

つくる人をつくる!AICU media の 知山ことねです。
昨日の記事「 VRoid Studio を使ってキャラクター LoRA を作ろう! 」が好評で、LoRA の制作に興味を持っている方からの「ぜひやってみたい!」という声を聴くことができました。
ところでこちら、画像生成AI「Stable Diffusion」の一大ブームを予言した深津貴之さんのつぶやきです。
▶世界変革の前夜は思ったより静か|深津 貴之 (fladdict) https://note.com/fladdict/n/n13c1413c40de https://note.com/aicu/n/n9d5cf46761b7 @fladdict
子供の頃の絵って魅力的ですよね。Soraが正式リリースされるのはまだわかりませんが、うかうかしていられませんね!
子供ゴコロあふれる「真の芸術」を爆発させていきましょう。
今回は、画像生成 AI でたびたび話題になる「 下手な子供の絵を生成する AI」、命名「描画タイムマシン」を Stable Diffusion の LoRA 学習を利用して作っていきます!
美と知能を超え、人間性を爆発させていきましょう。
Google Colabだけで作る描画タイムマシン
描画タイムマシンは学習元の画像データと Google Colab だけで完成するので、皆さんもぜひ、自分の幼少期の絵やお子さんの絵で一緒に作ってみてください。
用意するもの:小学校時代の黒歴史

まずは学習元の画像、データセットを用意します。
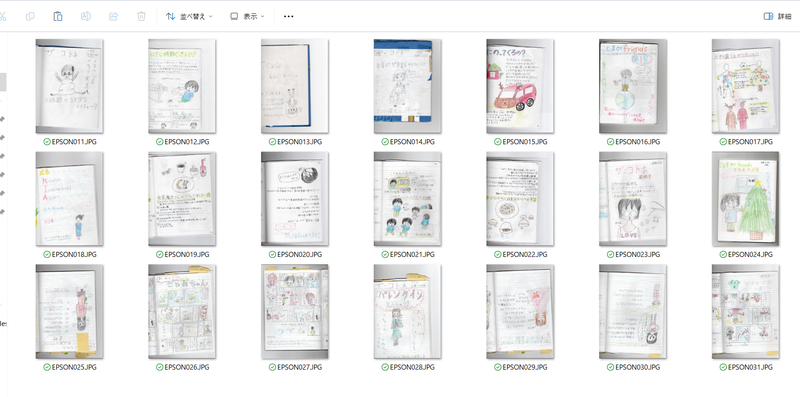
今回は、この原稿を書いている私、知山ことねが小学生の時に自由帳に描いていた 直筆雑誌「ザ・コトネ」「ことまが friends」 を用意しました。

この色鉛筆の質感と歪んだデッサンが小学生らしいですね。
これらのページをスキャンして、画像データとして PC に取り込みます。
学習には15~40枚ほどの画像を用意することをおすすめしますので、1枚の絵をそのまま学習したい場合は、絵を最低7,8枚ほど用意しましょう(後述しますが、あとで左右反転コピーを行って枚数を増やすことができます)。
今回は1枚の紙に複数イラストが描かれているため、貴重なサンプルとして切り取ってデータセットを増やしていきます。雑誌の中のイラストを多く含んだ箇所20ページほどをスキャンしました。

PC に取り込んだら、画像をそれぞれトリミングしていきます。今回は LoRAを扱いやすい Stable Diffusion (SD1.5) で学習を行うので、Photoshop 等を使い 512×512 px の正方形に画像を切り取っていきます。これを正則画像化といいます。

