
2023年11月21日、StabilityAI社は画像から動画を生成する技術「Stable Video Diffusion」(SVD)を公開しました。
研究者の方はGitHubリポジトリで公開されたコードを試すことができます。ローカルでモデルを実行するために必要なウェイトは、HuggingFaceで公開されています(注意:40GBのVRAMが必要です)。
さらにStable Video Diffusion (SVD) を使って画像から動画へウェブインタフェースも近日公開予定とのこと。キャンセル待ちリストが公開されています。
stable-video-diffusion公式アナウンス
https://stability.ai/news/stable-video-diffusion-open-ai-video-model
日本語アナウンス
https://ja.stability.ai/blog/stable-video-diffusion
ウェイティングリスト
研究論文
「Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets」(21 Nov ,2023)
安定した映像拡散: 潜在的映像拡散モデルの大規模データセットへの拡張
高解像度で最先端のテキストから動画、画像から動画生成のための潜在動画拡散モデル、Stable Video Diffusionを紹介する。近年、2次元画像合成のために学習された潜在拡散モデルは、時間レイヤーを挿入し、小規模で高品質なビデオデータセット上で微調整することで、生成的なビデオモデルへと変化している。しかし、文献に記載されている学習方法は様々であり、ビデオデータをキュレーションするための統一的な戦略について、この分野はまだ合意されていない。本論文では、動画LDMの学習を成功させるための3つの異なる段階を特定し、テキストから画像への事前学習、動画の事前学習、高品質動画の微調整の評価を行った。
Translated from the original paper
Github: https://github.com/Stability-AI/generative-models
HuggingFace
https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
Stable Video Diffusion Image-to-Video モデルカードより
Stable Video Diffusion (SVD) Image-to-Video は、静止画像を条件フレームとして取り込み、そこから動画を生成する拡散モデルです。
モデル詳細
(SVD)Image-to-Videoは、画像コンディショニングから短いビデオクリップを生成するようにトレーニングされた潜在拡散モデルです。このモデルは、 SVD Image-to-Video[14フレーム]から微調整された、同じサイズのコンテキスト・フレームが与えられたときに、解像度576×1024の25フレームを生成するように訓練されています。また、広く使われている f8-デコーダを時間的整合性のために微調整した。便宜上、標準的な フレーム単位のデコーダのモデル も提供されています。
研究目的であれば、Generative-modelsのGithubリポジトリリポジトリ: https://github.com/Stability-AI/generative-models
最も一般的な拡散フレームワーク(学習と推論の両方)が実装されています。
論文: https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
評価
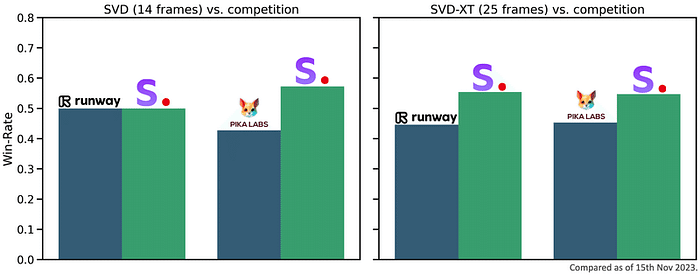
比較チャートは、GEN-2やPikaLabsに対するSVD-Image-to-Videoのユーザー嗜好を評価したものです。SVD-Image-to-Videoは、ビデオの品質という点で、人間に好まれています。ユーザー調査の詳細については、研究論文を参照してください。
用途:直接利用
このモデルは研究目的でのみ使用されます。想定される研究分野や課題は以下の通りです。
・生成モデルの研究
・有害なコンテンツを生成する可能性のあるモデルの安全な展開
・生成モデルの限界とバイアスの調査と理解
・芸術作品の生成と、デザインやその他の芸術的プロセスにおける使用
・教育的または創造的なツールへの応用
除外される用途を以下に示します
使用の範囲外
このモデルは、人物や出来事の事実または真実の表現となるように訓練されていないため、そのようなコンテンツを生成するためにモデルを使用することは、このモデルの能力の範囲外です。またこのモデルをStability AI の 利用規定 に違反するような方法で使用しないでください。
制限とバイアス
制限事項
・生成される動画はかなり短く(4秒未満)、モデルは完全なフォトリアリズムを達成しません。
・モデルは動きのないビデオや、非常に遅いカメラパンを生成することがあります。
・モデルはテキストで制御することができません。
・モデルは読みやすいテキスト(legible text)をレンダリングできません。
・顔や人物全般が適切に生成されないことがあります。
・モデルの自動エンコード部分は非可逆です。
推奨事項
このモデルは研究目的のみを意図しています。
モデルを使い始めるには
https://github.com/Stability-AI/generative-models をチェックしてください。
最新の進歩を取り入れたモデルのアップデートに意欲的に取り組み、皆さんのフィードバックを取り入れるよう努力していますが、現段階では、このモデルは実世界や商業的な応用を意図したものではないことを強調しておきます。安全性と品質に関する皆様の洞察とフィードバックは、最終的な商業リリースに向けてこのモデルを改良する上で極めて重要です。
StabilityAI社のリリースメッセージより翻訳
AICU media のコメント
StableDiffusionを2022年8月に公開してから14カ月。ついにStabilityAIがAI動画生成の大きな一歩となる「SVD Image-to-Video」をオープンに公開しました。画像を入力すると動画が生成されるDiffusionモデルのようです。フレーム間の安定性も高いようです。論文も30ページの超大作なので今後のこの分野における革新の一歩になることは間違いありません。今後も注目していきます。
Originally published at https://note.com on November 22, 2023.