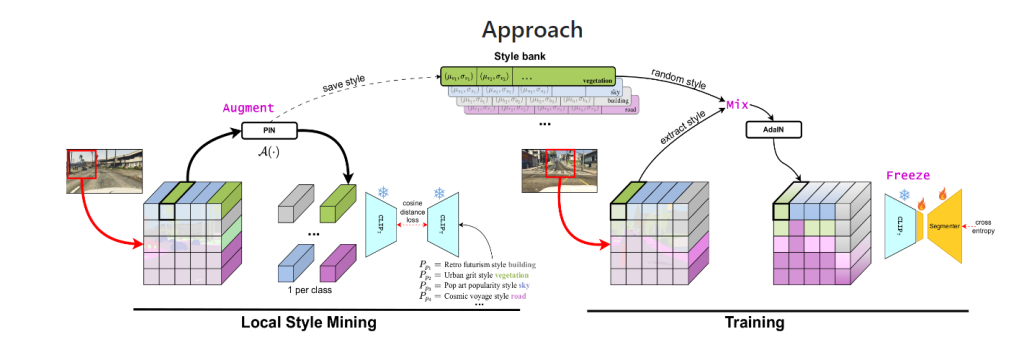
さてプロジェクト「FAMix」(公開された論文タイトルは:ASimple Recipe for Language-guided Domain Generalized Segmentation/言語ガイド付きドメイン汎化セグメンテーションの簡単なレシピ)はセマンティックセグメンテーションのためのドメイン汎化(DGSS)をシンプルな材料の組み合わせによるDGSSの効果的なレシピとして提案しています。上記で紹介したデータセットに加え、Stable Diffusionの内部でも使われている言語と画像のマルチモーダル基盤モデル「CLIP」を使用し、最小限の微調整によるCLIP本来のロバスト性の維持、ii) 言語駆動型の局所的スタイル拡張、iii) 学習中にソーススタイルと拡張スタイルを局所的に混合することによるランダム化、そしてImageNetとの比較も行っています。分類、領域分割といったタスクに状況説明のような言語での説明ができることが新たな安全性を生み出す可能性もありますね。
プロンプト「masterpiece, best quality, face focus,1girl, lip, red lip, white skin」(ライティング指定なし) ネガティブプロンプト「worst quality, best quality, nomal quality, bad anatomy, bad hands」
プロンプト「masterpiece, best quality,cinematic lighting, professional lighting, face focus,1girl, lip, red lip, white skin」 ネガティブプロンプト「worst quality, best quality, nomal quality, bad anatomy, bad hands」
モデルや全体的な雰囲気の深み、重厚感や瑞々しさが全く違うことがわかるでしょうか。
またここに「intricate composition」(直訳すると『複雑な構図』)を追加すると、さらにリアルな質感を演出することができます。これは AICU media 編集部の知山が ChatGPT にプロンプトを考えてもらっている時に発見したプロンプトなので、他には出回っていないレア情報だと思われます。皆さんぜひ試してみてください!
プロンプト「masterpiece, best quality,cinematic lighting,professional lighting, intricate composition, face focus,1girl, dinner, pink lip, dinner,wine,smiling, black formal dress,long sleeves,sophisticated restaurant」 ネガティブプロンプト「worst quality, best quality, nomal quality, bad anatomy, bad hands」
飲料とドラマ
プロンプト「masterpiece, best quality, cinematic lighting, professional lighting, intricate composition, face focus,1girl, drinking beer, can, at home, night」 ネガティブプロンプト「worst quality, best quality, normal quality, bad anatomy, bad hands」
深みのある大人っぽい画像が生成できました!
深みのある大人っぽい画像が生成できました! 口元が気に入らないときは、image to image (img2img)でインペイントします。ついでにビールではなくジュースに置き換えてみます。
プロンプト「masterpiece, best quality, cinematic lighting, intricate composition, looking at viewer, 2girls, kissing cheek, whispering, index finger to index finger raised, looking at another, earrings, short blonde hair, eyewear, purple beret , summer muffler, green brown contact lens, catch light on the eyes, pink lips, indigo fingernails, <BREAK>looking at viewer, earrings, indigo short bob cut, round glasses, pink beret , blue brown contact lens, catch light on the eyes, pink lips, indigo fingernails」
また「BREAK」という大文字の単語を挿入することで、それ以前のトークンというプロンプトのまとまりを打ち切ることができ、BREAK以降のプロンプトが反映されやすくなります。詳しくは2024年3月に発売開始している書籍「画像生成 AI Stable Diffusion スタートガイド」で学ぶことができます。レベルアップしたい方は要チェックです!