またこのままではノートの罫線や文字、透けている裏の紙の内容などのノイズも学習されてしまうので、それらの不要な部分は塗りつぶして消去し、画像全体のコントラストを上げるなどの色調補正も行いました。
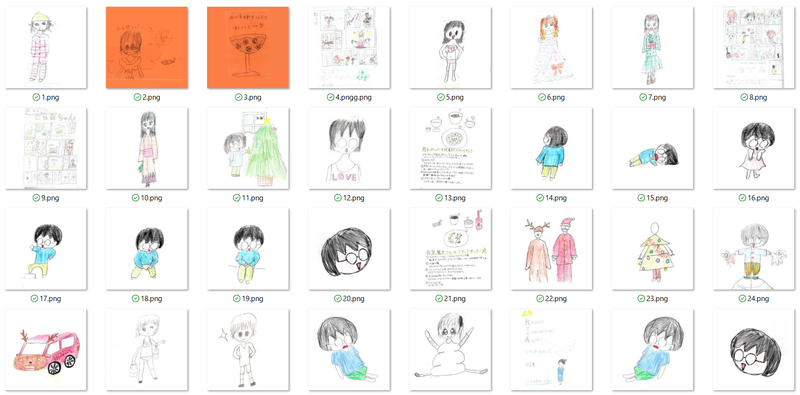
これをイラストの枚数分繰り返し、正則画像化済みの画像のデータセットを作りました。
またこの時に、用意できた画像の枚数が少ない場合や、画像の左右のバランスが望まない崩れかたをしている場合(左向きの顔が多い、など)は、左右反転したコピーPhotoshop等で作成し、保存しましょう。
また、LoRA を作ったことがある人ならご存じかと思いますが、学習時に画像をセットにして学習を行うため、画像枚数を2の倍数、具体的には 「2,4,…で割り切れる枚数」に揃えましょう。今回は32枚にしています。
学習
データセットが用意できたら、フォルダにまとめて他の LoRA と同じように学習を行います。もちろんローカル環境でも Colab でも可能ですが、初めて LoRA を制作する方は khoya-trainer の Colab notebook をおすすめします。
これは kohya-ss さん ( https://github.com/kohya-ss ) が制作した sd-scripts ( https://github.com/kohya-ss/sd-scripts?tab=readme-ov-file ) を Linaqruf ( https://github.com/Linaqruf ) さんが Colab notebook で使用できるようにしたものです。
編集した画像のzipファイルをドライブにアップロードし、手順に沿ってパスや LoRA のファイル名などを入力して実行すると学習された LoRA を制作することができます。
また今回は2次元のイラストを学習しますが、アニメ系の絵柄には寄せたくないので、2次元イラスト LoRA 学習定番の AnyLoRA などのアニメ系モデルではなく、Stable-Diffusion-v1–5 を使用して学習しました。
詳しい学習の流れはいずれ日本語の解説版を作って公開しようと思います。
(AICU mediaメンバーシップ掲示板でリクエストいただけるとプライオリティが上がるかもしれません…!)
完成!
Colab の実行が完了したら終了です!完成した LoRA で画像を生成してみましょう!
モデル v1–5-pruned-emaonly





鉛筆のストロークや雑な色塗り、斜めに歪んだデッサンを再現することができました!Stable Diffusionおそるべし底力。
大人になってから子供っぽい絵を描くことはなかなか難しいので、過去の自分とコラボレーションできる感覚は楽しいです。また画像だけでなく動画の素材に使う、さらに「不可能な動画」を製作できる可能性があります。
ファミリーカーむけの広告動画などにも需要がありそうですね。
これを使ったファンシーイラストやキャラクターデザインの探求にも使えそうです。ガチな産業向けの用途だけでなく、「子供の絵あるある~!」と誰かにシェアしたくなるような画像が生成できるので、皆さん試してみてください!
※LoRAを生成するときは本人やお子さんの許諾をもって実施してくださいね!
面白い作品ができたら、ぜひこちらのメンバーシップ掲示板でご共有ください~!
メンバーオンリー画像投稿コーナー
Stable Diffusion — ControlNet入門はこちらから
img2img 入門シリーズはこちらから。
※本ブログは発売予定のAICU media新刊書籍に収録される予定です。期間限定で先行公開中しています。
メンバー向けには先行してメンバーシップ版をお届けします
Stable Diffusionをお手軽に、しかもめっちゃ丁寧に学べてしまう情報をシリーズでお送りします。
メンバーは価値あるソースコードの入手や質問、依頼ができますので、お気軽にご参加いただければ幸いです!
この下にGoogle Colabで動作する「AUTOMATIC1111/Stable Diffusion WebUI」へのリンクを紹介しています。
メンバーシップ向けサポート掲示板はこちら!応援よろしくお願いします!
Originally published at https://note.com on February 28, 2024.